How to Become a Data Engineer: A Hype Profession or a Necessary Thing
This article will tell you how a Data Engineer helps turn pure numbers into insights and why developers should look at this direction too.
Join the DZone community and get the full member experience.
Join For Free“Big Data is the profession of the future” is all over the news. I will say even more: data engineering skills for a developer is an urgent need. Before 2003, we had created as many petabytes of data as we do today every two days. Gartner analysts named cloud services and cybersecurity among the top techno trends of 2021.
The trend is easily explained. Huge arrays of Big Data need to be stored securely and processed to obtain useful information. When the companies moved to remote work, these needs have become even more tangible. E-commerce, Healthcare, EdTech — all these industries want to know everything about their online consumers. While the data is only stored on the servers, there is no sense in it at all.
Do I Have Data?
Clean, structure, conver — these are the basic operations of Data Engineering. The professional should know how to combine data of different formats, collected from several sources. I have been programming with Python for three years, of which I have been immersed in Big Data for two years. From personal experience, I realized that for daily work you need to be able to do more.
Basically, a Data Engineer is a combination of four roles:
Software Engineer. Writes code, tests and optimizes it. In my opinion, the simplest path to Data Engineering is Software Engineering. This specialist knows how a computer and programs are arranged. He/she is familiar with the development of high-quality software and working with databases.
Big Data Developer. Understands the principles of data processing, uses various tools to transform them. He prepares a description of data models depending on the client's request or business processes.
Database Administrator. Building a storage architecture is placed on his shoulders. Knows how to store data in the best way and perform basic operations on it.
Cloud Engineer. The volumes of data today are so massive that it is too expensive or impossible to store them on servers - it simply does not fit there. Cloud solutions are there for you. This engineer understands what cloud solutions are, what their structure and specific features are, how they interact with each other, and how to set up cloud services.
From any of these positions, you can switch to Data Engineering.
Data Engineer, Data Scientist or Data Analyst: Who’s the Coolest?
This trio of specialists is deeply data-driven. Each one has his own responsibilities. The Data Engineer receives a request from colleagues to find relevant data in order to find out the effectiveness of a new feature, for example. The engineer pulls specific data from different sources (server, application or cloud), simplifies, processes it and loads it into the right storage. From there, Data Analyst takes it - analyzes the information and translates it into a format understandable to the client. This could be a report, infographic, presentation. The specialist sees the connection between the found indicators and compares them. When you need to predict a patient condition or a market dynamic, a Data Scientist is needed. Let's take an example of how all roles collaborate in a project.
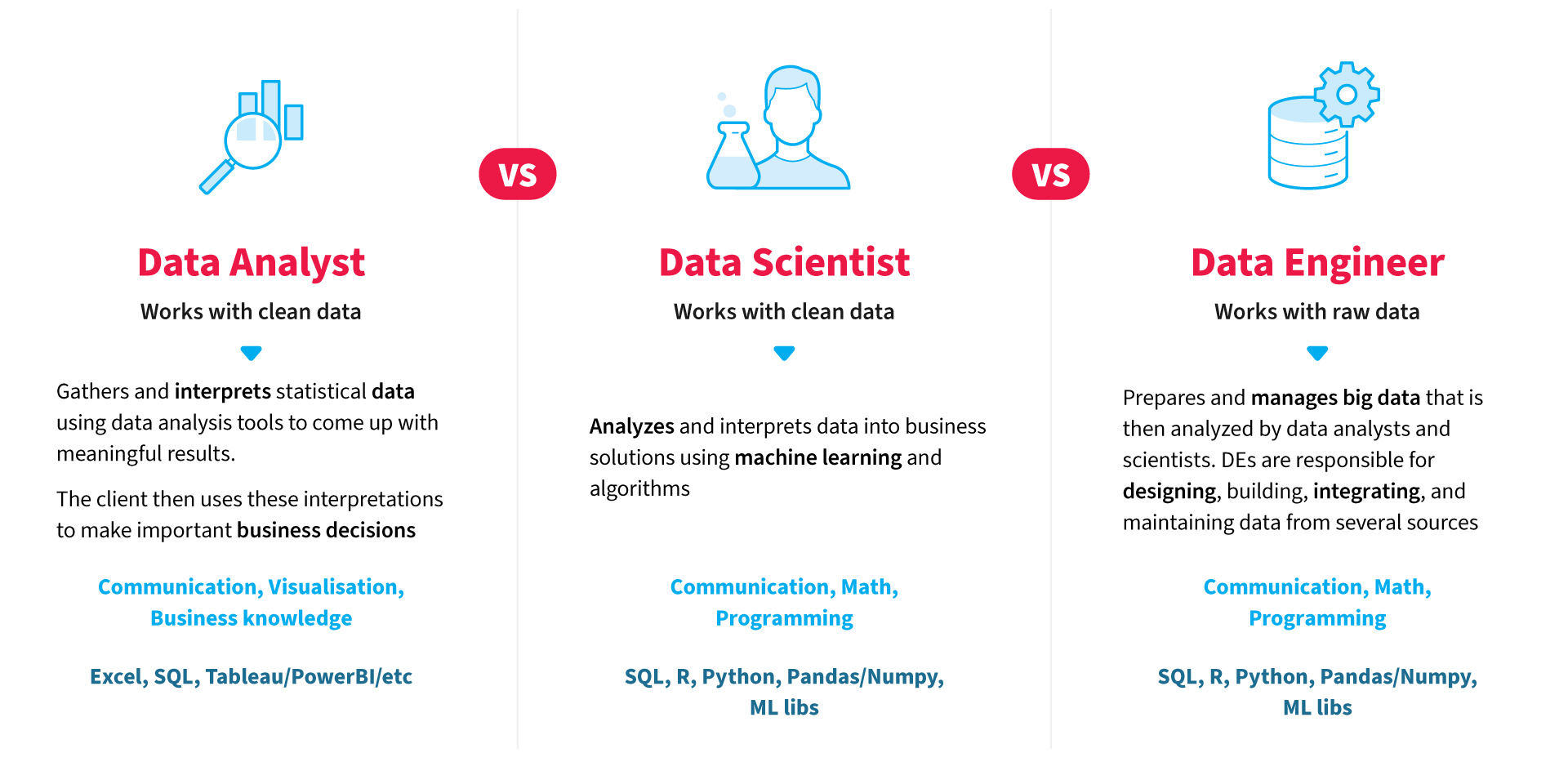
Imagine a regular social network for learning foreign languages. People find penpals and practice English, German, Chinese, etc. Millions of daily users leave digital traces: they log in via their personal mail, buy premium accounts, download the application, and make calls via video. Every click is registered and sent to the server. The company wants to track the effectiveness and profitability of the platform. How can a Data Engineer help with this? Personally, he cannot. But with colleagues like Data Scientists and Data Analysts, the data he found turns into useful information — statistics, infographics, and forecasts.
This is not to say that some of them are more useful, do more work, or better copes with responsibilities. The scope of their tasks may indeed differ and depends on the tasks set by the client. The only thing is that the Data Engineer seems to be working in the "shadow." If you are sociable and know how to communicate with customers, it is worth looking into the profession of an Analyst or a Data Scientist. But it's up to you, of course.
In any case, without an engineer, the team has a harder time working with raw data. With him they take clean and optimized data from storage. All they have to do is to calculate statistics, discover trends, and predict results. Working together as a trio is much more effective than doing everything alone.
Working With Data: What Do Data Engineers Do?
There are different data sources. The task of an engineer is to get information from them, unify data from different sources, process and, upon request, simplify and diversify them. We send a query written in Structured Query Language to the database. SQL is the most widely used data manipulation language. Therefore, many tools use the already familiar syntax. For example, Apache Hive or Impala.
To change the data, you need special frameworks. Apache Spark, Apache Flink, and Hadoop MapReduce allow you to perform the following types of transformations:
- Data cleaning
- Removal of duplicates
- Converting data types (string to number or date)
- Filtration
- Data joins
- Data derivation
Some frameworks are suitable only for processing streaming data; others are exclusively for data that has been stored on the service for a long time. Some can do both. Say we need to remove unnecessary records and fill in the missing values. This is usually done by prepared scripts. Not all frameworks have the ability to write scripts in the language the engineer wants.
Usually, Python, Java and Scala programming languages are used to transform data. Hadoop, HDFS, Apache Cassandra, HBase and Apache Hive are built in Java. On Scala, Apache Kafka and Apache Spark. In Python, Pandas/NumPy. Dask + wrappers are for frameworks written in other languages (PyFlink, PySpark, Python Hadoop API).

To structure everything, there are two approaches: ETL and ELT. If we work with a small volume or with databases of ready-made data from different clients, it is more convenient to use ETL. If there is a lot of mixed information, ELT will do better. In this case, we first load the data into the storage, transform it on a separate server, and, if necessary, pull it out.
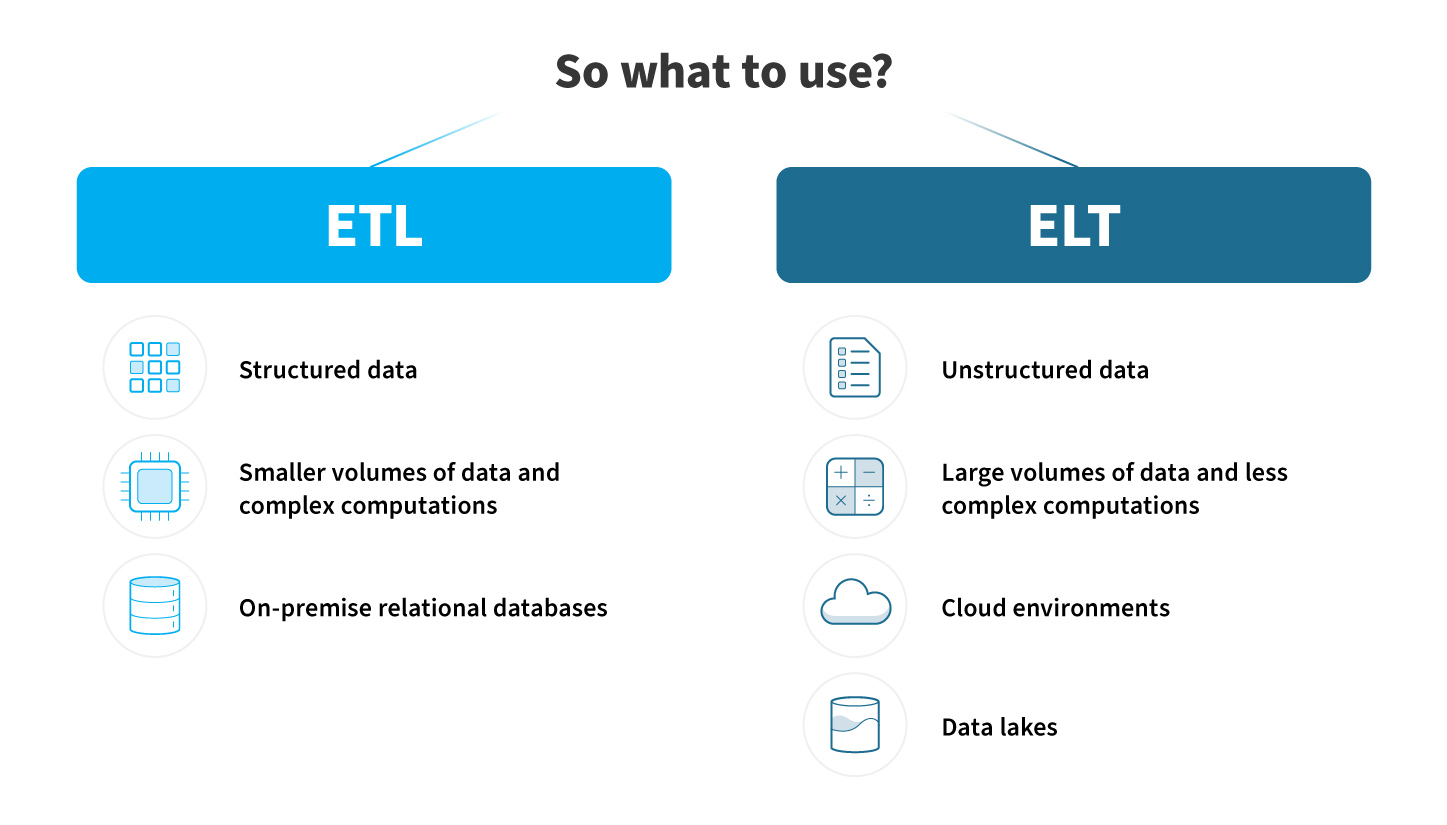
The final data goes to the data warehouse or data lakes. We set up delivery via an SQL request or a custom script included in the external service API. Next comes Data Analyst and Data Scientist. They form useful information based on the data. The first one creates reports, graphs and finds patterns in the data, the second one makes predictions using Machine Learning approaches.
Data Engineering Skills: What Is So Useful?
You will definitely have work to do. The amount of data will only grow. You will need to clean them, arrange them, analyze them. Knowing the basics of Data Engineering is useful for at least the following purposes.
Find and Organize Data
Information about user profiles, purchases, the number of clicks in the application on different devices — all this is collected by an engineer and grouped by content. If a company is making plans for the next year and wants to know the expected growth of the business, Data Scientist and Analyst join the Engineer’s team. Based on the information collected by the engineer, they find out in which niche, and why sales are falling, which products or features are the most popular.
Increase Data Delivery Speed
Increase the speed of data delivery to the target system or to the target user. The speed depends on the choice of framework, approach and service. For example, Hadoop MapReduce is more cost-efficient than Spark, but the processing speed is slower. If we have streaming data, it's more convenient and faster to process it on the fly, instead of saving it to disk and processing it later.
Reduce Storage Costs
In the 80s, 1 GB of HDD space cost $500,000, and now it’s only $0.025. Since then, data volumes have grown hundreds of times, and hard drives can't handle them. It is more convenient and safer to store information on the cloud. Terabytes on the service will cost from several tens to hundreds of dollars per month. Experts can choose the most profitable service and tariff plan for the client.
Big Data Is the "Fuel" of the XXI Century
If we discard all the data, the development of mankind will be approximately down to the level of the 18th century. We still bake bread, use public and personal transport, heal people, just like our ancestors. Using Big Data allows you to sell even more bread, optimize traveling, and accelerate scientific and other discoveries.
No matter if you are a large corporation with a long history, or a feisty but small startup — it is useful for everyone to deal with data. For ordinary users, this does not mean anything, but for business it is very important. When, for instance, sales fall, it will be enough to pull the necessary information from the storage and find out the reason. With data and their processing capabilities, we gain new knowledge. Any industry only benefits from this.
If you are interested in data engineering, I recommend the following resources. This is the base that will help you understand the theory and improve the skills necessary to work with data:
Opinions expressed by DZone contributors are their own.
Comments