How Slow Is Database I/O?
Perform a field test to find out the performances of retrieving data from Oracle and MySQL and compare them with the performance of retrieving data from the text file.
Join the DZone community and get the full member experience.
Join For FreeMost veteran developers must have experienced a rather low database I/O performance. However, many may not have a full understanding of how slow the I/O operation is, particularly about the gap between database I/O speed and the speeds of other data read/write methods.
Java is a commonly used technique used for application development. In this article, we perform a field test to find out the performances of retrieving data from Oracle and MySQL – the two typical types of databases in Java, and compare them with the performance of retrieving data from the text file.
Use the international T-PCH benchmark to generate data tables and select the customer table, which has 30,000,000 rows and 8 fields. The size of the original text file is 4.9G. Import the file data to Oracle and MySQL, respectively.
The hardware environment consists of a single, 2-CPU, and 16-core server where both the text file and the database are stored in the SSD. The whole test is performed on the local machine, and there isn’t any substantial network transmission time.
As it is complicated to implement the test using Java, we write the code in SPL. SPL simply encapsulates Java’s data retrieval operation. Data is retrieved through the database’s JDBC driver, and performance won’t be affected. Here, the complete retrieval operation involves retrieving data via the SPL cursor and converting all data into in-memory objects.
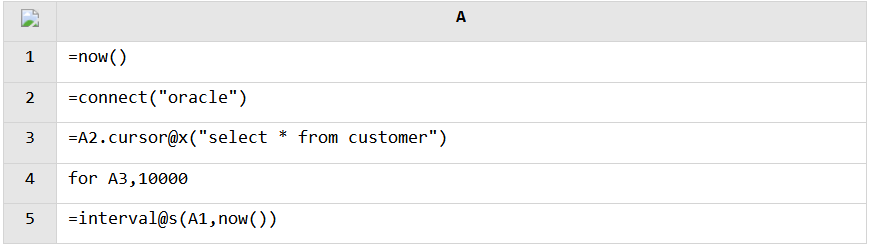
It takes Oracle 280 seconds, an average of 100,000 rows per second, and MySQL 380 seconds, an average of 80,000 rows per second averagely, to retrieve all the 30,000,000 rows from the table.
The retrieval speed depends on both the number of fields and the data type used, as well as the hardware environment. This means that this test result is only a reference and can be quite different in various environments.
But the comparison is reliable under the same environment. We still use SPL to directly retrieve a TPCH-generated text file:

Like we perform the test using the database, here we use SPL cursor to retrieve data and then convert the data to in-memory objects. It takes 42 seconds to complete the retrieval of 30,000,000 rows of data. This is over 6 times faster than Oracle and 9 times faster than MySQL!
We know that text parsing is rather complex and has a high CPU consumption degree. But even so, retrieving data from a text file is still far faster than data retrieval from the database.
Now, let’s test data retrieval from a binary file and find out to what extent the performance will be dragged down during the text parsing.
In order to create obvious contrast and make the later parallel processing test more convenient, we use the larger orders table that has three hundred million rows of data and nine fields. The code for retrieving data from the text file is similar to the previous one, and it takes 483 seconds to complete the execution.
Now we convert the current text file into a SPL composite table file and test the retrieval speed:
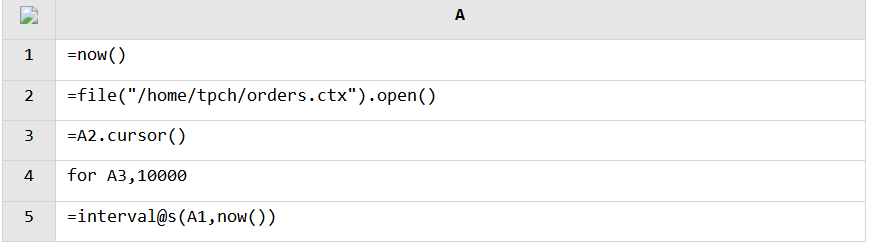
It takes 164 seconds to retrieve all data from the composite table file, which is 3 times faster than retrieving data from the text file.
It is just what we expect because binary data does not need to be parsed and can be directly used to generate objects. The computation amount is less, and the speed becomes faster.
However, databases also use the binary format to store data and do not have the burden of text parsing. It is natural that they are not as fast as the more compact SPL composite tables, as databases should consider data writing and cannot use the compression technique. But it is a little bit perplexed about their being slower than text files.
Actually, we find that databases are fast when SQL is used to perform a traversal-based aggregate operation on the above data table and returns a very small result set, much faster than when we perform the same operation based on a text file. This means that traversing a data table in the database is not slow at all, or we can say the data storage format has a fairly good performance.
The obstacle lies in the driver. The JDBC driver is extremely slow. We even doubt that this is an intentional design, which expects and even forces data not to be retrieved out of the database but to be computed inside it.
In view of this, we have come to a conclusion — when we want to achieve high performance for big data computations, ad hoc data retrieval from the database is infeasible, and it would be best to perform the computation inside the database. If data must be first retrieved from the database before the computation can be really handled (because sometimes it is difficult or even impossible to implement some computing logic in SQL), we’d better not store data in the database. If data is still kept in the database, performance won’t be satisfactory in most cases, no matter what high-performance algorithms we use outside the database, unless the amount of data involved is very small.
This is why SPL must implement its own storage formats if it intends to improve SQL’s computing performance. It is impossible to achieve high performance if SPL still uses database storage.
Is there any way to increase the computing speed when the database is the only data source?
If the problem only lies in the slow driver, that is, the slow speed isn’t due to heavy database load, we can improve the situation using parallel processing.
It is a little bit complicated to implement the multithreaded computation in Java, so we perform a test by using SPL to write the parallel retrieval code:

Note that the parallel threads should not share the same database connection; instead, each of them should connect to the database separately.
The field test shows that when the number of parallel threads is small (generally <10), the computing efficiency goes up nearly in a linear way. This means that the retrieval speed becomes nearly n times faster when there are n retrieval threads. The test result is that speed increase reaches 5 times with 6-thread parallel processing.
Here, we need to first compute the total number of data rows and then write the WHERE condition for each thread to retrieve the corresponding part of data, placing many computing actions on the database while still leading to a noticeable retrieve performance increase. This further tells that the slow speed is mainly due to the slow driver rather than the in-database retrieval and computations.
Of course, it is more convenient to use multithreaded processing to increase the speed when data is stored in files. It is easy for SPL to implement the parallel computation:
Parallel retrieval from the text file:
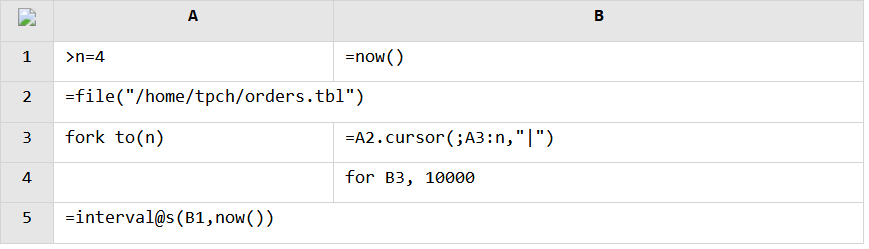
Parallel retrieval from the composite table file:
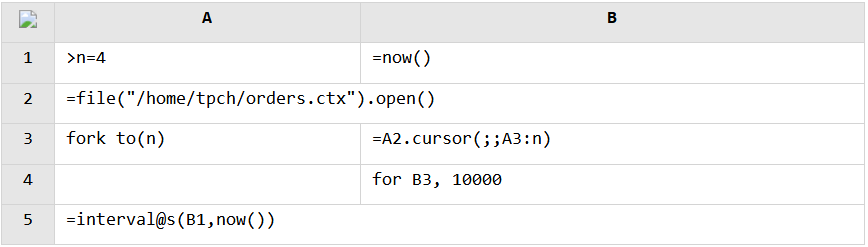
The field test result is similar to when data is stored in the database. A linear speed increase is obtained when the number of parallel threads is small. In the test, the 4 threads make text file retrieval 3.6 times faster and composite table data retrieval 3.8 times faster.
Published at DZone with permission of Judy Liu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments