How To Use LLMs: Summarize Long Documents
This article gives a step-by-step solution to summarizing really long documents using Generative AI and Large Language Models.
Join the DZone community and get the full member experience.
Join For FreeOne of the tasks Generative AI models are good at is summarizing texts. However, if you want to summarize a text, you need the whole text to fit in the context window, plus the command to summarize it. The following is an example prompt (you can test it yourself using the Google Colab notebook for this article):
Write a concise summary of the following text:
The Turing test, originally called the imitation game by Alan Turing in 1950, is a test of a machine's ability to exhibit intelligent behaviour equivalent to, or indistinguishable from, that of a human. Turing proposed that a human evaluator would judge natural language conversations between a human and a machine designed to generate human-like responses. The evaluator would be aware that one of the two partners in conversation was a machine, and all participants would be separated from one another. The conversation would be limited to a text-only channel, such as a computer keyboard and screen, so the result would not depend on the machine's ability to render words as speech. If the evaluator could not reliably tell the machine from the human, the machine would be said to have passed the test. The test results would not depend on the machine's ability to give correct answers to questions, only on how closely its answers resembled those a human would give. Since the Turing test is a test of indistinguishability in performance capacity, the verbal version generalizes naturally to all of human performance capacity, verbal as well as nonverbal (robotic).
Summary: 
This might get tricky if the text to summarize is too long. LLMs with very large window contexts exist:
- GPT-4 has a variant with a context window of 32k tokens.
- Claude 3 Opus has a context window of 200k tokens.
- Gemini 1.5 Pro can have a context window of up to 1 million tokens.
However, sometimes using an LLM with such a large context window is off the table. There are many factors that can make this the case:
- Those models might be too expensive.
- Models sometimes have a hard time using all the information in very long prompts.
- All the models with large context windows might be off the table because of restrictions like only being able to use open-source models.
- Your text might be longer than all available models (yes even with 1M context windows).
Luckily, a technique exists that can get an LLM to summarize a document longer than its context window size. The technique is called MapReduce. It’s based on dividing the text into a collection of smaller texts that do fit in the context window and then summarizing each part separately. The steps to perform a MapReduce summary are the following (Again, you can execute and see for yourself all the processes in the Google Colab notebook for this article):
- First, the long document is divided into chunks using a text splitter. The strategy we use to divide the text can be different depending on the type of document.
- If the text has sections and all sections are smaller than the context window, we could divide it by those sections.
- If the text has no clear sections or the sections are too large, the text can be divided into equal-sized chunks character-wise. This last approach has the problem of separating related sentences into different chunks. To avoid this problem, we can have an overlap between chunks. With this solution, the last N characters of a chunk will be repeated as the first N characters of the next chunk, so context is not lost.
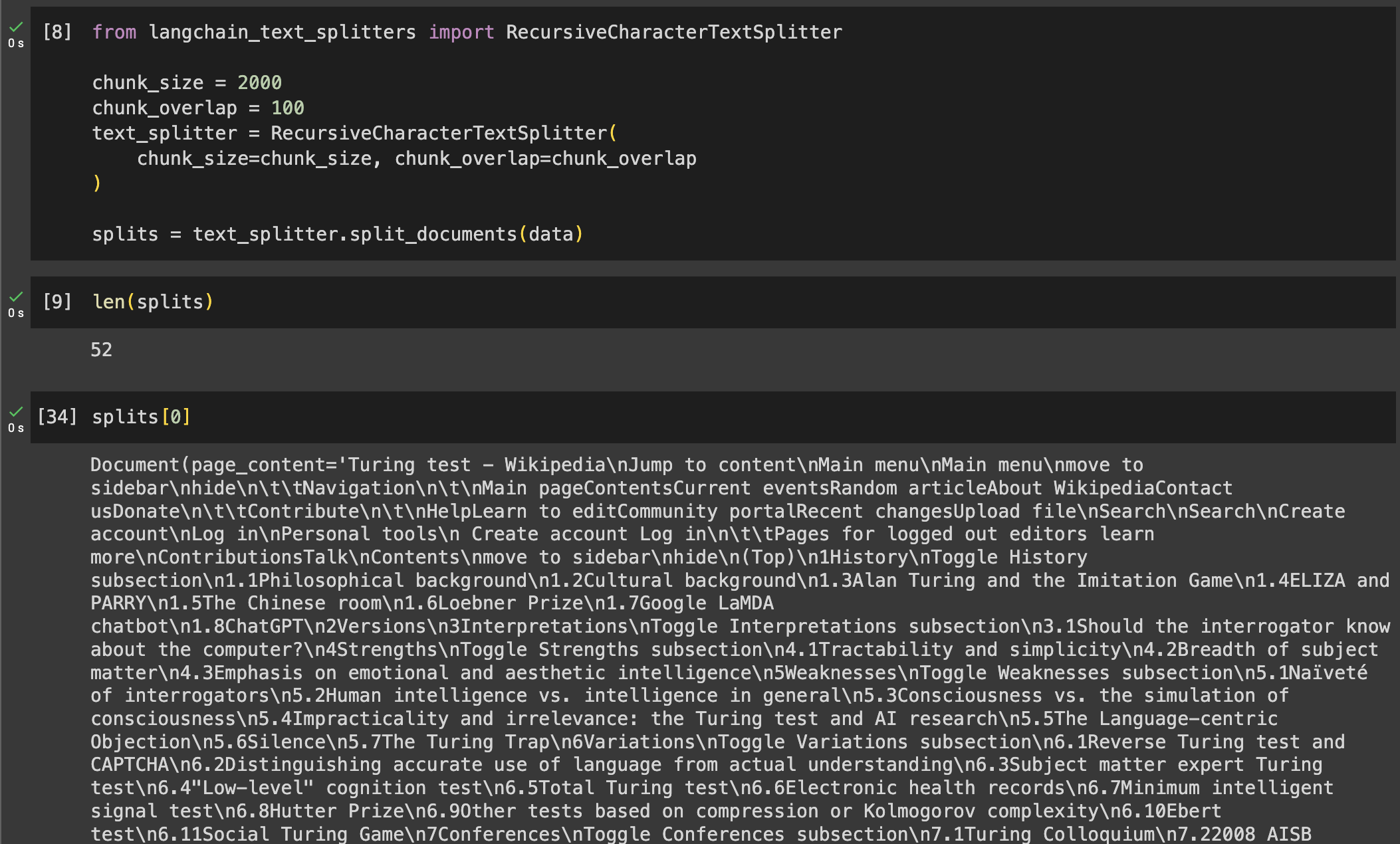
- Second, all chunks are summarized separately using the LLM. Remember to tune your summarize prompt to help understand the model what kind of document it is and how to summarize it properly. For example, you might want the summary to be a bullet point list of the main points of the text or you might want the summary to be just a few sentences.
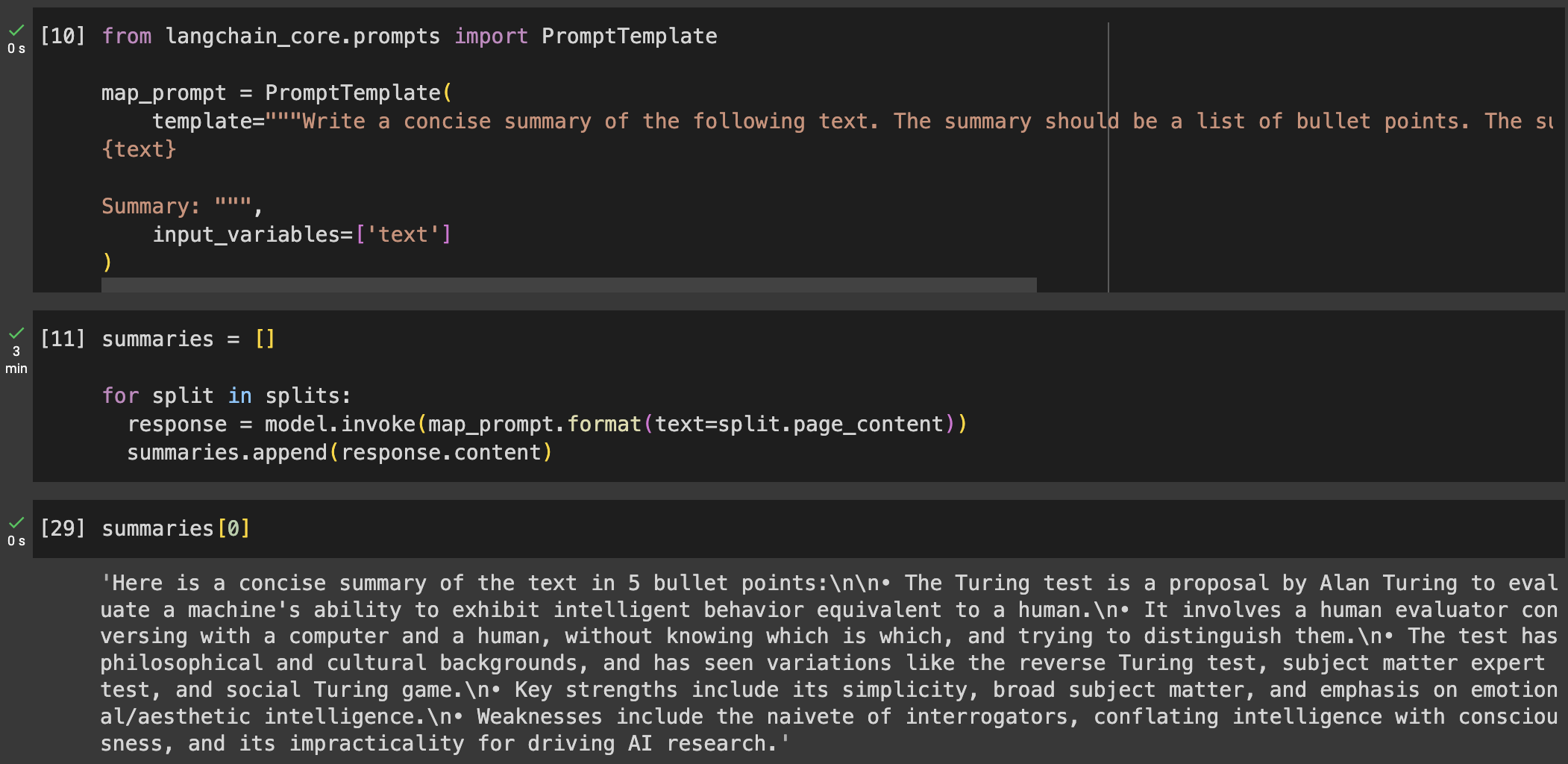
- The third step is optional. If the combination of all summaries does not fit into the context window, we won’t be able to ask for a consolidated summary. Instead, we need to make the combination of all summaries smaller.
- We will group the summaries in groups that fit into the context window.
- Then, we will write a prompt that combines all the summaries into a single summary with the key ideas.
- After reducing all the summary groups, if the resulting combined summaries still don't fit in the context window, this process is executed again.
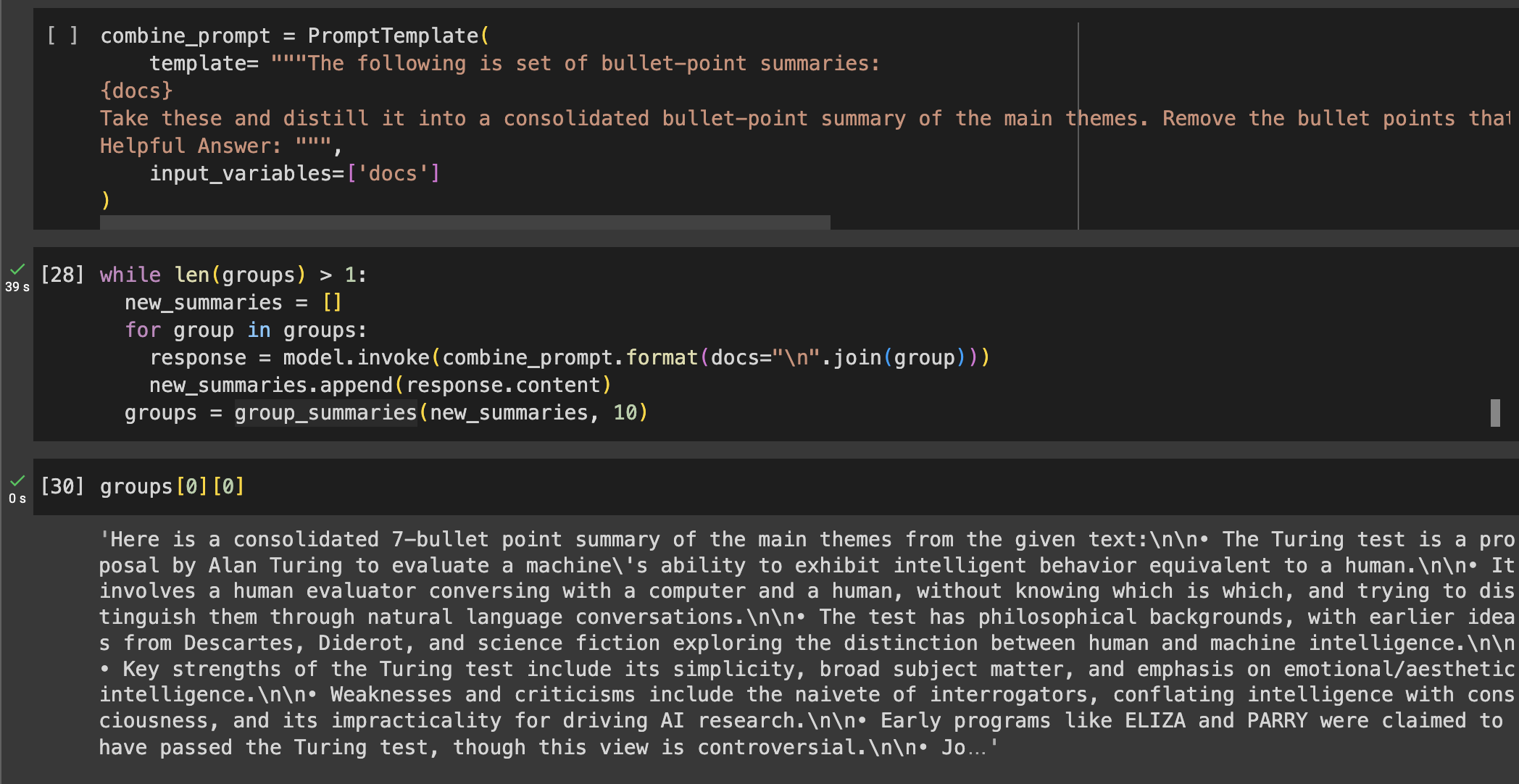
- Lastly, when all summaries fit into the context window, we can finally combine or reduce them into the final summary.
- We will write a prompt that combines all the summaries into a single final summary with all the key ideas. This prompt is usually the same as the one in step 3 since the idea is basically the same; combine a list of summaries into one shorter summary. However, you might need the freedom to diverge the two prompts to accommodate specific needs for special kinds of documents or special summaries.
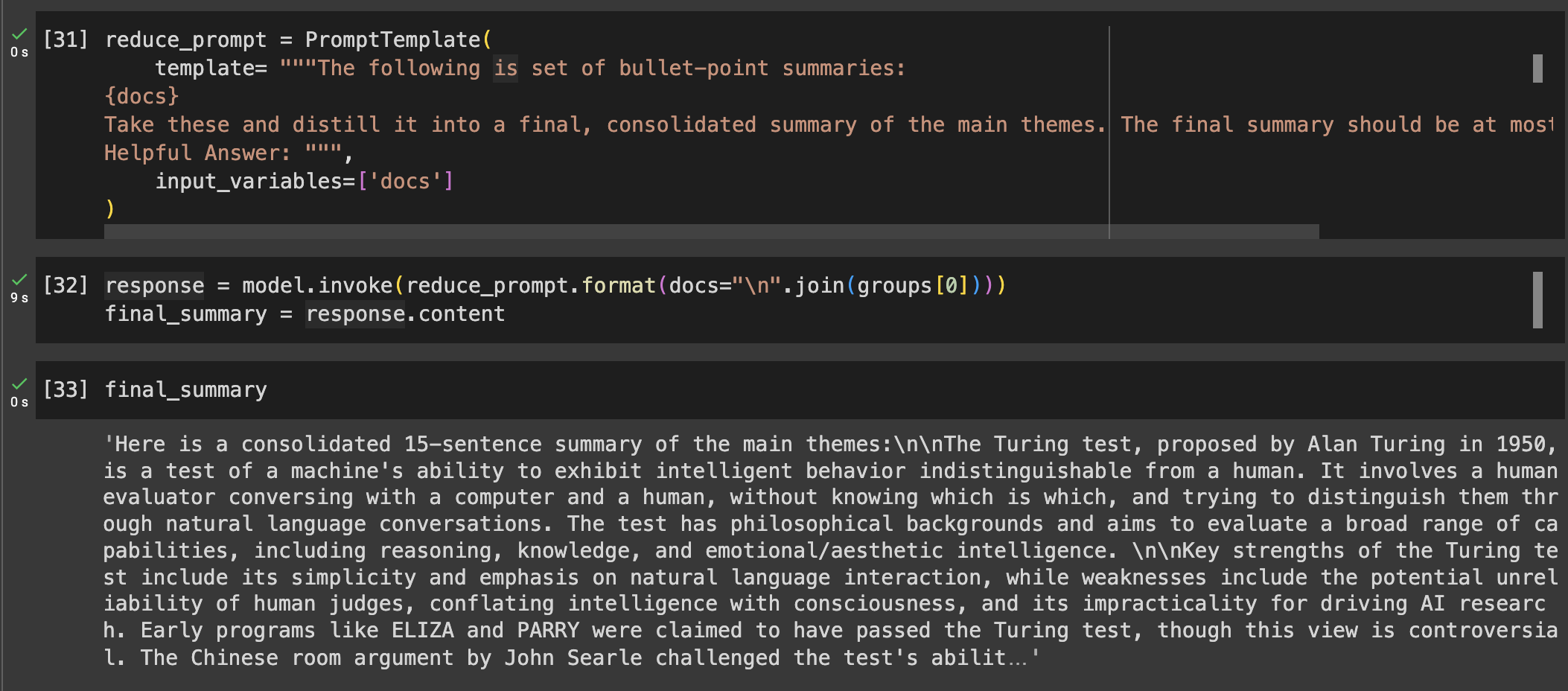
And that’s it! You now have a short summary of the most important points of a large document. But before you start processing your whole documentation, there are a few important notes you need to consider:
- This MapReduce method might not be less expensive than using an LLM with a large context window, especially if your cost is per token (as it is in all Model-as-a-service LLMs). Using this method, you will still use all the tokens in the document, plus the tokens of the intermediate summaries (as output and then as input of intermediate prompts). I recommend you study first which method will be more costly for your use case.
- While better models will produce better summaries, the summarization capabilities of not-so-good models will be good enough for most cases. The result after many layers of summarization will be of similar quality, so you might be able to get away with using cheaper models if you decide to use this method.
Published at DZone with permission of Roger Oriol. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments