How to Reuse Java Streams
Need to use your streams over and over again? Let's cover three different approaches, their benefits, and their pitfalls when recycling Java streams.
Join the DZone community and get the full member experience.
Join For FreeAlthough Java streams were designed to be operated only once, programmers still ask how to reuse a stream. From a simple web search, we can find many posts with this same issue asked in many different ways: "Is there any way to reuse a Stream in java 8?", "Copy a stream to avoid stream has already been operated upon or closed", "Java 8 Stream IllegalStateException", and others.
Hence, if we want to traverse a Stream<T> multiple times, then either we have to:
Redo the computation to generate the stream from the data source, or
Store the intermediate result into a collection.
Yet, both options have drawbacks and none of them is best suited for all use cases. Using the first approach, what happens if data comes across the network, or from a file or database, or other external source? In this case, we must return to the data source again, which may have more overhead than storing the intermediate result into a collection. So, for multiple traversals on immutable data, maybe the second solution is more advantageous. Yet, if we are only going to use the data once, then we get an efficiency issue using this approach, because we did not have to store the data source in memory.
Here, we will explore a third alternative which memoizes items on-demand only when they are accessed by a traversal. We analyze the limitations and advantages of each approach on data resulting from an HTTP request and will incrementally combine these solutions:
- Using a
Supplier<Stream<…>> - Memoizing the entire stream into a collection to avoid multiple roundtrips to data source.
- Memoizing and replaying items on demand into and from an internal buffer.
In order to understand all details of this article you must be familiarized with streams terminology.
Streams Use Case
Stream operations are very convenient to perform queries on sequences of items, and many times programmers look for a way to consume a Stream more than once. Moreover, in other programming environments, such as .NET and JavaScript, programmers are not stuck with this limitation (one-shot traversal), because stream operations are not provided at the Iterator level, but instead at Iterable level, which can be traversed multiple times. So, in .NEt or JavaScript, we can operate on the same data with different queries without violating any internal state, because every time a query is computed, it will get a fresh iterator from the source.
To highlight the drawbacks of alternative approaches of reusing Java streams, we will present a use case based on an HTTP request. To that end, we will use the World Weather online API to get a sequence of items with weather information in a CSV data format. Particularly, we are interested in a sequence of temperatures in degrees Celsius in March at Lisbon, Portugal. So we must perform an HTTP GET request to the URI http://api.worldweatheronline.com/premium/v1/past-weather.ashx with the query parameters q=37.017,-7.933 corresponding to Lisbon's coordinates, date=2018-03-01&enddate=2018-03-31 defining the date interval, tp=24 to get data in 24 hour periods, format=csv to specify the data format, and finally key= with the API key.
To perform this HTTP request, we will use a non-blocking API, such as AsyncHttpClient, and the response will be a sequence of lines in CSV format (e.g. Stream<String>). Since we are using an asynchronous API, we do not want to wait for response completion; hence the result of the HTTP request is wrapped into a promise of that response. In Java, a promise is represented by a CompletableFuture instance (e.g. CompletableFuture<Stream<String>) and it is obtained from the following HTTP request with the AsyncHttpClient:
Pattern pat =Pattern.compile("\\n");
CompletableFuture<Stream<String>> csv = asyncHttpClient()
.prepareGet("http://api.worldweatheronline.com/premium/v1/past-weather.ashx?q=37.017,-7.933&date=2018-04-01&enddate=2018-04-30&tp=24&format=csv&key=54a4f43fc39c435fa2c143536183004")
.execute()
.toCompletableFuture()
.thenApply(Response::getResponseBody)
.thenApply(pat::splitAsStream);Now, in order to get a sequence of temperatures, we must parse the CSV according to the following rules:
- Ignore lines starting with
#, which correspond to comments. - Skip one line.
- Filter lines alternately.
- Extract the third value corresponding to a temperature in Celsius.
- Convert it to an integer.
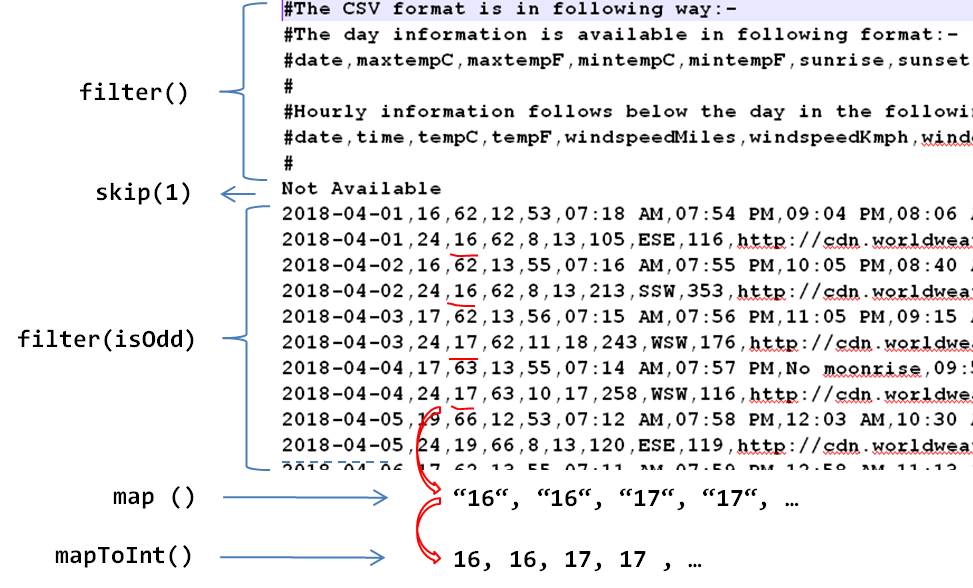
To make these transformations without waiting for response completion, we will use the method thenApply() of CompletableFuture passing a function that will convert the Stream<String> into an IntStream. Thus, when the resulting csv is available (i.e. Stream<String>), it will continue processing the transformation without blocking:
boolean [] isEven = {true};
Pattern comma =Pattern.compile(",");
CompletableFuture<IntStream> temps = csv.thenApply(str -> str
.filter(w ->!w.startsWith("#")) // Filter comments
.skip(1) // Skip line: Not Available
.filter(l -> isEven[0] =!isEven[0]) // Filter Even line
.map(line -> comma.splitAsStream(line).skip(2).findFirst().get()) // Extract temperature in Celsius
.mapToInt(Integer::parseInt));Finally, we can build a Weather service class providing an auxiliary asynchronous method getTemperaturesAsync(double lat, double log, LocalDate from, LocalDate to) to get a sequence of temperatures for a given location and an interval of dates:
public class Weather{
...
public static CompletableFuture<IntStream> getTemperaturesAsync(double lat, double log, LocalDate from, LocalDate to) {
AsyncHttpClient asyncHttpClient = asyncHttpClient();
CompletableFuture<Stream<String>> csv = asyncHttpClient
.prepareGet(String.format(PATH, lat, log, from, to, KEY))
.execute()
.toCompletableFuture()
.thenApply(Response::getResponseBody)
.thenApply(NEWLINE::splitAsStream);
boolean[] isEven = {true};
return csv.thenApply(str -> str
.filter(w ->!w.startsWith("#")) // Filter comments
.skip(1) // Skip line: Not Available
.filter(l -> isEven[0] =!isEven[0]) // Filter Even line
.map(line ->COMMA.splitAsStream(line).skip(2).findFirst().get()) // Extract temperature in Celsius
.mapToInt(Integer::parseInt));// Convert to Integer
}Approach 1: Supplier<Stream<...>>
Given the method getTemperaturesAsync(), we can get a sequence of temperatures at Lisbon in March as:
CompletableFuture<IntStream> lisbonTempsInMarch = Weather
.getTemperaturesAsync(38.717, -9.133, of(2018,4,1), of(2018,4,30));Now, whenever we want to perform a query we may get the resulting stream from the CompletableFuture. In the following example, we are getting the maximum temperature in March and counting how many days reached this temperature.
int maxTemp = lisbonTempsInMarch.join().max();
long nrDaysWithMaxTemp = lisbonTempsInMarch
.join()
.filter(maxTemp::equals)
.count(); // Throws IllegalStateException However, the second query will throw an exception because the stream from lisbonTempsInMarch.join() has already been operated on. To avoid this exception, we must get a fresh stream combining all intermediate operations to the data source. This means that we have to make a new HTTP request and repeat all the transformations over the HTTP response. To that end, we will use a Supplier<CompletableFuture<Stream<T>>> that wraps the request and subsequent transformations into a supplier:
Supplier<CompletableFuture<IntStream>> lisbonTempsInMarch = () -> Weather
.getTemperaturesAsync(38.717, -9.133, of(2018, 4, 1), of(2018, 4, 30));And now, whenever we want to execute a new query, we can perform a new HTTP request through the get() method of the supplier lisbonTempsInMarch, then get the resulting stream from the response through join(), and finally invoke the desired stream operations as:
int maxTemp = lisbonTempsInMarch.get().join().max();
long nrDaysWithMaxTemp = lisbonTempsInMarch
.get()
.join()
.filter(maxTemp::equals)
.count();To avoid the consecutive invocation of get() and join(), we can put the call to join() method inside the supplier as:
Supplier<CompletableFuture<IntStream>> lisbonTempsInMarch = () ->Weather
.getTemperaturesAsync(38.717, -9.133, of(2018, 4, 1), of(2018, 4, 30))
.join();And now we can simply write:
int maxTemp = lisbonTempsInMarch.get().max();
long nrDaysWithMaxTemp = lisbonTempsInMarch
.get()
.filter(maxTemp::equals)
.count();Briefly, according to this approach, we are creating a new stream chain (with all the transformations specified in getTemperaturesAsync()) every time we want to consume that stream. This idea is based on a claim of the Java documentation about Stream operations and pipelines that states:
if you need to traverse the same data source again, you must return to the data source to get a new stream.
However, this technique forces the re-creation of the whole pipeline to the data source, which incurs inevitable IO due to the HTTP request. Since data from past weather information is immutable, then this HTTP request is useless because we will always get the same sequence of temperatures.
Approach 2: Memoize to a Collection
To avoid useless accesses to the data source, we may first dump the stream elements into an auxiliary collection (e.g. List<T> list = data.collect(Collectors.toList())) and then get a new Stream from the resulting collection whenever we want to operate that sequence (e.g. list.stream().filter(…).map(…)….).
Using this technique, we can transform the resulting promise from the getTemperaturesAsync() into a new promise of a list of integers (i.e. CompletableFuture<List<Integer>>). Thus, when we get the HTTP response (and after it is transformed into an IntStream), then it will proceed to be collected into a List<Integer>:
CompletableFuture<List<Integer>> mem = Weather
.getTemperaturesAsync(38.717, -9.133, of(2018, 4, 1), of(2018, 4, 30))
.thenApply(strm -> strm.boxed().collect(toList()));With this CompletableFuture<List<Integer>>, we can build a Supplier<Stream<Integer>> that returns a new stream from the list contained in the CompletableFuture.
Supplier<Stream<Integer>> lisbonTempsInMarch = () -> mem.join().stream();Now, when we ask for a new stream to lisbonTempsInMarch, instead of chaining a stream pipeline to the data source (approach 1), we will get a fresh stream from the auxiliary list contained in mem that collected the intermediate sequence of temperatures.
Integer maxTemp = lisbonTempsInMarch.get().max(Integer::compare).get();
long nrDaysWithMaxTemp = lisbonTempsInMarch.get().filter(maxTemp::equals).count();Yet, this approach incurs in an additional traversal to first collect the stream items. We are wasting one traversal, which is not used to operate the stream elements (i.e. strm.boxed().collect(toList())) and then we incur in a second traversal to query that sequence (i.e. lisbonTempsInMarch.get().max(Integer::compare).get()). If we are only going to use the data once, then we get a huge efficiency issue, because we did not have to store it in memory. Moreover, we are also wasting powerful "loop fusion" optimizations offered by streams, which let data flow through the whole pipeline efficiently from the data source to the terminal operation.
To highlight the additional traversal that first occurs on collect consider the following example where we replace the getTemperaturesAsync() with a random stream of integers:
IntStream nrs = new Random()
.ints(0, 7)
.peek(n -> out.printf("%d, ", n))
.limit(10);
out.println("Stream nrs created!");
CompletableFuture<List<Integer>> mem =CompletableFuture
.completedFuture(nrs)
.thenApply(strm -> strm.boxed().collect(toList()));
out.println("Nrs wraped in a CF and transformed in CF<List<Integer>>!");
Supplier<Stream<Integer>> nrsSource = () -> mem.join().stream();
Integer max = nrsSource.get().max(Integer::compare).get();
out.println("Nrs traversed to get max = "+ max);
long maxOccurrences = nrsSource.get().filter(max::equals).count();
out.println("Nrs traversed to count max occurrences = "+ maxOccurrences);The following output results from the execution of the previous code:
Stream nrs created!
1, 0, 4, 6, 0, 6, 6, 3, 1, 2, Nrs wraped in a CF and transformed in CF<List>!
Nrs traversed to get max = 6
Nrs traversed to count occurrences of max = 3
Note that when the resulting stream (i.e. nrsSource.get()) is traversed by the max() operation, the stream from data source nrs has already been computed by the collect() operation resulting in the output: 1, 0, 4, 6, 0, 6, 6, 3, 1, 2,. So, instead of executing just 2 traversals to compute 2 queries, the maximum value and the number of occurrences of the maximum value; we are performing one more traversal first that is not used in any of the end queries.
Approach 3: Memoize and Replay On Demand
Now, we propose a third approach where we memoize items only when they are accessed by a traversal. Later, an item may be retrieved from the mem or the data source, depending on whether it has already been requested by a previous operation,. These two streams are expressed by the following stream concatenation:
() -> Stream.concat(mem.stream(), StreamSupport.stream(srcIter, false))This supplier produces a new stream resulting from the concatenation of two other streams: one from the mem (i.e. mem.stream()) and other from the data source (i.e. stream(srcIter, false)). When the stream from mem is empty or an operation finishes traversing it, then it will proceed in the second stream built from the srcIter. The srcIter is an instance of an iterator (MemoizeIter) that retrieves items from the data source and adds them to mem. Considering that src is the data source, then the definition of MemoizeIter is according to the following implementation of the memoize() method:
public static <T> Supplier<Stream<T>> memoize(Stream<T> src) {
final Spliterator<T> iter = src.spliterator();
final ArrayList<T> mem = new ArrayList<>();
class MemoizeIter extends Spliterators.AbstractSpliterator<T> {
MemoizeIter() { super(iter.estimateSize(), iter.characteristics()); }
public boolean tryAdvance(Consumer<? super T> action) {
return iter.tryAdvance(item -> {
mem.add(item);
action.accept(item);
});
}
}
MemoizeIter srcIter = new MemoizeIter();
return () -> concat(mem.stream(), stream(srcIter, false));
}We could also build a stream from an iterator implementing the Iterator interface, but that is not the iteration approach followed by Stream, which would require a conversion of that iterator to a Spliterator. For that reason, we implement MemoizeIter with the Spliterator interface to avoid further indirections. Since Spliterator requires the implementation of several abstract methods related with partition capabilities for parallel processing, we choose to extend AbstractSpliterator instead, which permits limited parallelism and just needs to implement a single method. The method tryAdvance(action) is the core iteration method, which performs the given action for each remaining element sequentially until all elements have been processed. So, on each iteration, it adds the current item to the internal mem and retrieves that item to the consumer action:
item -> {
mem.add(item);
action.accept(item);
}Yet, this solution does not allow concurrent iterations on a stream resulting from the concatenation while the source has not been entirely consumed. When the stream from the source accesses a new item and adds it to the mem list, it will invalidate any iterator in progress on this list.
Consider the following example, where we get two iterators from a stream of integers memoized with the memoize() method. We get two items (i.e. 1 and 2) from the first stream (iter1), and then we get a second stream (iter2), which is composed by one stream with the previous two items (i.e. 1 and 2) and another stream from the source. After that, we get the third item from the first stream (iter1), which is added to the internal mem and thus invalidates the internal stream of iter2. So when we get an item of iter2, we get a ConcurrentModificationException.
Supplier<Stream<Integer>> nrs = memoize(IntStream.range(1, 10).boxed());
Spliterator<Integer> iter1 = nrs.get().spliterator();
iter1.tryAdvance(out::println); // > 1
iter1.tryAdvance(out::println); // > 2
Spliterator<Integer> iter2 = nrs.get().spliterator();
iter1.tryAdvance(out::println); // > 3
iter2.forEachRemaining(out::print); // throws ConcurrentModificationException
System.out.println(); To avoid this scenario and to allow concurrent iterations, instead of concat(), we will use an alternative solution where the supplier resulting from memoize() always returns a new Spliterator-based stream that accesses items from mem or from the data source. It makes the decision on whether to read mem or the data source on-demand when the tryAdvance() is invoked. To that end, our solution comprises two entities: Recorder and MemoizeIter. The Recorder reads items from source iterator (i.e. srcIter), stores them in an internal buffer (i.e. mem), and passes them to a consumer. The MemoizeIter is a random access iterator that gets items from the Recorder, which in turn gets those items from the internal buffer (i.e. mem) or from the source (i.e. srcIter). The resulting stream pipeline creates a chain of:
dataSrc ----> srcIter ----> Recorder ----> MemoizeIter ----> stream
^
|
mem <--------|In the following listing, we present the implementation of the replay() utility method that creates a supplier responsible for chaining the above stream pipeline:
public static <T> Supplier<Stream<T>> replay(Supplier<Stream<T>> dataSrc) {
final Recorder<T> rec = new Recorder<>(dataSrc);
return () -> {
// MemoizeIter starts on index 0 and reads data from srcIter or
// from an internal mem replay Recorder.
Spliterator<T> iter = rec.memIterator();
return stream(iter, false);
};
}
static class Recorder<T> {
private final Spliterator<T> srcIter;
private final long estimateSize;
private boolean hasNext = true;
private ArrayList<T> mem;
public Recorder(Supplier<Stream<T>> dataSrc) {
srcIter = dataSrc.get().spliterator();
estimateSize = srcIter.estimateSize();
}
public synchronized boolean getOrAdvance(int index, Consumer<? super T> cons) {
if (index < mem.size()) {
// If it is in mem then just get if from the corresponding index.
cons.accept(mem.get(index));
return true;
} else if (hasNext)
// If not in mem then advance the srcIter iterator
hasNext = srcIter.tryAdvance(item -> {
mem.add(item);
cons.accept(item);
});
return hasNext;
}
public Spliterator<T> memIterator() { return new MemoizeIter(); }
class MemoizeIter extends Spliterators.AbstractSpliterator<T> {
int index = 0;
public MemoizeIter(){
super(estimateSize, srcIter.characteristics());
}
public boolean tryAdvance(Consumer<? super T> cons) {
return getOrAdvance(index++, cons);
}
public Comparator<? super T> getComparator() {
return srcIter.getComparator();
}
}
}For each data source, we have a single instance of Recorder and one instance of MemoizeIter per stream created by the supplier. Since the getOrAdvance() of Recorder may be invoked by different instances of MemoizeIter, then we made this method synchronized to guarantee that just one resulting stream will get a new item from the source iterator. This implementation solves the requirement of concurrent iterations on the same data source.
Conclusion
Reusing a stream is a realistic need that should not only be considered to 1) redo the computation to the data source, or 2) collect the intermediate result. For example, a lazy intersection operation requires multiple traversals of the same stream (i.e. others), which in the following case will throw anIllegalStateException on subsequent executions of others.anyMatch(n::equals)):
nrs.filter(n -> others.anyMatch(n::equals))But to solve this problem is not mandatory that the second stream others be fully collected into an intermediate collection. Although we need to traverse others multiple times, there are some cases where we do not need to traverse it to the end. Considering that all items from stream nrs always match an item at the beginning of the stream others, then we do not need to store all items of others in an intermediate collection.
With the replay() utility method we can memoize all accessed items on demand without incurring in a full traversal of others:
Supplier<Stream<Integer>> otherSrc = Replayer.replay(others);
nrs.filter(n -> othersSrc.get().anyMatch(n::equals))The final solution and source code for Replayer is available at Github repository javasync/streamemo. We also provide the streamemo library with the class Replayer at Maven Central Repository, which you can include in your project adding its dependency.
Reactive Streams implementations, such as RxJava or Reactor, provide similar feature to that one proposed in third approach. Thus, if using Stream is not a requirement, then with Reactor Core, we can simply convert the Supplier<Stream<T>> to a Flux<T>, which already provides the utility cache() method and then use Flux<T> operations rather than Stream<T> operations.
Regarding our use case, where lisbonTempsInMarch is a CompletableFuture<Stream<Integer>> with the result of an HTTP request transformed in a sequence of temperatures in Celsius, then we can perform both queries in the following way with the Flux API:
CompletableFuture<Stream<Integer>> lisbonTempsInMarch =Weather
.getTemperaturesAsync(38.717, -9.133, of(2018, 4, 1), of(2018, 4, 30))
.thenApply(IntStream::boxed);
Flux<Integer> cache =Flux
.fromStream(lisbonTempsInMarch::join)
.cache();
cache.reduce(Integer::max).subscribe(maxTemp -> …);
cache.filter(maxTemp::equals).count().subscribe(nrDaysWithMaxTemp -> …);Due to the asynchronous nature of Flux, the result of a terminal operation such as reduce() or count also produce an asynchronous result in an instance of Mono (i.e. the reactor equivalent to CompletableFuture), which can be followed up later through the subscribe() method.
If you enjoyed this article and want to learn more about Java Streams, check out this collection of tutorials and articles on all things Java Streams.
Opinions expressed by DZone contributors are their own.
Comments