How To Build a Basic RAG App
This article will guide you on starting out with Retrieval-Augmented Generation with LLMs. You will learn what RAG is and how to implement it in your application.
Join the DZone community and get the full member experience.
Join For FreeThe dawn of Generative AI makes possible new kinds of capabilities for the applications we build. LLMs can answer the user’s questions with incredible skill. So, why not use them as part of our systems? If the user needs help getting around the app, we can put a chat function where the LLM will answer all the user’s questions. If our app has blog posts explaining important concepts, instead of making the user read all of them to get the knowledge it needs, it could just ask and get an immediate response.
Why RAG?
We decide to integrate an LLM into our app to bring these features to our users. However, we soon find that the model can’t answer the user’s questions. It doesn’t have any information about our application! If the information needed to answer is not in the LLM’s training data, it can’t be answered. Even worse, if it doesn’t know the answer, it might hallucinate a completely wrong fact! This is bad, so how do we fix this? LLMs with the Transformer architecture have shown great in-context learning capabilities. So, we just have to pass all the facts that it needs in the prompt, together with the question! Uh oh, it will definitely be expensive to stuff all the data in every prompt. So, how do we do it?
What Is RAG?
RAG stands for Retrieval Augmented Generation. RAG was born together with Transformers. Initially, it was used to augment the pre-training data of LLMs with additional facts. Once Transformers’ in-context learning capabilities became obvious, it became a common practice also during inference, to augment the prompt.
A basic RAG pipeline consists of three steps: indexing, retrieval, and generation. All the information that the LLM needs to answer is indexed in a vector database. When the user asks a question, we can retrieve the relevant parts of the information from that vector database. Finally, together with just the relevant information and the user’s question, we can prompt the LLM to give an answer based on the information we give it as a context. Let’s look in more detail at how to achieve this.
Indexing
First, we extract the information that the model needs from wherever it is. Generative models work with plain text (some models can also work with images or other formats, which can also be indexed, but this is a topic for another time). If the information is already in plain text, we are in luck. But it might also be in PDF documents, Word documents, Excel, Markdown, etc. We must convert this data to plain text and clean it so it can be usable for the model.
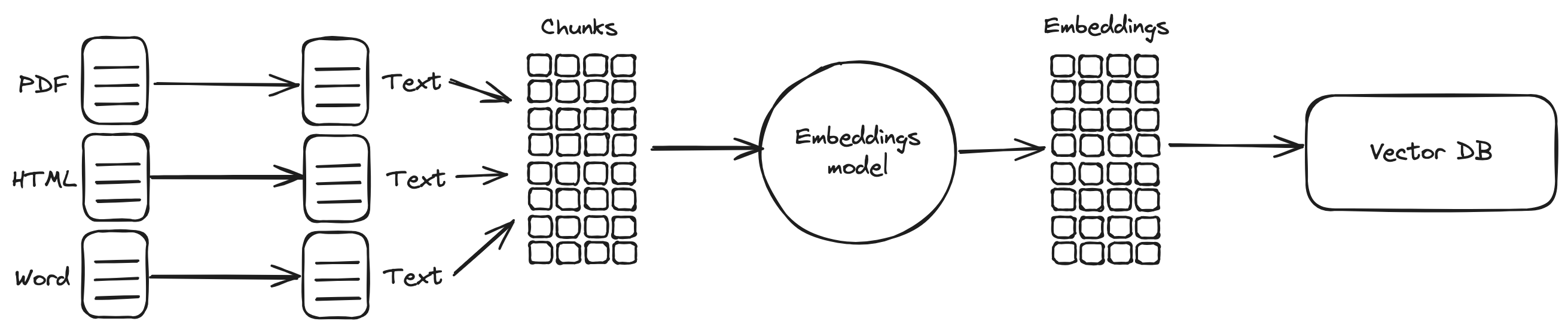
Once the information is in text format, we can store it in a vector database. The vector database will store the embedding representation of that text. That will allow us to search for parts of the text that have a similar embedding representation as another text, therefore they are about a similar concept. We will divide the whole text into smaller parts or chunks, calculate the embedding representation for each of them, and finally store them in the vector database.
Retrieval
When the user asks us a question, we can convert that question into a vector representation, using the same embedding model we used to index the data. With that vector representation, we will calculate the similarity factor between the question and each one of the chunks stored in the vector database. We will select the top K chunks that are the most similar to the query, and therefore their contents are about the same concept as the question (and therefore they might contain the answer).

Generation
A prompt is built, putting together the user’s question and the relevant contexts to help the LLM answer. We might also include previous messages from the conversation between the user and the AI assistant. The LLM generates an answer for the user based on the context, instead of its previously learned pre-training data.

Example
For this example, we will ingest a paper called “Retrieval-Augmented Generation for Lange Language Models: A Survey.” We will query the LLM using the information contained in this paper, so it can answer the user’s questions on its contents. You can follow this example in the Google Colab notebook provided for this article.
First, we will load the PDF document and parse it using LangChain’s PyPDF connector.
Once we have the text from the document, we have to split it into smaller chunks. We can use LangChain’s available splitters, like RecursiveCharacterSplitter in this case:
We will be using BGE-small, an open-source embedding model. We will download it from HuggingFace Hub and run it on all chunks to calculate their vector representations.
Once we have the vector representations for all chunks, we can create an in-memory vector database and store all vectors in it. For this example, we will be using a FAISS database.

The database is now set up. Now, we will be taking queries from the user on this information. In this case, the user asks which are the drawbacks of Naive RAG. We encode this query using the same embedding model as before. Then, we retrieve the top 5 most similar chunks to that query.

After retrieving the relevant context, we build a prompt using this information and the user’s original query. We will use Claude’s Haiku as a LLM for this example:

Common Problems and Pitfalls
As the title implies, this solution is a basic or naïve RAG implementation. It will empower your application to make the most out of the LLM it’s using and your data. But it won’t work for all cases. These are just some of the most common problems with RAG:
- Retrieve irrelevant information: If the retriever gets data from the vector database that is not relevant to the question, it will confuse the model trying to answer the question. This might lead to either not using the context to answer the question or answering something different than what was asked.
- Miss important information: Maybe the information it needs to answer the question is not in the database. Maybe the retrieval mechanism fails to find the relevant chunks. We must find ways to help the retriever find the information it needs easily and more reliably.
- Generate responses not supported by the context: If the context has the information the model needs, but it doesn’t use it and instead relies on its own pre-training data, all this was for nothing. The information from the pre-training data might be outdated or wrong. We must favor the model to always use the context to answer, or answer “I don’t know” if it can’t answer from the context.
- Irrelevant response to the query: The LLM might use all the information that you give it to generate a response, but that doesn’t mean that it answers the user’s question. It’s important that the model sticks to the user’s original question, instead of getting lost in a ton of information.
- Redundant response caused by similar contexts: When we ingest multiple documents with similar information, there’s a chance that the retriever will get multiple chunks of information that say almost the same. This might cause the LLM to repeat the same information more than one time in its response.
How To Avoid These Problems
To avoid these problems, a naïve RAG pipeline might not be enough. We will need to set up a more advanced and complex RAG system. There exist tested techniques to solve the problems we have laid out. We can incorporate them into our RAG pipeline to improve the RAG application’s performance.
Another important point to address is that to improve your RAG application, you will need to be able to measure and evaluate the whole process. You can’t improve what you can’t measure. Plus, when you evaluate you might find that a basic RAG setup is enough for your use case, and you don’t need to overcomplicate it. After all, even a very basic RAG implementation can improve your LLM-powered application enormously.
In future articles, I will explain in more detail the advanced RAG techniques that will help us avoid common problems and bring our RAG applications to the next level.
Published at DZone with permission of Roger Oriol. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments