How To Increase Data Quality With Memphis Schemaverse
In this article, the reader will learn about Memphis Schemaverse and discover how using Memphis Schemaverse will increase your data quality.
Join the DZone community and get the full member experience.
Join For FreeWhat Is Memphis?
Memphis{dev} is an open-source real-time data processing platform that provides end-to-end support for in-app streaming use cases using Memphis distributed message broker.
“It took me three minutes to do in Memphis what took me a week and a half in Kafka״
Memphis{dev} enables building next-generation applications that require large volumes of streamed and enriched data, modern protocols, zero ops, rapid development, extreme cost reduction, and a significantly lower amount of dev time for data-oriented developers and data engineers.
Four Critical Pillars:
- Performance – Enhanced cache usage
- Resiliency – Never lose a message and 99.95% uptime
- Observability – Out-of-the-box observability that makes sense and reduces troubleshooting time
- Developer Experience – Modularity, inline processing, schema management, gitops. Made by developers for anyone, not just developers.
Memphis’ Key Features (Current and Future):
- A distributed cloud-native message broker
- Written in Golang
- Low-code UI and CLI for both engineers, ops, and product teams
- Out-of-the-box monitoring and notification center
- DLQ
- Real-time message tracing
- Schema management, validation, and transformation
- Connectors framework made by Memphis team and the community *
- Serverless stream enrichment *
- Enhanced security and auditing
- Object tagging
Data Contracts
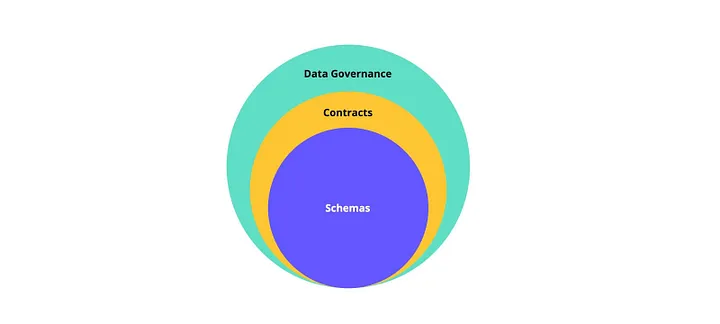
In a federated data platform, in which responsibilities are distributed between stakeholders, teams, and sources, it’s harder to control and establish a single standard. This is where the data contracts concept comes into play. Why do data contracts matter? Because (a) they provide insights into who owns what data products. (b) they support setting standards and managing your data pipelines with confidence. They also provide crucial information on what data is being consumed, by whom, and for what purpose. Bottom line: data contracts are essential for robust data management!
The very basic building block to control and ensure the quality of data that flows through your organization between the different owners is by defining well-written schemas and data models.
Why?
- Data pipelines are constantly breaking and creating data quality AND usability issues.
- There is a communication chasm between service implementers, data engineers, and data consumers.
- There are multiple approaches to solving these issues, and data engineers are still very much pioneers in exploring the frontier of future best practices.
Formats
A quick overview of the most popular formats.
- Protobuf
The modern. Protocol buffers are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler. - Avro
The popular. Apache Avro™ is the leading serialization format for record data, and first choice for streaming data pipelines. It offers excellent schema evolution. - JSON
The simplest. JSON Schema is a vocabulary that allows you to annotate and validate JSON documents.
Serialization Process
Serialization converts a data object — a combination of code and data — into a series of bytes that saves the object’s state in an easily transmittable form. The opposite process is called deserialization.
Serialization is basically represented as a function, each data format with its own implementation, and in case the structure and content of a given data do not match the defined schema in the .proto/.avro/.json struct, the serialization process fails, and therefore, the message will not be sent to the broker.
That process establishes the message’s initial validation before it reaches the broker itself, using the client cache to store the schema locally.
Memphis Schemaverse
Memphis Schemaverse provides a robust schema store and schema management layer on top of Memphis broker without a standalone compute or dedicated resources. With a unique and modern UI and programmatic approach, technical and non-technical users can create and define different schemas, attach the schema to multiple stations, and choose if the schema should be enforced or not.
Memphis’ low-code approach removes the serialization part as it is embedded within the producer library.
Schemaverse supports versioning, GitOps methodologies, and schema evolution.
Also Includes:
- Great UI and programmatic approach
- Embed within the broker
- Zero-trust enforcement
- Versioning
- Out-of-the-box monitoring
- Import & Export schemas
- Low/no-code validation and serialization
- No configuration needed
- Native support in Python, Go, Node.js
![schemaverse overview]()
![Schemas Management]()
![Partners]()
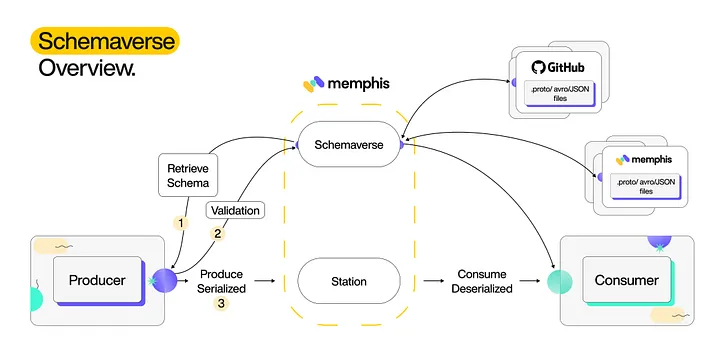
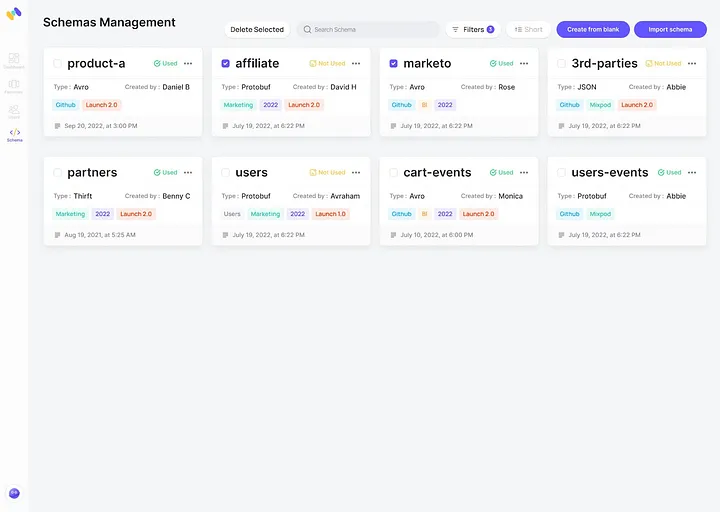
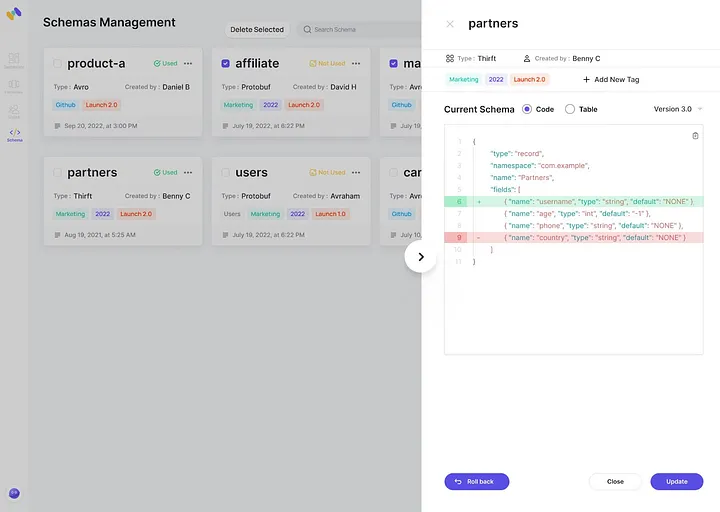
Getting Started
Step 1: Create a new schema (currently only available through Memphis GUI)


Step 2: Attach Schema
Head to your station, and on the top-left corner, click on “+ Attach schema”


Step 3: Code example in node.js
Memphis abstracts the need for external serialization functions and embeds them within the SDK.
Producer (Protobuf example):
const memphis = require("memphis-dev");
var protobuf = require("protobufjs");
(async function () {
try {
await memphis.connect({
host: "localhost",
username: "root",
connectionToken: "*****"
});
const producer = await memphis.producer({
stationName: "marketing-partners.prod",
producerName: "prod.1"
});
var payload = {
fname: "AwesomeString",
lname: "AwesomeString",
id: 54,
};
try {
await producer.produce({
message: payload
});
} catch (ex) {
console.log(ex.message)
}
} catch (ex) {
console.log(ex);
memphis.close();
}
})();Consumer (Requires .proto file to decode messages):
const memphis = require("memphis-dev");
var protobuf = require("protobufjs");
(async function () {
try {
await memphis.connect({
host: "localhost",
username: "root",
connectionToken: "*****"
});
const consumer = await memphis.consumer({
stationName: "marketing",
consumerName: "cons1",
consumerGroup: "cg_cons1",
maxMsgDeliveries: 3,
maxAckTimeMs: 2000,
genUniqueSuffix: true
});
const root = await protobuf.load("schema.proto");
var TestMessage = root.lookupType("Test");
consumer.on("message", message => {
const x = message.getData()
var msg = TestMessage.decode(x);
console.log(msg)
message.ack();
});
consumer.on("error", error => {
console.log(error);
});
} catch (ex) {
console.log(ex);
memphis.close();
}
})();Published at DZone with permission of Idan Asulin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments