How To Measure DevOps Mean Time to Recovery (MTTR)
In this post, you'll discover what MTTR measures, why it's useful for industry research, reasons it can mislead you, and how you can avoid problems with MTTR.
Join the DZone community and get the full member experience.
Join For FreeMean time to recovery (MTTR) gained fame thanks to the DevOps "four keys" and the DORA State of DevOps Report.
In this post, you'll discover:
- What MTTR measures?
- Why it's useful for industry research.
- Some reasons it can mislead you.
- How you can avoid problems with MTTR.
What MTTR Measures?
MTTR is the mean time to recovery, sometimes called the mean time to restore. It's the time it takes to get a system operational following a fault. It's become a standard measure of software delivery performance as part of the DORA metrics.
When you perform well against all DORA metrics, you have working software sooner, happier employees, and a competitive advantage in your industry.
How To Calculate MTTR
To collect the mean time to recovery, you need to collect the duration of each incident from when it started to when it ended. You then sum the durations and divide the total by the number of incidents.
Some teams calculate the median time to recovery by ordering all incidents and selecting the middle value.
Your software delivery process impacts recovery times, in particular:
- Architecture
- Documentation
- Observability
- Deployment pipeline performance
When you can recover quickly, incidents have less impact, and customers are happier. Therefore, you should inspect and adapt your process to make a recovery quick and low-risk.
Why MTTR Is Useful for Industry Research
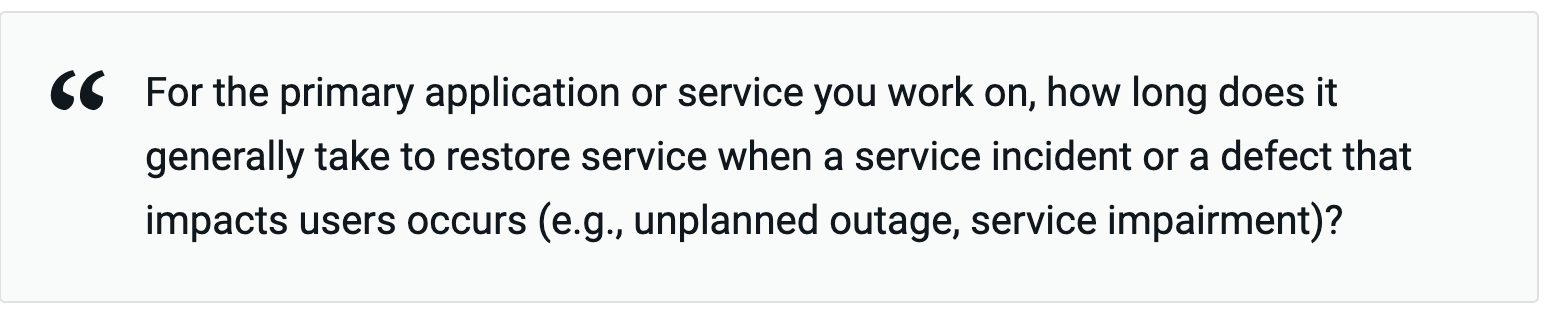
DevOps Research and Assessment (DORA) use a survey as part of their research. Questions need to be answerable across various organizations with different data and performance levels. The DORA quick check phrases the MTTR question as:

Most people working in software delivery have a feel for the incident duration. The broad buckets used in the survey make it easy to choose an answer. You can probably answer this for your team from memory with reasonable accuracy.
The researchers use this information to find performance groups in the data. They also look for relationships between various practices and their impact on business outcomes. Researchers build the DevOps structural equation model using these findings.
Why MTTR Might Mislead Your Team
While MTTR is helpful in research for performance clustering, this isn't how you use incident information in your team. You should use the information to learn from service outages and improve how you handle them in the future. The goal isn't to compare yourself to other teams or organizations.
For continuous improvement purposes, using an average hides essential signals. You need fine-grained information to understand how well you handle faults and to find their causes.
The Verica Open Incident Database (VOID) has over 10,000 incidents shared by almost 600 organizations. They analyze these incidents in the VOID report. The 2022 report made the following comment about MTTR:

Variability smoothes out when you have very large numbers. But your frequency is unlikely to result in the thousands of monthly incidents required for a useful average. With fewer incidents, averages become a volatile metric. The average may even increase despite improvements in incident management.
The VOID database also found that most incidents get resolved in under 2 hours, with a long thin tail of values that nudge the average up and down in a way that doesn't represent how customers view the system's reliability.
You could eliminate this variation by excluding outliers, but then you'd hide valuable information. You need a better way to use this data to improve your process.
Where Restore Times Remain Useful
Instead of zipping up your incidents into an average number, plot each duration on a chart. Use a scatter plot or box-and-whisker chart to visualize durations without losing fidelity. This shows you trends and outliers, which is more valuable than an average.
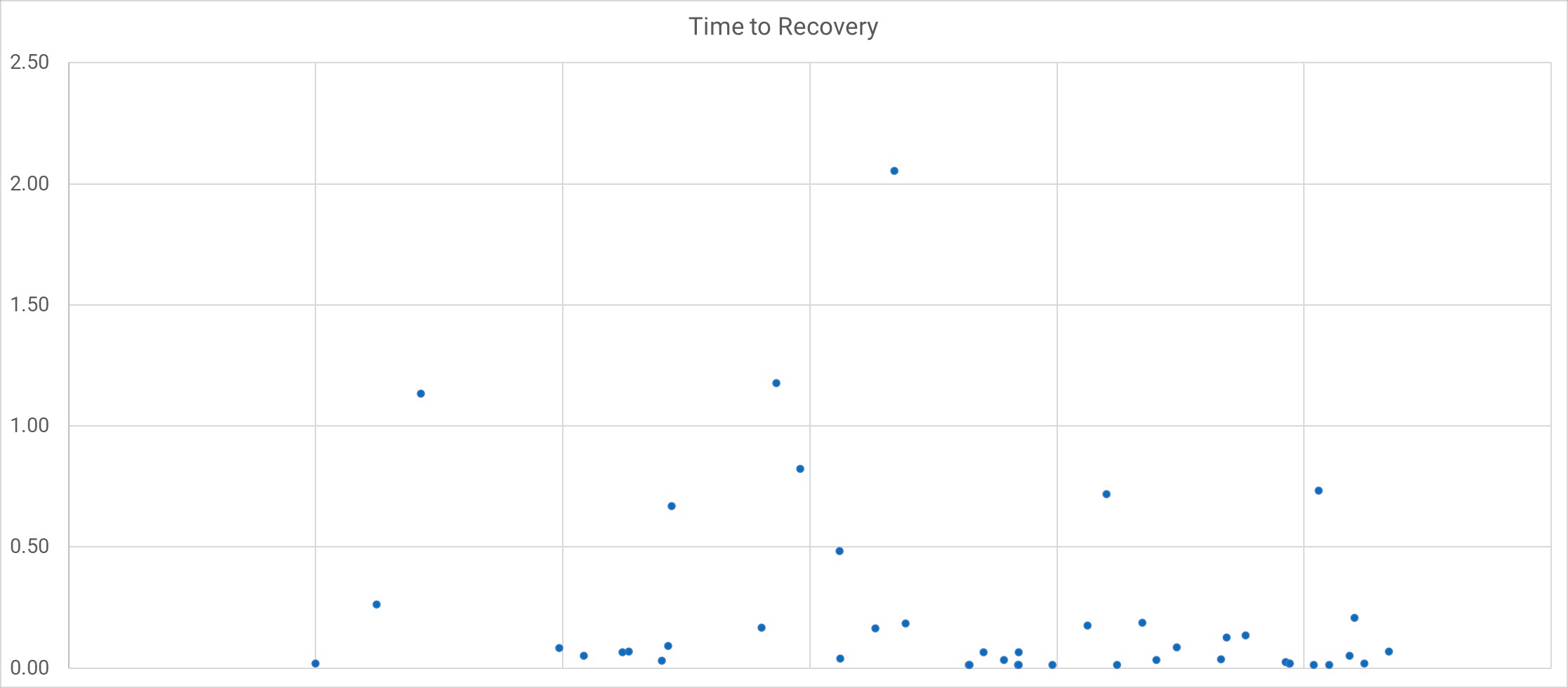
You can now understand the trend in resolution times to see if you're improving over time. You can also identify the outliers and discuss how you could handle them better. Resolution times remain useful as part of your journey into exploring incidents. Use them to improve incident management and system stability.
If incidents need a code fix, the restore time depends on your deployment pipeline's performance. Being able to quickly and safely deploy new versions of your software also helps beyond incident management.
Using restore times encourages you to introduce monitoring and alerting tools. This significantly improves your ability to detect problems before you impact customers.
Have a Clear Definition for Incidents
To get the most out of incident duration data, make sure you have consistent definitions for:
- What is an incident?
- What is the start time?
- What is the end time?
You need a clear shared definition of an incident. It should cover whether you count a fault as an incident when your system can handle it gracefully. For example, you may decide that only customer-impacting faults are incidents.
The same goes for start time and end time. Do you start the clock when the conditions causing the incident first occur or when the problem becomes visible to customers? Depending on your definition of an incident, you may end up with a negative incident duration where you resolve a fault before it impacts customers.
Agreeing on the definition of an incident and how to measure its duration makes your metrics more comparable.
When you've used DORA metrics for a long time, they may no longer inspire you to find the next level of improvement. You can design a new measurement system with the SPACE framework.
Using the SPACE Framework to Measure Incident Response
You can take a more holistic view of incident response and management using the SPACE framework. The SPACE framework groups measurements into five categories or dimensions:
- Satisfaction and wellbeing
- Performance
- Activity
- Communication and collaboration
- Efficiency and flow
You don't have to use all these metrics at once. The SPACE framework recommends using a mix of instrumented and perceptual measures across at least three dimensions. It also recommends covering individual, team, and system levels. Your goal is to create a balanced set of measurements that helps you improve the process.
1. Satisfaction and Wellbeing
Perceptual measures work best here, so survey the people managing incidents to see how happy they are with:
- The incident management process
- The on-call schedule
- How easy it is to escalate or access specialists to help during an incident.
You can also review instrumented data to determine how reasonable the on-call schedule is:
- What local times did pagers go off?
2. Performance
You can measure incident management performance using metrics such as:
- Whether systems perform against their reliability targets.
- The time between incident conditions and awareness of the incident.
- The time it takes to resolve an incident.
3. Activity
Your incident activity doesn't just have to be about the number of incidents. There are plenty of activity metrics you can use to understand incidents. You'll find most of these numbers in your existing systems:
- The number of alerts raised by monitoring tools.
- Number of incidents raised
- Number of concurrent incidents
4. Communication and Collaboration
The flow of information is crucial to incident management. You should include this dimension in your measurement strategy for incidents. Having high-quality communication will reduce the time it takes to resolve faults. You can measure:
- The number of people involved in each incident.
- How many different teams each incident involves?
- The number of chat channels opened for an incident.
- How many times do people view the incident report (or give a positive rating or reference it to other incidents)?
5. Efficiency and Flow
You'll often uncover waste in your system when you use efficiency and flow metrics. If you pass an incident around, progress stalls, and resolution takes longer. These metrics can help you spot problems:
- How often do you reassign an incident?
- The number of mitigation attempts per incident.
Incident Management SPACE Framework Summary
You should be free to build and adjust your metrics as you gain insight and improve your system. You may find it helpful to start with satisfaction, communication, and efficiency, as these will likely give you early wins.
If you already survey customers, ask them to rate your reliability.
The SPACE framework provides a way to build measurements that can directly influence your incident management more than recovery times alone.
Transitioning From MTTR
If you've been reporting meantime to recovery, you'll confuse people if you just drop it. Instead, introduce new measurements alongside MTTR to familiarize people with the new concepts. You can demote the importance of MTTR in your dashboards by moving it further away from the "top left" of the dashboard. You can eventually remove it.
The same process can help you normalize changing metrics over time. For example, if you expand from DORA metrics to the SPACE Framework.
Beyond the Numbers
Metrics are useful because they stop you from fooling yourself with convincing narratives. Without numbers, you may dismiss an incident as a one-off when it's more frequent than you thought. Phrases like "one-off," "exceptional," or "edge case" should warn you of narrative fallacy.
Despite the role numbers play, they can only tell you there's a problem, not how to solve it. You need to go beyond numbers and use incident retrospectives and reviews to work out how to improve incident management in your organization.
The numbers don't drive continuous improvement. They remind you of reality so you can apply some human ingenuity and improve things each week, forever. Use the numbers to identify and remove bias and logical fallacy from your discussions so that you can deal with the reality before you.
You should run incident retrospectives soon after each incident. This prevents you from losing vital context when the assembled team returns to their day jobs.
Be cautious about root cause analysis, as software systems rarely have a single root cause. It's usually a combination of several contributing factors. Root cause analysis focuses on the people closest to the incident, not the broader systemic issues. Aim instead for a post-incident review that details everything that happened and what you did to mitigate and solve it.
Your incident reviews can contribute directly to reducing resolution times as they capture the learning and make it available to people handling future incidents.

The cause of an incident is never a person. It's a whole system in which people work. If someone logged onto a server and accidentally selected "shut down" instead of "log out," that's a fault in the system. Why isn't the "shut down" option hidden? Why do they need to access servers directly? Can we do this with a runbook?
Periodic reviews let you review recent incidents to find patterns and think up improvements in the absence of incident adrenaline.
Learning from incidents is more important than achieving arbitrary goals around time to recover.
Conclusion
Do we want DORA to change how they measure software delivery? No. The survey collects how long it generally takes to restore service. You can answer more accurately if you adopt some of the measurements in this article. For industry analysis, this is a sensible way to gauge one of many factors in the research.
- Treat incidents as opportunities to learn.
- Favor in-depth analysis over shallow metrics.
- Treat humans as solutions, not problems.
- Study what goes right along with what goes wrong.
Happy deployments!
Published at DZone with permission of Steve Fenton. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments