HBase, Phoenix, and Java — Part 2
Find out the advantages, limitations, features, and the architecture of Apache Phoenix.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
While RDBMS (Relational Database Management systems) have been popular for decades (and will continue to remain so), in recent time, we have seen the emergence and acceptance of databases/datastores that are not based on relational technology concepts. Such databases are typically called NoSQL, with the team initially meaning "Not SQL," but has come to mean "Not only SQL." When the NoSQL database was released, they did not support the popular SQL interface. Each of the databases had their own API for data access and manipulation, but with the passage of time, a few solutions were developed on top of existing NoSQL databases that supported the SQL interface. For example, the Hive datastore was created on top of HDFS (Hadoop Distributed File System) to provide a "table-like" interface to data and it supports many features of SQL 92. Similarly, though HBase is a column store, an SQL interface was defined. This interface is Phoenix.
When news reporters write about Non-Resident Indians or about Americans of Indian origin (or for that matter, any person of Indian origin, now settled in another country), they use the phrase “You can take the XYZ out of India, but you cannot take India out of XYZ.” Looking at the SQL interfaces provided for NoSQL databases, I would like to coin the phrase, “You can take a programmer out of SQL, but you cannot take SQL out of the programmer.”
Apache Phoenix
Phoenix is an open source SQL skin for HBase. You use the standard JDBC APIs instead of the regular HBase client APIs to create tables, insert data, and query your HBase data. It enables OLTP and operational analytics in Hadoop for low latency applications by combining the best of both worlds:
- the power of standard SQL and JDBC APIs with full ACID transaction capabilities
- the flexibility of late-bound, schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store
Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce. It takes an SQL query, compiles it into a series of HBase scans, and orchestrates the running of those scans to produce regular JDBC result sets. Direct use of the HBase API, along with coprocessors and custom filters, results in performance on the order of milliseconds for small queries, or seconds for tens of millions of rows.
Place in the Hadoop ecosystem:
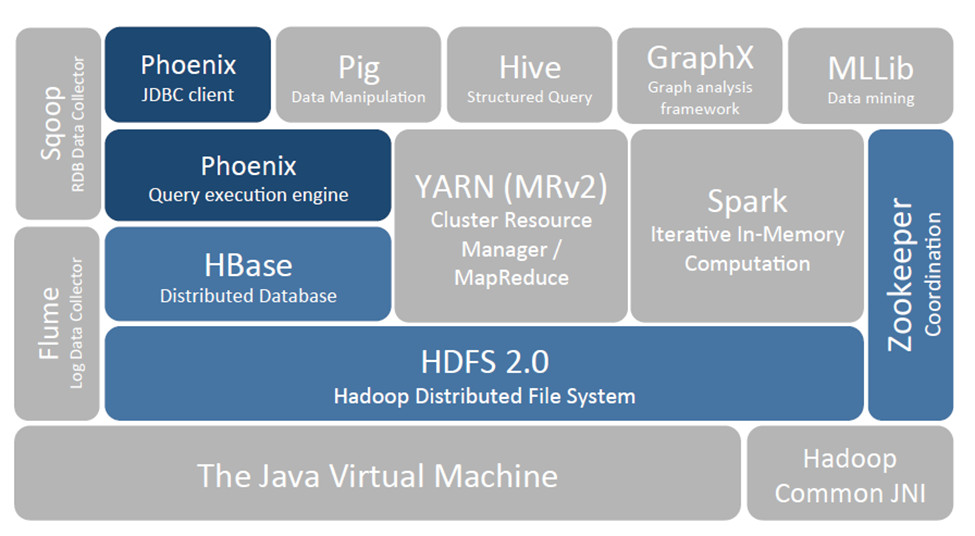 Figure 1: Phoenix and HBase in the Hadoop Ecosystem
Figure 1: Phoenix and HBase in the Hadoop Ecosystem
At first glance, given that Phoenix is an SQL skin on top of HBase, it is assumed that using it will result in slower access as compared to direct HBase API access, but in most cases, it has been noted that Phoenix achieves as good or likely better performance than if we hand-coded it ourselves (in addition to the advantage of reduced code development). This is achieved by:
- compiling SQL queries to native HBase scans
- determining the optimal start and stop for the scan key
- orchestrating the parallel execution of scans
- bringing the computation to the data by
- pushing the predicates in the where clause to a server-side filter
- executing aggregate queries through server-side hooks (called co-processors)
Advantages of Phoenix
One of the biggest advantages of using Phoenix is that it provides access to HBase using an interface that most programmers are familiar with, namely SQL and JDBC. Some of the other advantages of using Phoenix are:
- Reduces the amount of code users need to write
- Allows for performance optimizations transparent to the user
- Opens the door for leveraging and integrating lots of existing tooling
Architecture
Architecturally, Phoenix works by using two components, namely a server component and a client component. The client component is nothing but the Phoenix JDBC driver and is used by each client that connects to HBase using Phoenix. On the server side, a Phoenix component resides on each RegionServer in HBase.
Let us consider the following HBase cluster architecture:
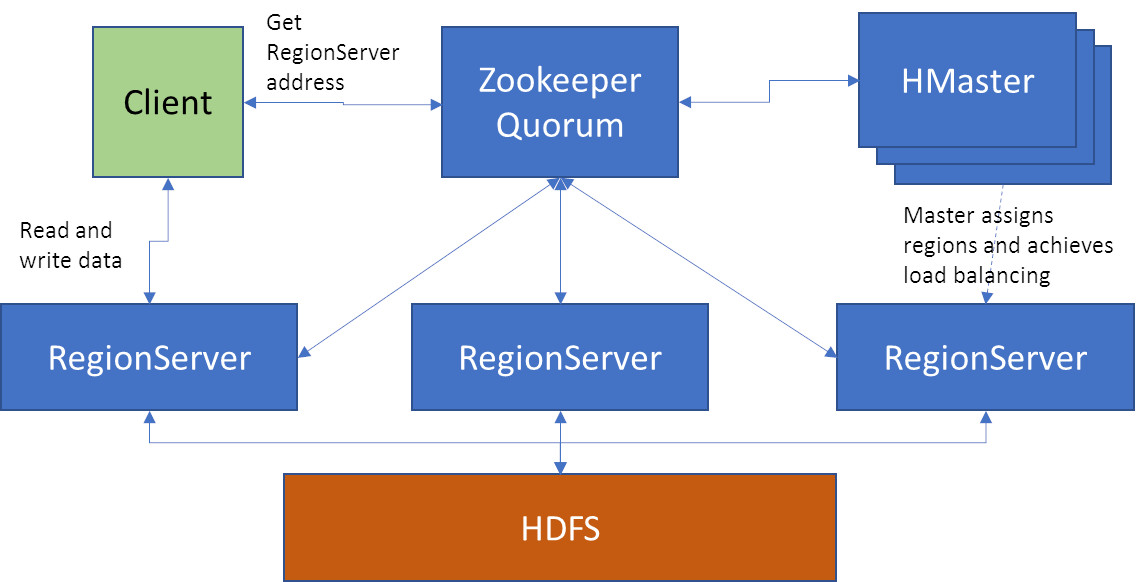
Figure 2: Sample Architecture
When Phoenix is brought into the picture, we have to note that there are two components — a server-side component that resides on the each RegionServer, and the client-side JDBC library. This diagram depicts the server side component.

Figure 3: Sample Architecture with Phoenix server-side component
To access a Phoenix enabled HDFS database, we need to use the Phoenix JDBC client library. When using the JDBC library, the architecture is as depicted:
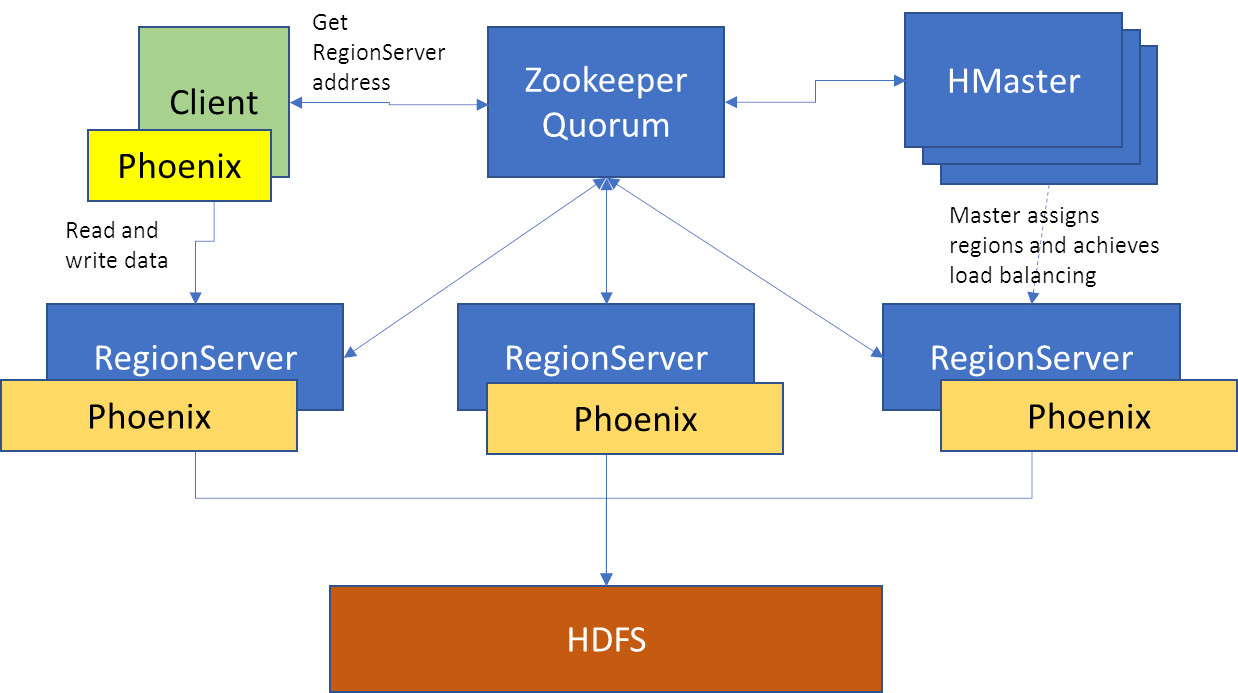
Figure 4: Sample architecture with Phoenix client-side component
Example
Let us now consider a simple example using the Phoenix API.
To run the example, we need to include the Phoenix client jar containing the JDBC classes, for example, we can use phoenix-4.1.0-client-hadoop2.jar.
import java.sql.*;
import java.util.*;
public class PhoenixExample {
public static void main(String args[]) throws Exception {
Connection conn;
Properties prop = new Properties();
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
conn = DriverManager.getConnection("jdbc:phoenix:localhost:/hbase-unsecure");
System.out.println("got connection");
ResultSet rst = conn.createStatement().executeQuery("select * from BMARKSP");
while (rst.next()) {
System.out.println(rst.getString(1) + " " + rst.getString(2) + " " + rst.getString(3) + " " + rst.getString(4) + " " + rst.getString(5) + " " + rst.getString(6));
}
}
}When compared to the example presented in "HBase, Phoenix, and Java Part 1," accessing the data stored in HBase is way simpler using Phoenix.
Apache Phoenix Features
- It is delivered as an embedded JDBC driver for HBase data.
- Follows ANSI SQL standards whenever possible
- Allows columns to be modeled as a multi-part row key or key/value cells.
- Full query support with predicate push down and optimal scan key formation.
- Versioned schema repository. Table metadata is stored in an HBase table and versioned, such that snapshot queries over prior versions will automatically use the correct schema.
- DDL support: CREATE TABLE, DROP TABLE, and ALTER TABLE for adding/removing columns.
- DML support: UPSERT VALUES for row-by-row insertion, UPSERT SELECT for mass data transfer between the same or different tables, and DELETE for deleting rows.
- Compiles SQL query into a series of HBase scans, and runs those scans in parallel to produce regular JDBC result sets.
It can seamlessly integrate with HBase, Pig, Flume, and Sqoop.
Why Is Phoenix so Fast?
- Apache Phoenix breaks up SQL queries into multiple HBase scans and runs them in parallel.
- Phoenix was developed with the notion of bringing the computation to the data by using:
- Coprocessors to perform operations on the server-side thus minimizing client/server data transfer
- Custom filters to prune data as close to the source as possible in addition, to minimize any startup cost.
- Phoenix uses native HBase APIs rather than going through the MapReduce framework.
- Phoenix leverages below HBase custom filters to provide higher performance.
- Essential Column Family filter leads to improved performance when Phoenix query filters on data that is split in multiple column families (cf) by only loading essential cf. In second pass, all cf are loaded as needed.
- Phoenix’s Skip Scan Filter leverages SEEK_NEXT_USING_HINT of HBase Filter. It significantly improves point queries over key columns.
- Salting in Phoenix leads to both improved read and write performance by adding an extra hash byte at start of key and pre-splitting the data in the number of regions. This eliminates hot-spotting of single or few regions servers
- In a single line, we can say that direct use of the HBase API, along with coprocessors and custom filters, results in performance on the order of milliseconds for small queries or seconds for tens of millions of rows.
- For aggregate queries, co-processors complete partial aggregation on their local region servers and only return relevant data to the client.
- Phoenix creates secondary indexes to improve performance on non-row key columns.
Limitations
A few limitations of Phoenix:
- Limited transaction support through client-side batching.
- Joins are not completely supported. FULL OUTER JOIN and CROSS JOIN are not supported.
Additional Examples
Two more examples that show how to use Phoenix:
- Open source Java projects: Apache Phoenix
- HBase Phoenix JDBC example
Opinions expressed by DZone contributors are their own.
Comments