Google's vs Facebook's Trunk-Based Development
Join the DZone community and get the full member experience.
Join For Freei’ve been pushing this branching model for something like 14 years now. it’s nice to see facebook say a little more about their trunk based development . of course they’re not doing it because they read anything i wrote, as the practice isn’t mine, it’s been hanging around in the industry for many years, but always as bridesmaid so to speak.
if not trunk, what?
mainline?
mainline as popularized by clearcase is what we’re trying to kill. at least historically. it’s very different to trunk based development, and even having vastly improved merge tools doesn’t make it better – you still risk regressions, and huge nerves around ordering of releases.
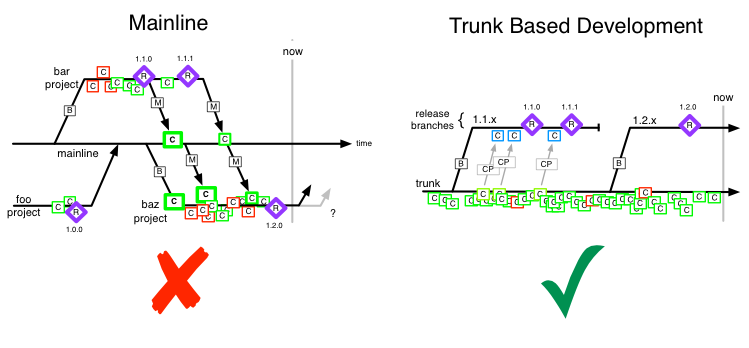
clearcase’s best-practices also foisted a ‘many repos’ (vobs) on teams using it, and that courted the whole conway’s law prophesy. i mentioned conway’s law before in scaling trunk based development and it concerns undue self-importance of teams around arbitrary separations.
multiple small repos for a dvcs ?
there is a great statement by a reddit user in the programming section of reddit, in conjunction with the facebook announcement:

this redditor is right, there’s a lack of atomicity around a many-repos design, that stymies bisect. it could be that git subtrees (not submodules) are a way of getting that back (thanks @chris_stevenson on a back channel). there’s also a real problem moving code easily between repos (with history) though @offbytwo (back channel again) points out that subtrees carefully used can help do that.
trunk at google vs facebook
tuesday’s announcement was from facebook, and to give some balance, there’s deeper info on google’s trunk design in: google’s scaled trunk based development .
subsetting the trunk for checkouts
tl;dr: different
google have many thousands of buildable and deployable things, which have very different release schedules. facebook don’t as they substantially have the php web-app, and apps for ios and android in different repos. well at least the main php web-app is in the mercurial trunk they talked about on tuesday. i’m not sure how the ios and android apps are managed, but at least the android one is outside the main trunk.
google subset their trunk. i posted about that on monday . in that article i pointed out that the checkout can grow (or shrink) depending on the nature of the change being undertaken. it’s very different to a multiple-small-repos design.
facebook don’t subset their trunk on checkout, as they do not need to; the head revisions of everything in that trunk are not big enough for a c: drive or ide to buckle. there’s also no compile stage for php , for regular development work.
maximized sharing of code
tl;dr: the same
code is shared using globbed directories within the source tree. it’s shared as source files, in situ, rather than classes in a jar (or equivalent).
refactoring
tl;dr: the same
developers take on refactorings where appropriate. sure it means a bigger atomic commit, but knowing all the affected source is in front of you as you do the refactoring is comforting. at least, knowing that if intellij (or eclipse, etc) completes the refactoring there’s a very strong possibility that the build will stay green, and that you’re only going to have a slight impact on other people’s working copy, and only if they are concurrently editing the same files. bigger refactoring probably still require a warning email.
super tooling of the build phase
tl;dr: the same
google have what amounts to a super-computer doing the compilation for them (all languages that are compiled). all developers and all ci daemons leverage it. and by effective super-computer, i mean previous-compiled bits and pieces are pulled out of an internal cloud-map-thing for source permutations that have been compiled before. the distributed hashmap is possibly lru centric rather that everything forever.
facebook don’t have that big hashmap of recently compiled bits and pieces, but they do have hiphop in the toolchain (originally a php to c++ compiler) which is interesting because at face value php is an interpreted language and ‘compile’ makes no sense. hiphop was created to reduce the server footprint and requirements for production deployments, while still being 100% functionally identical to the interpreted php app. it’s also faster in production. more recently hiphop became a virtual machine. it continues to be incrementally improved. like google, facebook can measure cost-benefit of continued work on it (prod rack space & prod electricity vs developer salaries).
source-control weapons of choice
tl;dr: different
google use perforce for their trunk (with additional tooling), and many (but not all) developers use git on their local workstation to gain local-branching with an inhouse developed bridge for interop with perforce. facebook uses mercurial with additional tooling for the central server/repo. it’s unclear whether developers, by habit, exist with the mercurial client software or use git which can interop with mercurial backends. both google and facebook do trunk based development of course.
branches & merge pain
tl;dr: the same
they don’t have merge pain, because as a rule developers are not merging to/from branches. at least up to the central repo’s server they are not. on workstations, developers may be merging to/from local branches, and rebasing when the push something that’s “done” back to the central repo.
release engineers might cherry-pick defect fixes from time to time, but regular developers are not merging (you should not count to-working-copy merges)
eating own dog-food
tl;dr: mostly different
all staff at facebook use a not-live-yet version of the web-app for all of their communication, documentation, management etc. if there’s a bug everyone feels it – though selenium2 functional tests and zillions of unit-tests guard against that happening too often.
google has too many different apps for the team making each to be said to be a daily user of it. for example the adsense developer may use a dog-food version of gmail, but they are making adsense, so are hardly hurting themselves as they are not minute by minute using the interface as part of their regular existence at google.
code review
tl;dr: same
both google and facebook insist on code reviews before the commit is accepted into the remote repo’s trunk for all others to use. there’s no mechanism of code review that’s more efficient or effective.
google back in 2009 were pivoting incoming changes to the trunk around the code-review process managed by mondrian. i wrote about that in “continuous review #1” in december . i think they are unchanged in that respect: developers actively push their commit after a code review has been completed.
facebook have just flipped to mercurial (from subversion). in the article linked to at the top of the page, facebook have not mentioned “pull request” or “patch queue”, or indeed “code review”. the article was mostly about speed, robustness and scale.
i suspect they are sitting within the semantics of mercurials patch-queue processing though, although assigning a bot to it rather than a human.
update: simon stewart pinged me and reminded me that they use (and made) phabricator. he spoke about it in a mobile@scale presentation, and that
video is here
. in the video he says the review is queue based now, but that they experimenting with landing the change sets into the master now. the video is from november, and was for the android + ios platforms, but it is likely to be used today for the main trunk for the
php
web-app.
automated testing
tl;dr: same
heavy reliance on unit tests (not necessarily made in a tdd style). later in an build pipeline, selenium2 tests (for web-apps at least) kick in to guard the functional quality of deployed app.
manual qa
tl;dr: mostly the same
both companies have progressively moved way from manual qa and dedicated testing professionals, towards developers testing their own stuff at discrete moments (note the dog-food item above too).
prod release frequency
tl;dr: it varies.
facebook for the main web app, are twice a day presently (at least on weekdays). i published info on that at the start of last year. google have many apps with different release schedules, and some are “many times a day”, while others are “planned releases every few weeks”. many are in between.
prod db deployment
tl;dr: mostly the same
database (or equivalent) table shapes (or equivalent) are designed to be forwards/backwards compatible as far as possible.
pull requests as part of workflow
tl;dr: same
etsy, github, and other high throughput organizations are trunking by some definition, but using pull-requests to merge in things being done. it has different obligations if done, but google and facebook are not doing this in their trunks – they both essentially push (after review). refer the ‘code review’ section above.
common code ownership
tl;dr: the same
you can commit to any part of the source tree, provided it passed a fair code review. notional owners of directories within the source tree take a boy-scout pledge to do their best with unsolicited incoming change-lists. there are strong permissions in the google perforce implementation, but the pledge means that contributions are not often rejected if the merit is there.
build is ever broken
tl;dr: the same
almost never.
directionality of merge for prod bug fixes
tl;dr: the same
trunk receives the defect fix, it gets cherry picked to the release branch. the release branch might have been made from a tag, if it didn’t exist before.
binary dependencies
tl;dr: the same
checked into source-control without version suffixing (harmonized versions across all apps). e.g. – log4j.jar rather than log4j-1.2.8.jar.
Published at DZone with permission of Paul Hammant, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments