How to Run SQL Queries With Presto on Google BigQuery
In this hands-on tutorial, you'll learn how to run SQL queries with Presto, the open source SQL query engine for data lakes, on Google BigQuery.
Join the DZone community and get the full member experience.
Join For FreePresto has evolved into a unified SQL engine on top of cloud data lakes for both interactive queries as well as batch workloads with multiple data sources. This tutorial will show you how to run SQL queries with Presto (running with Kubernetes) on Google BigQuery.
Presto’s BigQuery connector allows querying the data stored in BigQuery. This can be used to join data between different systems like BigQuery and Hive. The connector uses the BigQuery Storage API to read the data from the tables.
Step 1: Set up a Presto Cluster With Kubernetes
Set up your own Presto cluster on Kubernetes using these instructions or you can use Ahana’s managed service for Presto.
Step 2: Set up a Google BigQuery Project With Google Cloud Platform
Create a Google BigQuery project from Google Cloud Console and make sure it’s up and running with dataset and tables as described here.
The below screen shows the Google BigQuery project with table “Flights”
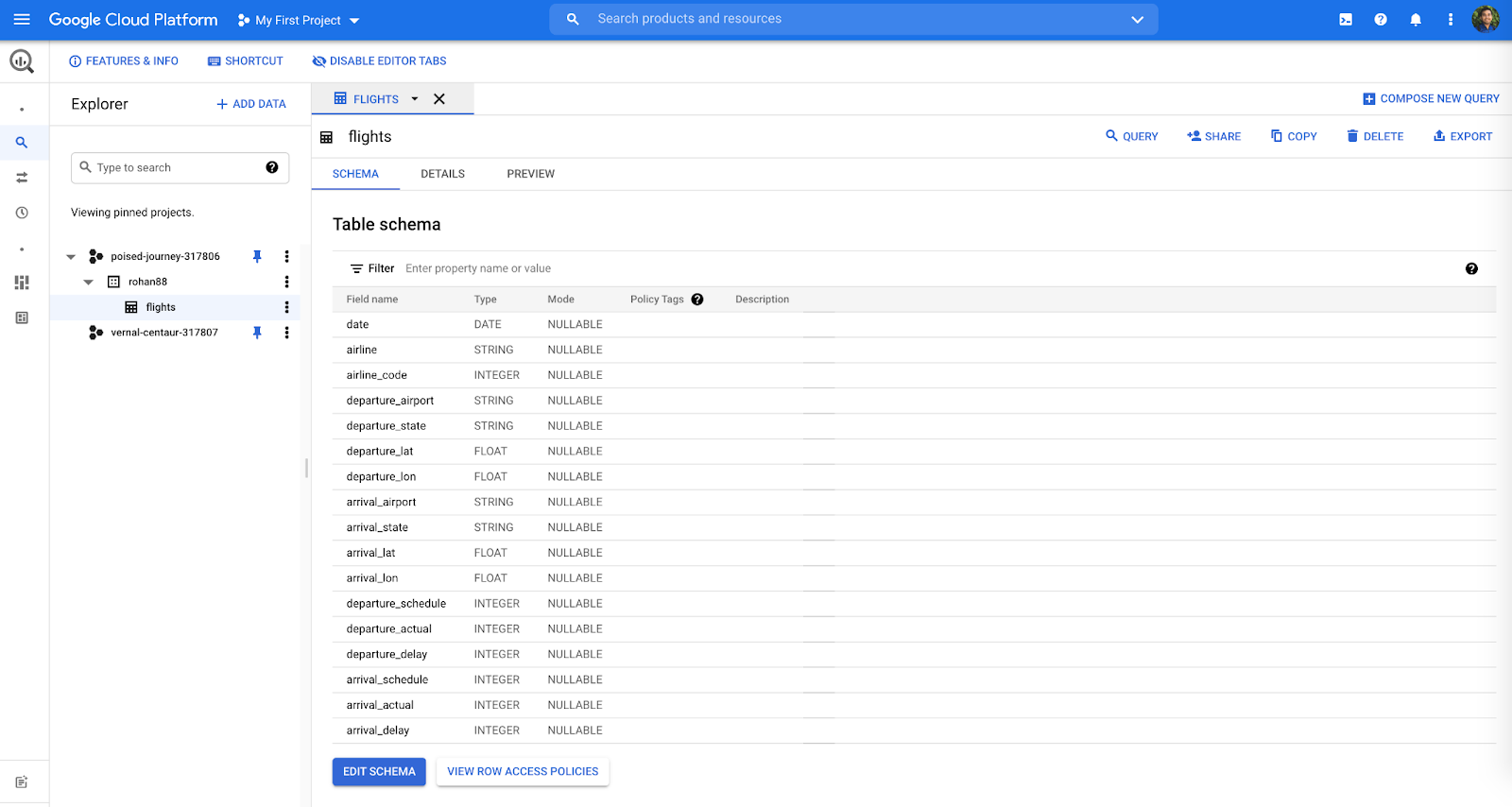
Step 3: Set up a Key and Download Google BigQuery Credential JSON File
To authenticate the BigQuery connector to access the BigQuery tables, create a credential key and download it in JSON format.
Use a service account JSON key and GOOGLE_APPLICATION_CREDENTIALS as described here.
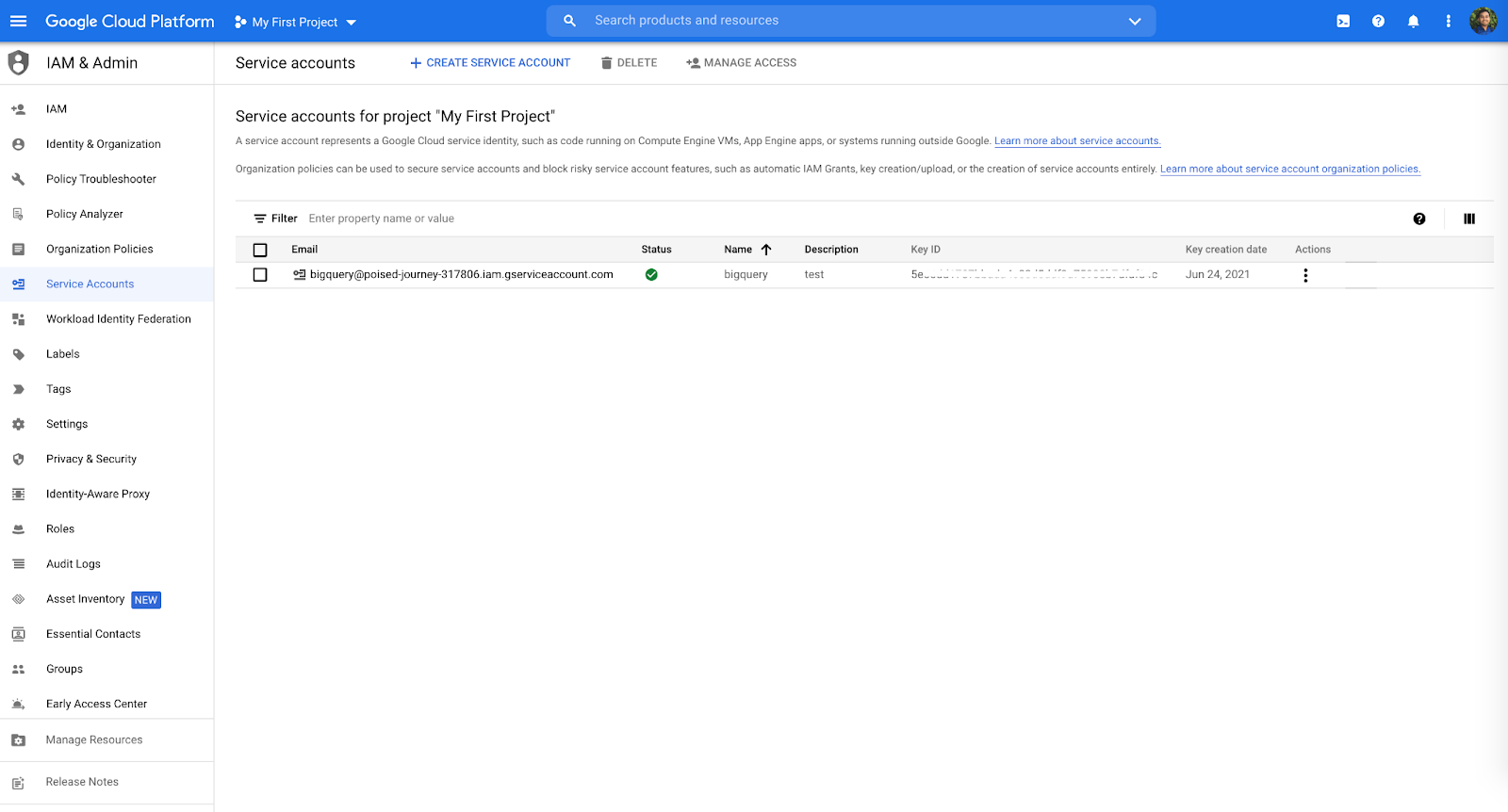
Sample credential file should look like this
{
"type": "service_account",
"project_id": "poised-journey-315406",
"private_key_id": "5e66dd1787bb1werwerd5ddf9a75908b7dfaf84c",
"private_key": "-----BEGIN PRIVATE KEY-----\nMIIEvgIBADANBgkqhkiG9w0BAQEFAASCBKgwgKozSEK84b\ntNDXrwaTGbP8ZEddTSzMZQxcX7j3t4LQK98OO53i8Qgk/fEy2qaFuU2yM8NVxdSr\n/qRpsTL/TtDi8pTER0fPzdgYnbfXeR1Ybkft7+SgEiE95jzJCD/1+We1ew++JzAf\nZBNvwr4J35t15KjQHQSa5P1daG/JufsxytY82fW02JjTa/dtrTMULAFOSK2OVoyg\nZ4feVdxA2TdM9E36Er3fGZBQHc1rzAys4MEGjrNMfyJuHobmAsx9F/N5s4Cs5Q/1\neR7KWhac6BzegPtTw2dF9bpccuZRXl/mKie8EUcFD1xbXjum3NqMp4Gf7wxYgwkx\n0P+90aE7AgMBAAECggEAImgvy5tm9JYdmNVzbMYacOGWwjILAl1K88n02s/x09j6\nktHJygUeGmp2hnY6e11leuhiVcQ3XpesCwcQNjrbRpf1ajUOTFwSb7vfj7nrDZvl\n4jfVl1b6+yMQxAFw4MtDLD6l6ljKSQwhgCjY/Gc8yQY2qSd+Pu08zRc64x+IhQMn\nne1x0DZ2I8JNIoVqfgZd0LBZ6OTAuyQwLQtD3KqtX9IdddXVfGR6/vIvdT4Jo3en\nBVHLENq5b8Ex7YxnT49NEXfVPwlCZpAKUwlYBr0lvP2WsZakNCKnwMgtUKooIaoC\nSBxXrkmwQoLA0DuLO2B7Bhqkv/7zxeJnkFtKVWyckQKBgQC4GBIlbe0IVpquP/7a\njvnZUmEuvevvqs92KNSzCjrO5wxEgK5Tqx2koYBHhlTPvu7tkA9yBVyj1iuG+joe\n5WOKc0A7dWlPxLUxQ6DsYzNW0GTWHLzW0/YWaTY+GWzyoZIhVgL0OjRLbn5T7UNR\n25opELheTHvC/uSkwA6zM92zywKBgQC3PWZTY6q7caNeMg83nIr59+oYNKnhVnFa\nlzT9Yrl9tOI1qWAKW1/kFucIL2/sAfNtQ1td+EKb7YRby4WbowY3kALlqyqkR6Gt\nr2dPIc1wfL/l+L76IP0fJO4g8SIy+C3Ig2m5IktZIQMU780s0LAQ6Vzc7jEV1LSb\nxPXRWVd6UQKBgQCqrlaUsVhktLbw+5B0Xr8zSHel+Jw5NyrmKHEcFk3z6q+rC4uV\nMz9mlf3zUo5rlmC7jSdk1afQlw8ANBuS7abehIB3ICKlvIEpzcPzpv3AbbIv+bDz\nlM3CdYW/CZ/DTR3JHo/ak+RMU4N4mLAjwvEpRcFKXKsaXWzres2mRF43BQKBgQCY\nEf+60usdVqjjAp54Y5U+8E05u3MEzI2URgq3Ati4B4b4S9GlpsGE9LDVrTCwZ8oS\n8qR/7wmwiEShPd1rFbeSIxUUb6Ia5ku6behJ1t69LPrBK1erE/edgjOR6SydqjOs\nxcrW1yw7EteQ55aaS7LixhjITXE1Eeq1n5b2H7QmkQKBgBaZuraIt/yGxduCovpD\nevXZpe0M2yyc1hvv/sEHh0nUm5vScvV6u+oiuRnACaAySboIN3wcvDCIJhFkL3Wy\nbCsOWDtqaaH3XOquMJtmrpHkXYwo2HsuM3+g2gAeKECM5knzt4/I2AX7odH/e1dS\n0jlJKzpFpvpt4vh2aSLOxxmv\n-----END PRIVATE KEY-----\n",
"client_email": "bigquery@poised-journey-678678.iam.gserviceaccount.com",
"client_id": "11488612345677453667",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x505/bigquery%40poised-journey-315406.iam.gserviceaccount.com"
}Pro-Tip: Before you move to the next step please try to use your downloaded credential JSON file with other third-party sql tools like DBeaver to access your BigQuery Table. This is to make sure that your credentials have valid access rights or to isolate any issue with your credentials.
Step 4: Configure Presto Catalog for Google BigQuery Connector
To configure the BigQuery connector, you need to create a catalog properties file in etc/catalog named, for example, bigquery.properties, to mount the BigQuery connector as the bigquery catalog. You can create the file with the following contents, replacing the connection properties as appropriate for your setup. This should be done via the edit configmap to make sure it's reflected in the deployment:
kubectl edit configmap presto-catalog -n <cluster_name> -o yaml
The following are the catalog properties that need to be added:
connector.name=bigquery bigquery.project-id=<your Google Cloud Platform project id> bigquery.credentials-file=patch/for/bigquery-credentials.json
The following are the sample entries for the catalog yaml file:
bigquery.properties: | connector.name=bigquery bigquery.project-id=poised-journey-317806 bigquery.credentials-file=/opt/presto-server/etc/bigquery-credential.json
Step 5: Configure Presto Coordinator and Workers With Google BigQuery Credential File
To configure the BigQuery connector:
- Load the content of a credential file as bigquery-credential.json in presto coordinator’s configmap:
kubectl edit configmap presto-coordinator-etc -n <cluster_name> -o yaml
- Add a new session of volumeMounts for the credential file in coordinator’s deployment file:
kubectl edit deployment presto-coordinator -n <cluster_name>
Following the sample configuration, That you can append in your coordinator's deployment file at the end of volumeMounts section:
volumeMounts: - mountPath:/opt/presto-server/etc/bigquery-credential.json name: presto-coordinator-etc-vol subPath: bigquery-credential.json
- Load the content of a credential file as bigquery-credential.json in presto worker's configmap:
kubectl edit configmap presto-worker-etc -n <cluster_name> -o yaml
- Add a new session of volumeMounts for the credential file in the worker’s deployment file:
kubectl edit deployment presto-worker -n <cluster_name>
Following the sample configuration, That you can append in your worker’s deployment file at the end of volumeMounts section:
volumeMounts: - mountPath:/opt/presto-server/etc/bigquery-credential.json name: presto-worker-etc-vol subPath: bigquery-credential.json
Step 6: Set up Database Connection With Apache Superset
Create your own database connection URL to query from Superset with the below syntax
presto://<username>:<password>@bq.rohan1.dev.app:443/<catalog_name>

Step 7: Check for Available Datasets, Schemas and Tables, etc.
After successfully database connection with Superset, Run the following queries and make sure that the bigquery catalog gets picked up and perform show schemas and show tables to understand available data.
show catalogs;

show schemas from bigquery;
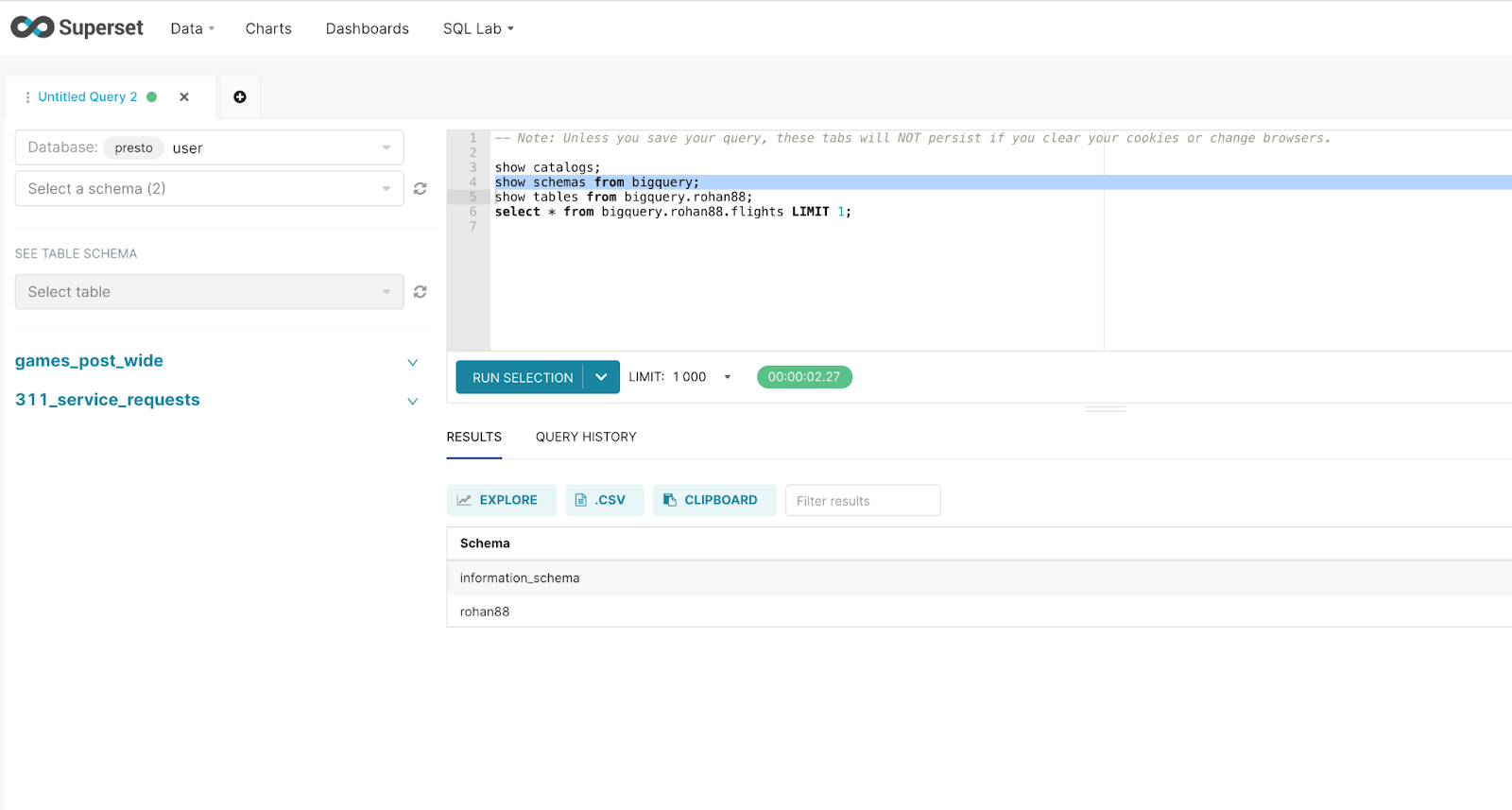
show tables from bigquery.rohan88;
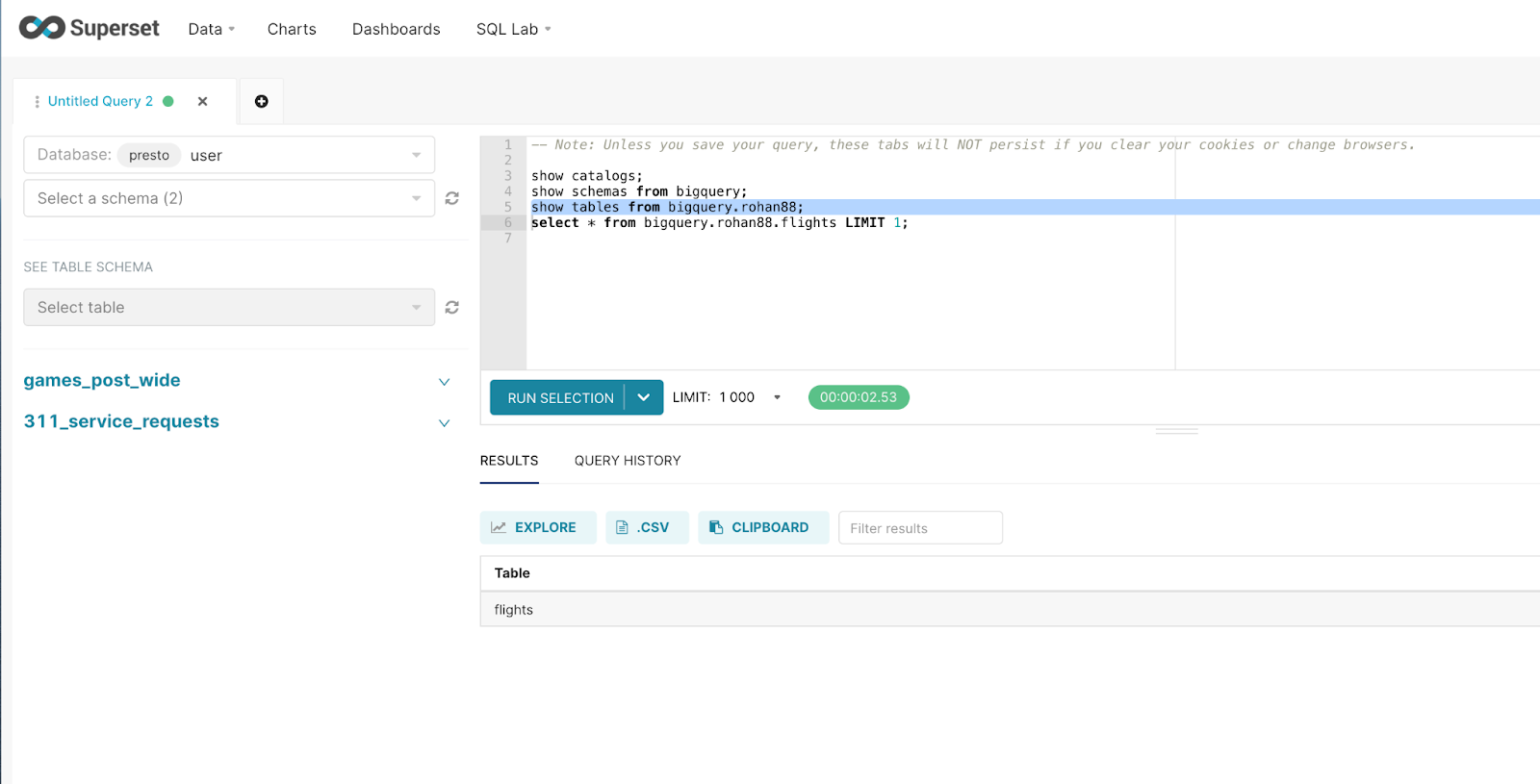
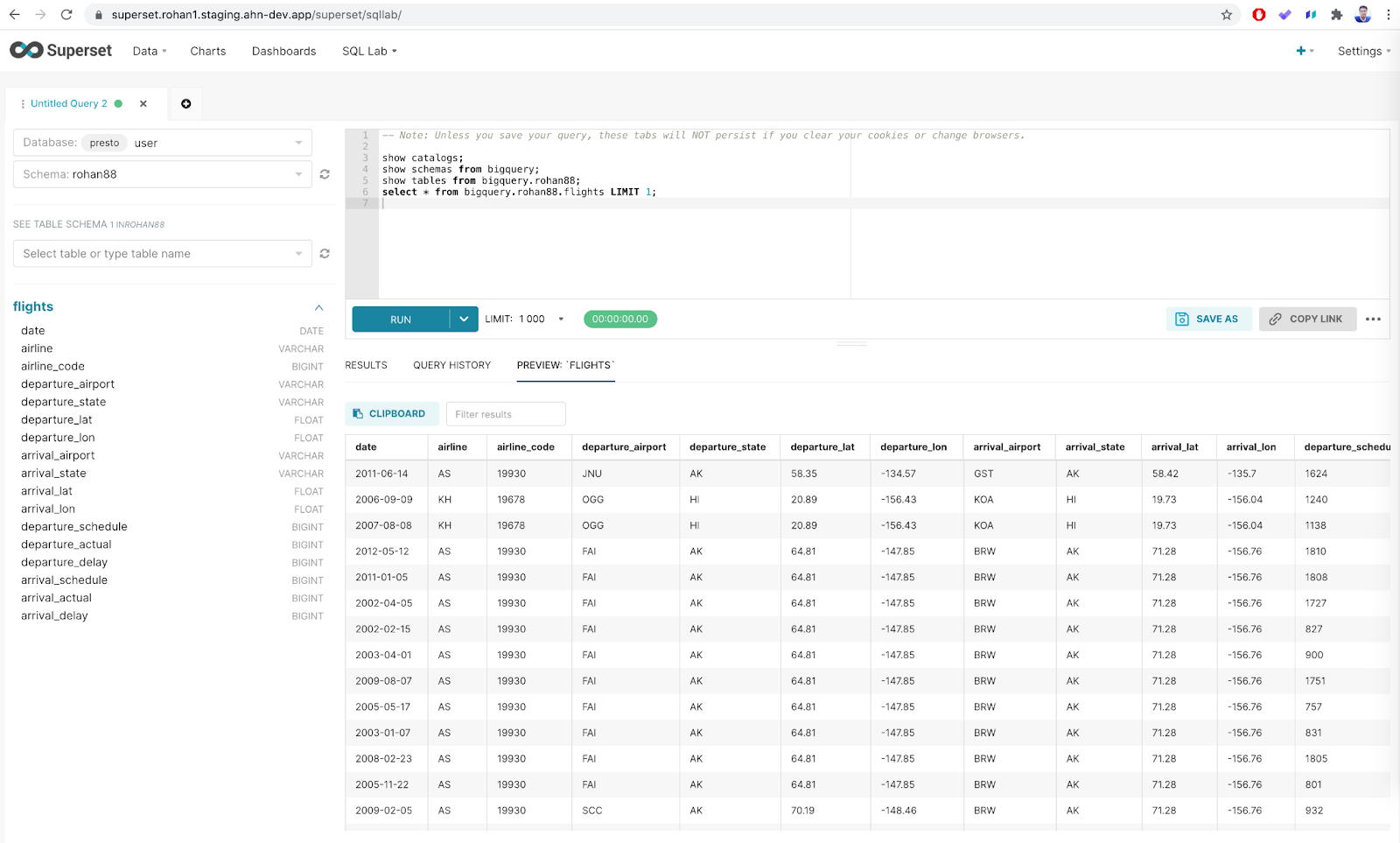
Step 8: Run SQL Query From Apache Superset to Access BigQuery Table
Once you access your database schema, you can run SQL queries against the tables as shown below.
select * from catalog.schema.table;
select * from bigquery.rohan88.flights LIMIT1;
You can perform similar queries from Presto Cli as well, here is another example of running sql queries on different Bigquery dataset from Preso Cli.
$./presto-cli.jar --server https://<presto.cluster.url> --catalog bigquery --schema <schema_name> --user <presto_username> --password
The following example shows how you can join Google BigQuery table with the Hive table from S3 and run sql queries.
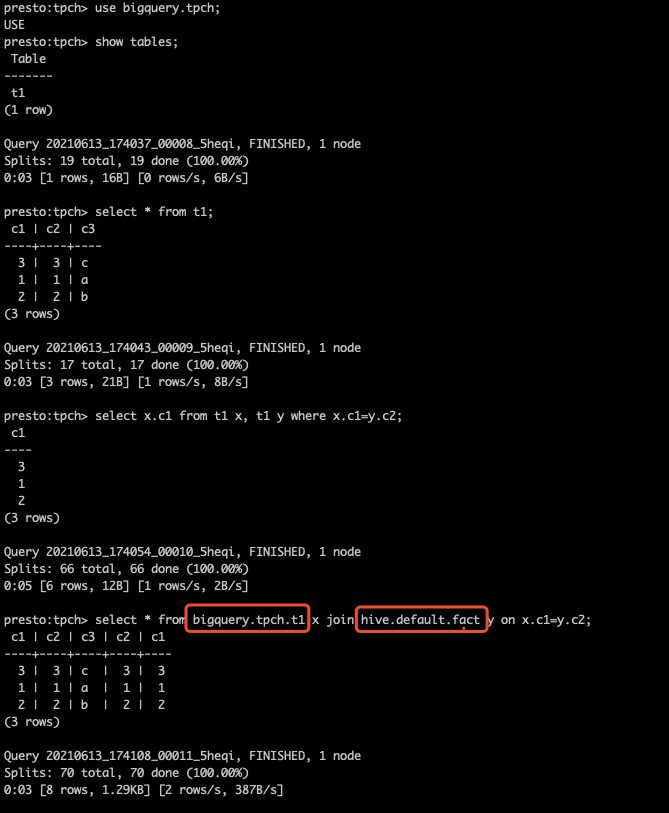
And now you should be able to query BigQuery using Presto!
Published at DZone with permission of Rohan Pednekar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments