How To Build a Low-Latency Video Streaming App With ScyllaDB NoSQL and NextJS
We created a new video streaming app to help you learn ScyllaDB. This article covers its features, tech stack, and data modeling.
Join the DZone community and get the full member experience.
Join For FreeWe just published a new ScyllaDB sample application, a video streaming app. The project is available on GitHub. This blog covers the video streaming application’s features and tech stack and breaks down the data modeling process.
Video Streaming App Features
The app has a minimal design with the most essential video streaming application features:
- List all videos, sorted by creation date (home page)
- List videos that you started watching
- Watch video
- Continue watching a video where you left off
- Display a progress bar under each video thumbnail
Technology Stack
- Programming language: TypeScript
- Database: ScyllaDB
- Framework: NextJS (pages router)
- Component library: Material_UI
Using ScyllaDB for Low-Latency Video Streaming Applications
ScyllaDB is a low-latency and high-performance NoSQL database compatible with Apache Cassandra and DynamoDB. It is well-suited to handle the large-scale data storage and retrieval requirements of video streaming applications. ScyllaDB has drivers in all the popular programming languages, and, as this sample application demonstrates, it integrates well with modern web development frameworks like NextJS.
Low latency in the context of video streaming services is crucial for delivering a seamless user experience. To lay the groundwork for high performance, you need to design a data model that fits your needs. Let’s continue with an example data modeling process to see what that looks like.
Video Streaming App Data Modeling
In the ScyllaDB University Data Modeling course, we teach that NoSQL data modeling should always start with your application and queries first. Then, you work backward and create the schema based on the queries you want to run in your app. This process ensures that you create a data model that fits your queries and meets your requirements.
With that in mind, let’s go over the queries that our video streaming app needs to run on each page load!
Page: Continue Watching
On this page, you can list all the videos that they’ve started to watch. This view includes the video thumbnails and the progress bar under the thumbnail.
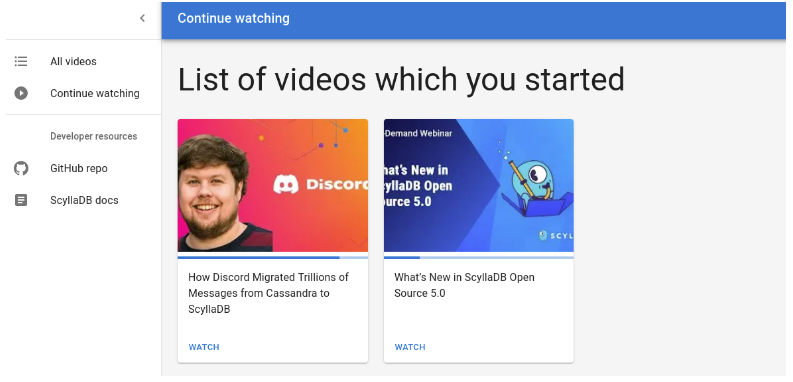
Query: Get Watch Progress
SELECT video_id, progress FROM watch_history WHERE user_id = ? LIMIT 9;Schema: Watch History Table
CREATE TABLE watch_history (
user_id text,
video_id text,
progress int,
watched_at timestamp,
PRIMARY KEY (user_id)
);For this query, it makes sense to define user_id as the partition key because that is the filter we use to query the watch history table. Keep in mind that this schema might need to be updated later if there is a query that requires filtering on other columns beyond the user_id. For now, though, this schema is correct for the defined query.
Besides the progress value, the app also needs to fetch the actual metadata of each video (for example, the title and the thumbnail image). For this, the `video` table has to be queried.
Query: Get Video Metadata
SELECT * FROM video WHERE id IN ?;Notice how we use the “IN” operator and not “=” because we need to fetch a list of videos, not just a single video.
Schema: Video Table
CREATE TABLE video (
id text,
content_type text,
title text,
url text,
thumbnail text,
created_at timestamp,
duration int,
PRIMARY KEY (id)
);For the video table, let’s define the id as the partition key because that’s the only filter we use in the query.
Page: Watch Video
If you click on any of the “Watch” buttons, they will be redirected to a page with a video player where they can start and pause the video.
![Page: Watch Video]() Query: Get Video Content
Query: Get Video Content
 Query: Get Video Content
Query: Get Video ContentSELECT * FROM video WHERE id = ?;This is a very similar query to the one that runs on the Continue Watching page. Thus, the same schema will work just fine for this query as well.
Schema: Video Table
CREATE TABLE video (
id text,
content_type text,
title text,
url text,
thumbnail text,
created_at timestamp,
duration int,
PRIMARY KEY (id)
);Page: Most Recent Videos
Finally, let’s break down the Most Recent Videos page, which is the home page of the application. We analyze this page last because it is the most complex one from a data modeling perspective. This page lists ten of the most recently uploaded videos that are available in the database, ordered by the video creation date.
We will have to fetch these videos in two steps: first, get the timestamps, then get the actual video content.
Query: Get the Most Recent Ten Videos’ Timestamp
SELECT id, top10(created_at) AS date FROM recent_videos;You might notice that we use a custom function called top10(). This is not a standard function in ScyllaDB. It’s a UDF (user-defined function) that we created to solve this data modeling problem. This function returns an array of the most recent created_at timestamps in the table. Creating a new UDF in ScyllaDB can be a great way to solve your unique data modeling challenges.
These timestamp values can then be used to query the actual video content that we want to show on the page.
Query: Get Metadata for Those Videos
SELECT * FROM recent_videos WHERE created_at IN ? LIMIT 10;Schema: Recent Videos
CREATE MATERIALIZED VIEW recent_videos_view AS
SELECT * FROM streaming.video
WHERE created_at IS NOT NULL
PRIMARY KEY (created_at, id);In the recent videos' materialized view, the created_at column is the primary key because we filter by that column in our first query to get the most recent timestamp values. Be aware that, in some cases, this can cause a hot partition.
Furthermore, the UI also shows a small progress bar under each video’s thumbnail which indicates the progress you made watching that video. To fetch this value for each video, the app has to query the watch history table.
Query: Get Watch Progress for Each Video
SELECT progress FROM watch_history WHERE user_id = ? AND video_id = ?;Schema: Watch History
CREATE TABLE watch_history (
user_id text,
video_id text,
progress int,
watched_at timestamp,
PRIMARY KEY (user_id, video_id)
);You might have noticed that the watch history table was already used in a previous query to fetch data. Now this time, the schema has to be modified slightly to fit this query. Let’s add video_id as a clustering key. This way, the query to fetch watch progress will work correctly.
That’s it. Now, let’s see the final database schema!
Final Database Schema
CREATE KEYSPACE IF NOT EXISTS streaming WITH replication = { 'class': 'NetworkTopologyStrategy', 'replication_factor': '3' };
CREATE TABLE streaming.video (
id text,
content_type text,
title text,
url text,
thumbnail text,
created_at timestamp,
duration int,
PRIMARY KEY (id)
);
CREATE TABLE streaming.watch_history (
user_id text,
video_id text,
progress int,
watched_at timestamp,
PRIMARY KEY (user_id, video_id)
);
CREATE TABLE streaming.recent_videos (
id text,
content_type text,
title text,
url text,
thumbnail text,
created_at timestamp,
duration int,
PRIMARY KEY (created_at)
);User-Defined Function for the Most Recent Videos Page
-- Create a UDF for recent videos
CREATE OR REPLACE FUNCTION state_f(acc list<timestamp>, val timestamp)
CALLED ON NULL INPUT
RETURNS list<timestamp>
LANGUAGE lua
AS $$
if val == nil then
return acc
end
if acc == nil then
acc = {}
end
table.insert(acc, val)
table.sort(acc, function(a, b) return a > b end)
if #acc > 10 then
table.remove(acc, 11)
end
return acc
$$;
CREATE OR REPLACE FUNCTION reduce_f(acc1 list<timestamp>, acc2 list<timestamp>)
CALLED ON NULL INPUT
RETURNS list<timestamp>
LANGUAGE lua
AS $$
result = {}
i = 1
j = 1
while #result < 10 do
if acc1[i] > acc2[j] then
table.insert(result, acc1[i])
i = i + 1
else
table.insert(result, acc2[j])
j = j + 1
end
end
return result
$$;
CREATE OR REPLACE AGGREGATE top10(timestamp)
SFUNC state_f
STYPE list<timestamp>
REDUCEFUNC reduce_f;This UDF uses Lua, but you could also use Wasm to create UDFs in ScyllaDB. Creating the function make sure to enable UDFs in the scylla.yaml configuration file (location: /etc/scylla/scylla.yaml):
Clone the Repo and Get Started!
To get started…
Clone the repository:git clone https://github.com/scylladb/video-streaming
Install the dependencies:npm install
Modify the configuration file:
APP_BASE_URL="http://localhost:8000"
SCYLLA_HOSTS="172.17.0.2"
SCYLLA_USER="scylla"
SCYLLA_PASSWD="xxxxx"
SCYLLA_KEYSPACE="streaming"
SCYLLA_DATACENTER="datacenter1"Migrate the database and insert sample data:npm run migrate
Run the server:npm run dev
Wrapping Up
We hope you enjoy our video streaming app, and it helps you build low-latency and high-performance applications with ScyllaDB. If you want to keep on learning, check out ScyllaDB University, where we have free courses on data modeling, ScyllaDB drivers, and much more! If you have questions about the video streaming sample app or ScyllaDB, go to our forum, and let’s discuss!
More ScyllaDB sample applications:
Relevant resources:
Published at DZone with permission of Attila Toth. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments