Go Microservices, Part 15: Monitoring With Prometheus
Learn how to monitor your microservices applications with Prometheus and graphing the data with Grafana.
Join the DZone community and get the full member experience.
Join For Freein this part of the go microservices blog series , we’ll take on monitoring our microservices using prometheus and graphing our data using grafana .
(please note that this is not an in-depth blog post about all the capabilities and features of prometheus or grafana. there are better resources for that.)
contents
- overview
- prometheus
- service discovery
- exposing metrics in go services
- querying in prometheus
- grafana
- summary
source code
the finished source can be cloned from github:
> git clone https://github.com/callistaenterprise/goblog.git
> git checkout p15
1. overview
in recent years, prometheus has emerged as one of the major players in the open source space regarding the collection of metrics and monitoring data from (micro)services. at its heart, prometheus stores metric values at a given millisecond in time in a time series database, optionally with one or more labels.
in this tutorial, we’ll deploy some new services and applications.
here's the architectural overview of the monitoring solution:
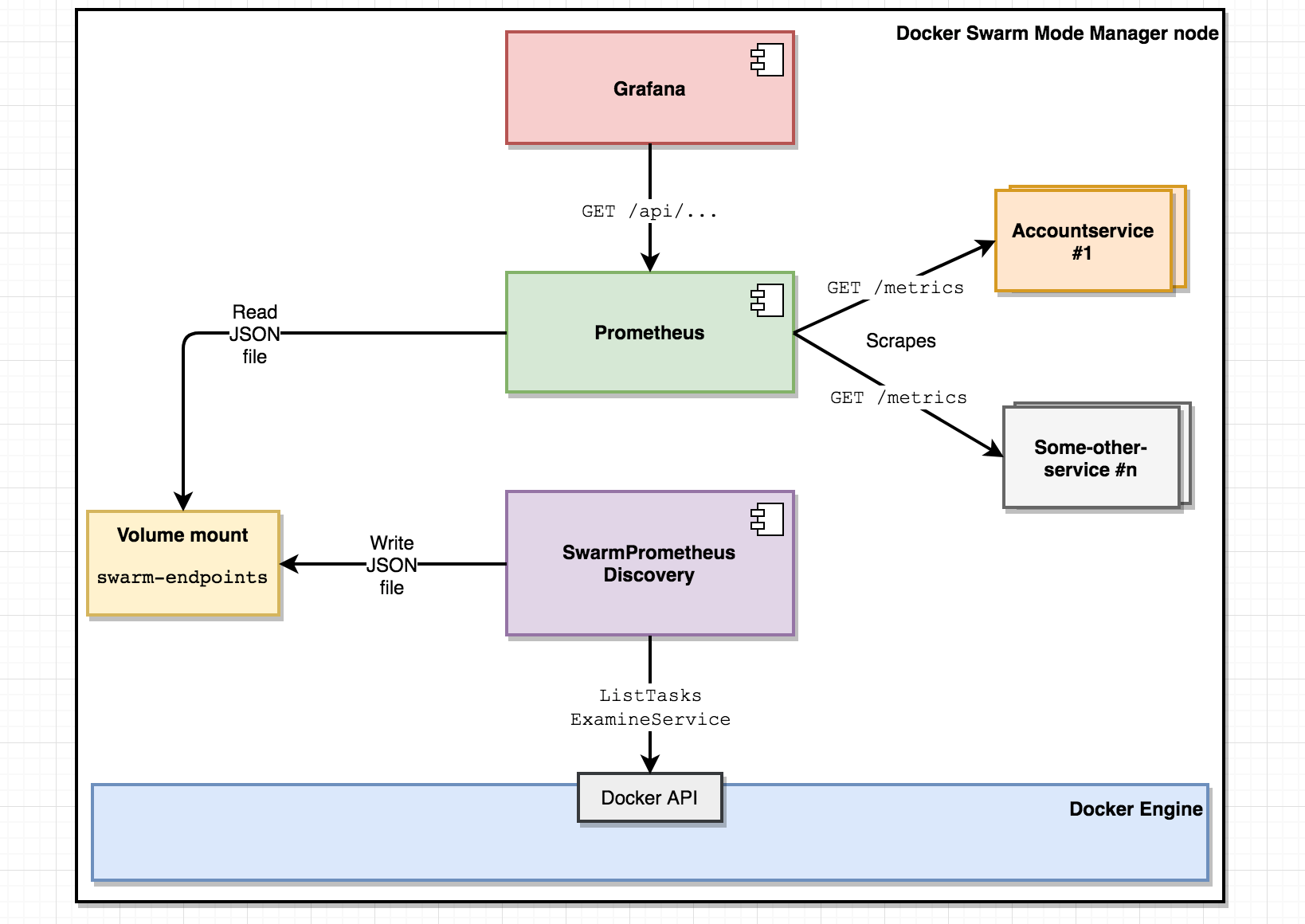
during the course of this post, we’ll accomplish the following:
- adding a /metrics endpoint to each microservice served by the prometheus httphandler .
- instrumenting our go-code so the latencies and response sizes of our restful endpoints are made available at /metrics .
- writing and deploying a docker swarm mode -specific discovery microservice which lets prometheus know where to find /metrics endpoints to scrape in an ever-changing microservice landscape.
- deploying the prometheus server in our docker swarm mode cluster.
- deployment of grafana in our docker swarm mode cluster.
- querying and graphing in grafana.
2. prometheus
prometheus is an open-source toolkit for monitoring and alerting based on an embedded times-series database, a query dsl and various mechanics for scraping metrics data off endpoints.
in practice, from our perspective that boils down to:
- a standardized format that services use to expose metrics.
- client libraries for exposing the metrics over http.
- server software for scraping metrics endpoints and storing the data in the time-series database.
- a restful api for querying the time-series data that can be used by the built-in gui as well as 3rd-party applications such as grafana.
the prometheus server is written in go.
2.1 metric types
prometheus includes four different kinds of metrics:
- counter - numeric values that only may increase such as number of requests served.
- gauge - numerical values that can go both up or down. temperatures, blood pressure, heap size, cpu utilization etc.
- histogram - representation of the distribution of numerical data, usually placed into buckets. the most common use in monitoring is for measuring response times and placing each observation into a bucket.
- summary - also samples observations like histograms, but uses quantiles instead of buckets.
i strongly recommend this jworks blog post for in-depth information and explanations about prometheus concepts.
2.2 the exported data format
prometheus client libraries expose data using a really simple format:
# help go_memstats_heap_alloc_bytes number of heap bytes allocated and still in use.
# type go_memstats_heap_alloc_bytes gauge
go_memstats_heap_alloc_bytes 1.259432e+06labels and metadata about a metric such as go_memstats_heap_alloc_bytes (as exposed by the go client library ) come with corresponding # help and # type metadata.
- help - just a description of the metric. in the case above, specified by the go client library. for user-defined metrics, you can, of course, write whatever you want.
- type - prometheus defines a number of metric types : see the previous section.
here’s an example summary metric from our lovely “accountservice” exposing the /accounts/{accountid} endpoint:
# help accountservice_getaccount get /accounts/{accountid}
# type accountservice_getaccount summary
accountservice_getaccount{service="normal",quantile="0.5"} 0.02860325
accountservice_getaccount{service="normal",quantile="0.9"} 0.083001706
accountservice_getaccount{service="normal",quantile="0.99"} 0.424586416
accountservice_getaccount_sum{service="normal"} 6.542147227
accountservice_getaccount_count{service="normal"} 129this summary metric captures the duration in seconds spent by each request, exposing this data as three quantiles (50th, 90th and 99th percentile) as well as total time spent and number of requests.
2.4 deploying the prometheus server
we’ll use the standard prom/prometheus docker image from docker hub with a custom configuration file.
if you’ve checked out p15 from git, enter the /support/prometheus directory where we have a sample dockerfile as well as the prometheus.yaml linked above.
dockerfile:
from prom/prometheus
add ./prometheus.yml /etc/prometheus/prometheus.ymlto build and deploy prometheus with our custom config from the support/prometheus folder:
> docker build -t someprefix/prometheus .
> docker service rm prometheus
> docker service create -p 9090:9090 --constraint node.role==manager --mount type=volume,source=swarm-endpoints,target=/etc/swarm-endpoints/,volume-driver=local --name=prometheus --replicas=1 --network=my_network someprefix/prometheusprometheus should now be up-and-running on port 9090 of your cluster.
please note that this is a non-persistent setup. in a real scenario, you’d want to set it up with requisite persistent storage.
3. service discovery
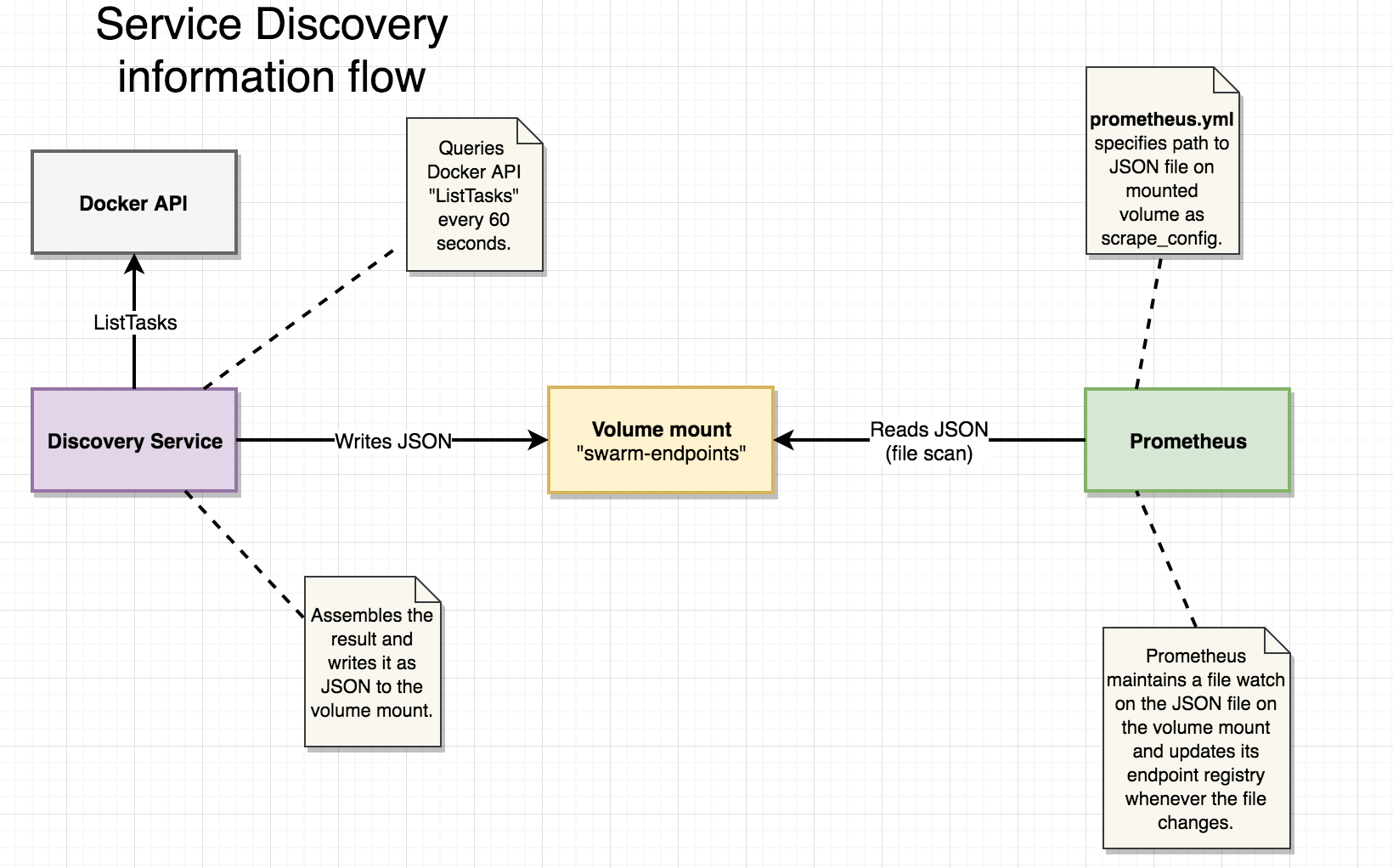
how does prometheus know which endpoints to scrape for metric data? a vanilla install of prometheus will just scrape itself which isn’t that useful. luckily, scrape target discovery is highly configurable with built-in support for various container orchestrators, cloud providers, and configuration mechanisms.
however, discovery of containers in docker swarm mode is not one of the officially supported mechanisms, so we’ll use the file_sd_config discovery configuration option instead. file_sd_config provides a generic way of letting prometheus know which endpoints to scrape by reading a json file describing endpoints, ports, and labels. the path is configured in prometheus prometheus.yml config file, i.e:
scrape_configs:
- job_name: swarm-service-endpoints
file_sd_configs:
- files:
- /etc/swarm-endpoints/swarm-endpoints.json/etc/swarm-endpoints is a volume mount that prometheus server will read from, while our discovery application described in section 3.2 will write the swarm-endpoints.json file to the very same volume mount.
3.1 the json file_sd_congif format
the json format is simple, consisting of a list of entries having one or more “targets” and a map of key-value “label” pairs:
[
{
"targets": [
"10.0.0.116:6767",
"10.0.0.112:6767",
],
"labels": {
"task": "accountservice"
}
},
.......
]this example shows our “accountservice” running two instances. remember that we cannot address the accountservice as a docker swarm mode “service” in this use-case since we want to scrape each running instance for its /metrics . aggregation can be handled using the query dsl of prometheus.
3.2 the discovery application
i decided to write a simple discovery application (in go of course!) to accomplish the task described above. it’s rather simple and fits into a single source file.
it does the following:
- queries the docker api for running tasks every 15 seconds.
- builds a list of scrape targets, grouped buy their “task” label. (see 3.1)
- writes the result as swarm-endpoints.json to the mounted /etc/swarm-endpoints/ volume.
- goto 1.
some key parts of the implementation:
main func
func main() {
logrus.println("starting swarm-scraper!")
// connect to the docker api
endpoint: = "unix:///var/run/docker.sock"
dockerclient, err: = docker.newclient(endpoint)
if err != nil {
panic(err)
}
// find the networkid we want to address tasks on.
findnetworkid(dockerclient, networkname)
// start the task poller, inlined function.
go func(dockerclient * docker.client) {
for {
time.sleep(time.second * 15)
polltasks(dockerclient)
}
}(dockerclient)
// block...
log.println("waiting at block...")
...some code to stop the main method from exiting...
}quite straightforward — obtain a docker client, determine id of docker network we want to work on (more on that later) and start the goroutine that will re-write that json file every 15 seconds.
polltasks func
next, the polltasks function performs the actual work. it’s objective is to transform the response of the listtasks call from the docker api into json structured according to the file_sd_config format we saw earlier in section 3.1. we’re using a struct for this purpose:
type scrapedtask struct {
targets[] string `json:"targets"`
labels map[string] string `json:"labels"`
}the “targets” and “labels” are mapped into their expected lower-cased json names using json-tags.
next, the actual code that does most of the work. follow the comments.
func polltasks(client * docker.client) {
// get running tasks (e.g. containers) from the docker client.
tasks,
_: = client.listtasks(docker.listtasksoptions {
filters: filters
})
// initialize a map that holds one "scrapedtask" for a given serviceid
tasksmap: = make(map[string] * scrapedtask)
// iterate over the returned tasks.
for _,
task: = range tasks {
// lookup service
service,
_: = client.inspectservice(task.serviceid)
// skip if service is in ignoredlist, e.g. don't scrape prometheus...
if isinignoredlist(service.spec.name) {
continue
}
portnumber: = "-1"
// find http port of service.
for _,
port: = range service.endpoint.ports {
if port.protocol == "tcp" {
portnumber = fmt.sprint(port.publishedport)
}
}
// skip if no exposed tcp port
if portnumber == "-1" {
continue
}
// iterate network attachments on task
for _,
netw: = range task.networksattachments {
// only extract ip if on expected network.
if netw.network.id == networkid {
// the process functions extracts ip and stuffs ip+service name into the scrapedtask instance for the
// serviceid.
if taskentry, ok: = tasksmap[service.id];
ok {
processexistingtask(taskentry, netw, portnumber, service)
} else {
processnewtask(netw, portnumber, service, tasksmap)
}
}
}
}
// transform values of map into slice.
tasklist: = make([] scrapedtask, 0)
for _,
value: = range tasksmap {
tasklist = append(tasklist, * value)
}
// get task list as json
bytes,
err: = json.marshal(tasklist)
if err != nil {
panic(err)
}
// open and write file
file,
err: = os.create("/etc/swarm-endpoints/swarm-endpoints.json")
defer file.close()
if err != nil {
fmt.errorf("error writing file: %v\n", err.error())
panic(err.error())
}
file.write(bytes)
}yes, the function is a bit too long, but it should be relatively easy to make sense of it. a few notes:
- networks: we will only look up the ip address of a task if it is on the same network as we specified as a command-line argument. otherwise, we’ll risk trying to scrape ip-addresses that doesn’t resolve properly.
- port exposed: the service must publish a port, otherwise the scraper can’t reach the /metrics endpoint of the service.
- targets: services having more than one instance gets several entries in the targets slice of their scrapedtask.
there’s not much more to it than this. feel free to check out the complete source .
note that there already exists a similar (more capable) project on github for this purpose one could try as well.
3.3 containerization
when packaging our discovery microservice into a docker image, we use a very simple dockerfile:
from iron/base
add swarm-prometheus-discovery-linux-amd64 /
entrypoint ["./swarm-prometheus-discovery-linux-amd64","-network", "my_network", "-ignoredservices", "prometheus,grafana"]note that we aren’t exposing any ports for inbound traffic since no one needs to ask the service anything. also note the -network and -ignoredservices arguments:
-
-network: name of the docker network to query -
-service: service names of services we don’t want to scrape. the example above specifies prometheus and grafana , but could be expanded to more known supporting services that doesn’t expose prometheus endpoints at /metrics such as netflix zuul, hystrix, rabbitmq etc.
3.4 deployment
to easily build and deploy the discovery service to docker swarm, there’s a simple shell script whose content should be quite familiar by now:
docker service create --constraint node.role==manager\
--mount type=volume,source=swarm-endpoints,target=/etc/swarm-endpoints/\ <-- here!
--mount type=bind,source=/var/run/docker.sock,target=/var/run/docker.sock\ <-- here!
--name=swarm-prometheus-discovery --replicas=1 --network=my_network \
someprefix/swarm-prometheus-discoverythe two mounts may use a bit extra explanation:
- –mount type=volume,source=swarm-endpoints,target=/etc/swarm-endpoints/ - this argument tells docker service create to mount the volume named “swarm-endpoints” at /etc/swarm-endpoints/ in the file system of the running container. as described in the start of this section, we’ll configure the prometheus server to load its scrape targets from the same volume mount.
- –mount type=bind,source=/var/run/docker.sock,target=/var/run/docker.sock - this argument creates a bind mount to the docker.sock, allowing the discovery service to directly talk to the docker api.
4. exposing metrics in go services
next, we’ll add the go code necessary for making our microservices publish monitoring data in prometheus format on /metrics as well as making sure our restful endpoints (such as /accounts/{accountid} ) produces prometheus monitoring data picked up and published on /metrics .
(if you’ve been following this series for a long time, you may notice that some of the route stuff has been moved into common which facilitates some long-overdue code reuse. )
4.1 adding the /metrics endpoint
the /metrics endpoint prometheus wants to scrape doesn’t appear by itself. we need to add a route at /metrics that specifies a http handler from the prometheus go client library:
route{
"prometheus",
"get",
"/metrics",
promhttp.handler().servehttp, <-- handler from prometheus
false, <-- flag indicating whether to instrument this endpoint.
},note the new “false” argument. i’ve added it so we can control which endpoints of the microservice to apply prometheus middleware for (see next section).
4.2 declaring our middleware
in our “accountservice,” we have a number of restful http endpoints such as:
- /accounts/{accountid} get - gets a single account
- /graphql post - graphql queries
- /accounts post - create new account
- /health get - healthcheck
we should definitely add prometheus monitoring for the first three endpoints while monitoring the
/health
endpoint isn’t that interesting.
for a typical restful endpoint, we probably want to monitor number of requests and latencies for each request. as each data point is placed in a time series that should suffice for producing good metrics for api usage and performance.
to accomplish this, we want a summaryvec produced per endpoint. picking between summaries and histograms isn’t exactly easy, check this article for some more info.
4.3 adding a middleware for measuring http requests
capturing metrics is performed by injecting a go http.handler using the middleware pattern ( example ). we’re using the most simple option where we chain handlers together, i.e:
// newrouter creates a mux.router and returns a pointer to it.
func newrouter() * mux.router {
initql( & livegraphqlresolvers {})
muxrouter: = mux.newrouter().strictslash(true)
for _, route: = range routes {
// create summaryvec for endpoint
summaryvec: = monitoring.buildsummaryvec(route.name, route.method + " " + route.pattern)
// add route to muxrouter, including middleware chaining and passing the summaryvec to the withmonitoring func.
muxrouter.methods(route.method).
path(route.pattern).
name(route.name).
handler(monitoring.withmonitoring(withtracing(route.handlerfunc, route), route, summaryvec)) // <-- chaining here!!!
}
logrus.infoln("successfully initialized routes including prometheus.")
return muxrouter
}monitoring.buildsummaryvec() is a factory function in our /goblog/common library that creates an summaryvec instance and registers it with prometheus, see the code here . the go prometheus client api can be a bit complex imho, though you should be fine if you follow their examples .
the monitoring.withmonitoring() function is only invoked once when setting up the middleware chain. it will either return the next handler if the route being processed declares that it doesn’t want monitoring or the inlined http.handler function declared after the if-statement:
func withmonitoring(next http.handler, route route, summary *prometheus.summaryvec) http.handler {
// just return the next handler if route shouldn't be monitored
if !route.monitor {
return next
}
return http.handlerfunc(func(rw http.responsewriter, req *http.request) {
// impl coming up ...
}
}the implementation of our prometheus monitoring middleware that will be executed on each call:
return http.handlerfunc(func(rw http.responsewriter, req *http.request) {
start := time.now() // start time of the invocation
next.servehttp(rw, req) // invoke the next handler
duration := time.since(start) // record duration since start after the wrapped handler is done
summary.withlabelvalues("duration").observe(duration.seconds()) // store duration of request under the "duration" label.
size, err := strconv.atoi(rw.header().get("content-length")) // get size of response, if possible.
if err == nil {
summary.withlabelvalues("size").observe(float64(size)) // if response contained content-length header, store under the "size" label.
}
})to sum things up, we’ve done the following with the codebase of our “accountservice”:
- added a boolean to our route struct so we can enable/disable metrics for it.
- added code that creates a summaryvec instance per endpoint.
- added a new middleware function that measures duration and response size for an http request and stuffs the results into the supplied summaryvec.
- chained the new middleware func into our existing chain of middlewares.
4.4 verify that /metrics are available
to speed things up a bit, there’s a new shell script as.sh one can use to quickly rebuild and redeploy the “accountservice.”
after build and redeploy, our “accountservice” should now have a /metrics endpoint. try curl-ing http://192.168.99.100:6767/metrics .
> curl http://192.168.99.100:6767/metrics
# help go_gc_duration_seconds a summary of the gc invocation durations.
# type go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 5.6714e-05
go_gc_duration_seconds{quantile="0.25"} 0.000197476
....out of the box, the go prometheus http handler provides us with a ton of go runtime statistics - memory usage, gc stats and cpu utilization. note that we need to call our /accounts/{accountid} endpoint at least one time to get data for that endpoint:
> curl http://192.168.99.100:6767/accounts/10000
.... response from the endpoint ...
> curl http://192.168.99.100:6767/metrics
# help accountservice_getaccount get /accounts/{accountid}
# type accountservice_getaccount summary
accountservice_getaccount{service="duration",quantile="0.5"} 0.014619157
accountservice_getaccount{service="duration",quantile="0.9"} 0.018249754
accountservice_getaccount{service="duration",quantile="0.99"} 0.156361284
accountservice_getaccount_sum{service="duration"} 0.8361315079999999
accountservice_getaccount_count{service="duration"} 44
accountservice_getaccount{service="size",quantile="0.5"} 293
...there they are! one can note the naming convention used, e.g: [namespace] [route name] *{[label1]=[“labelvalue1”],..}, we’ll get back to how these names and labels are used in the query dsl later in the prometheus or grafana gui:s.
5. querying in prometheus
if everything works out, we should now have an “accountservice” producing metrics which the prometheus server knows where to scrape. let’s open up the prometheus gui at http://192.168.99.100:9090 again and execute our first query. to get some data, i’ve run a simple script that calls the /accounts/{accountid} endpoint with 3 req/s.
we’ll do two simple prometheus queries and use the graphing functionality in prometheus server to display the result.
5.1 total number of requests
we’ll start with just counting the total number of requests. we’ll do this by the following query:
accountservice_getaccount_count{service="duration"}
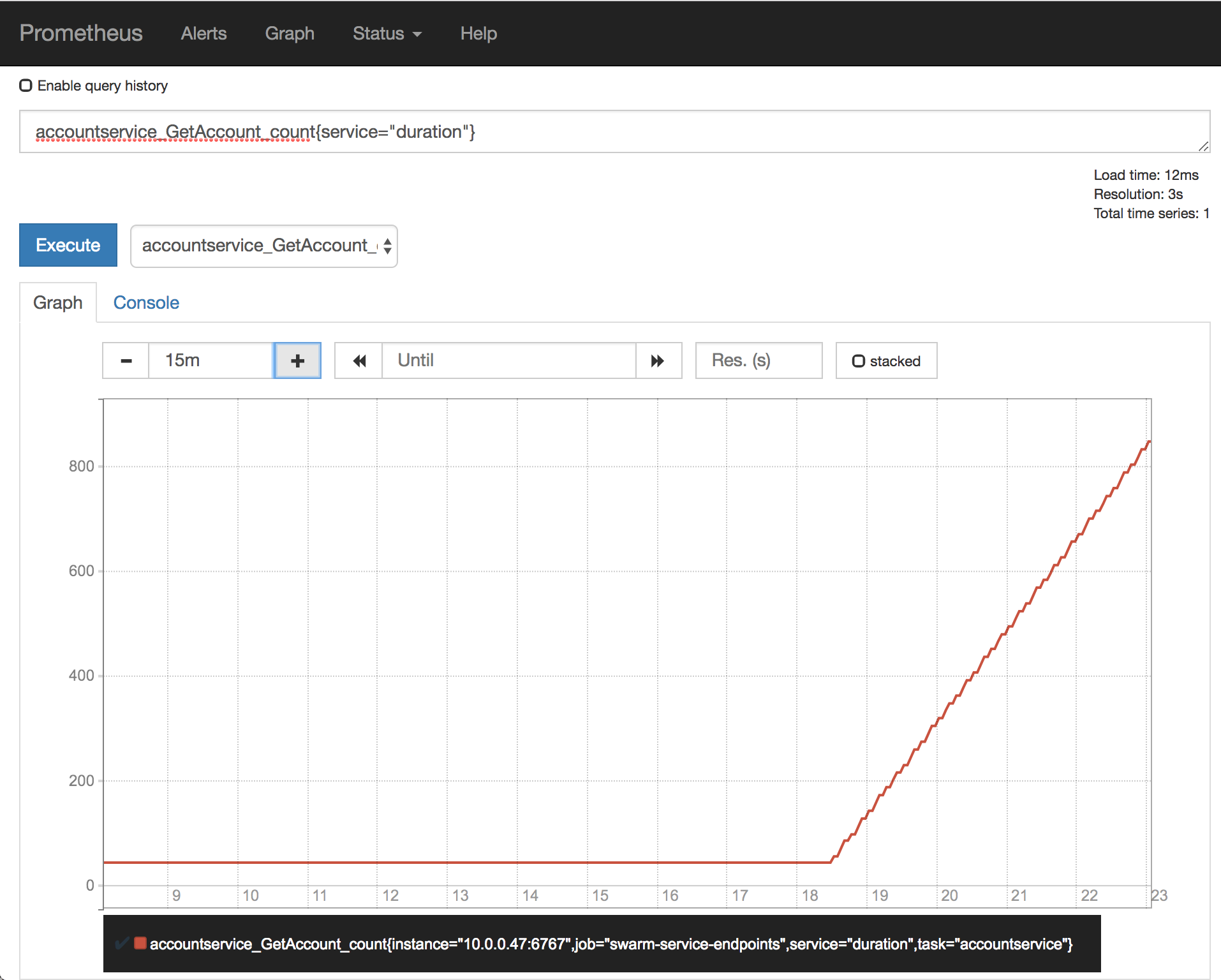
this just plots our linearly increasing (we’re running 3 req/s) count for the getaccount route.
5.2 latency percentiles in milliseconds
let’s enter the following into the query field, where we select all quantiles for the “accountservice_getaccount” having the “duration” label. we multiply the result by 1000 to convert from seconds into milliseconds.
accountservice_getaccount{service="duration"} * 1000
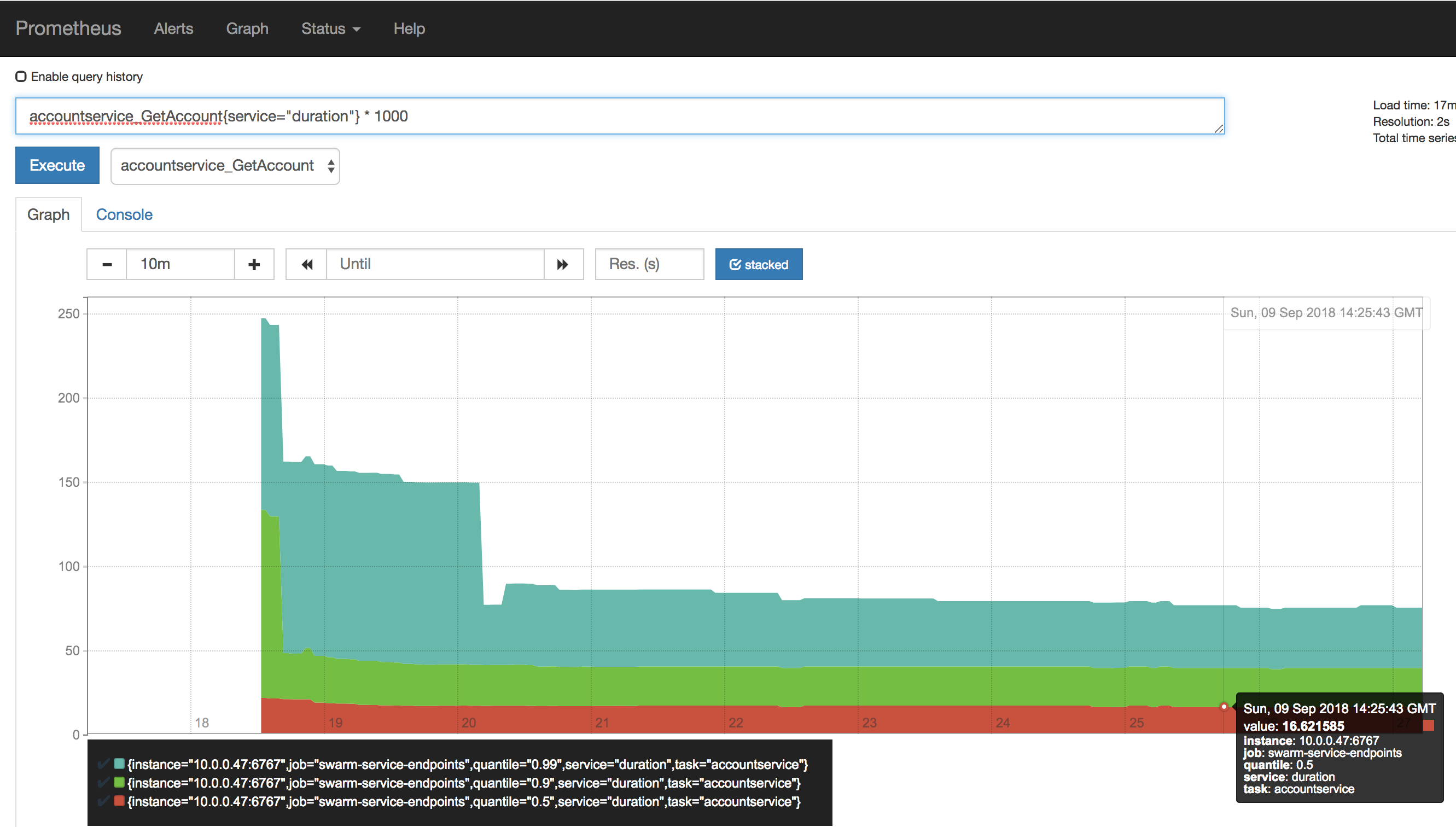
i’ve selected the “stacked” visualization option and it’s quite easy to see that our 50th percentile (e.g. avg) sits at about 16ms while the 99th percentile duration is approx 80 ms.
the prometheus gui can do more, but for more eye-appealing visualizations we’ll continue by getting grafana up and running and configured to use our prometheus server as the datasource.
6. grafana
grafana is a platform for visualization and analytics of time series data. it’s used for many purposes, visualization of prometheus metrics is just one of many and fully describing the capabilities of grafana is definitely out of the scope of this blog post.
we’ll do the following:
- getting grafana up-and-running in our cluster
- configure it to use prometheus as the datasource
- create a dashboard plotting some data from our accountservice
6.1 running grafana in our cluster
for the purpose of this blog post, we’ll run grafana without persistence etc which makes it a breeze to set up:
> docker service create -p 3000:3000 --constraint node.role==manager --name=grafana --replicas=1 --network=my_network grafana/grafanawait until it’s done and fire up your web browser at http://192.168.99.100:3000 . grafana will prompt you to change your password and then take you to its dashboard:
note that we’re running grafana without any persistent storage. in a real setup, you’d set it up properly so your user(s) and reports survive a cluster restart!
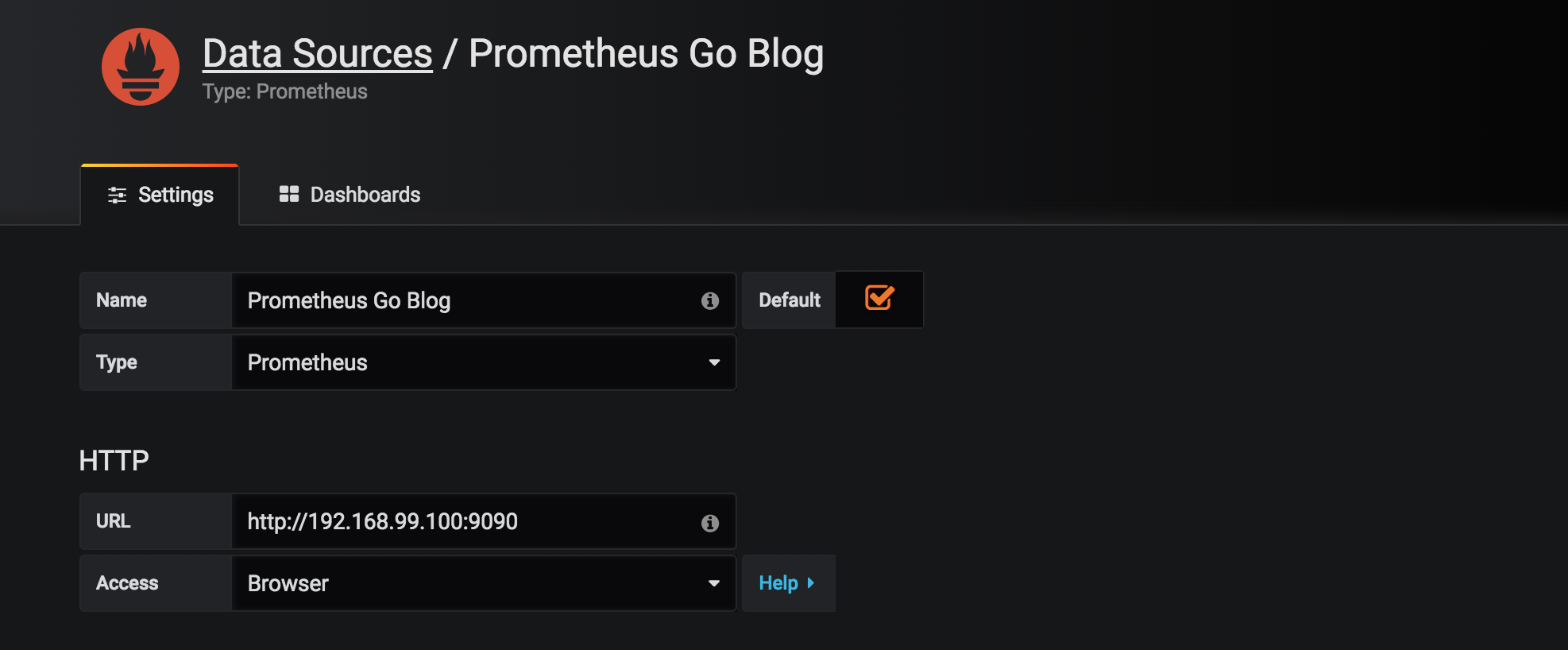
6.2 add prometheus as a datasource
click the “add datasource” button and enter http://192.168.99.100:9090 as server url. note that we’ll using “browser” access which means that grafana will communicate with the prometheus server through your browser as a proxy. it sort-of works using server-mode with http://prometheus:9090 as url (which is how it should be done), but i keep getting issues with queries just refusing to complete so i’d recommend using browser-mode when just trying things out.
6.3 create a dashboard using our datasource
click the plus (+) button in the upper-left and then select “graph” as panel type. next, click the chevron on “panel title” and select “edit” in the drop-down menu. you should see something such as:
as you can see, you should select our “prometheus go” datasource from the data source drop-down. we should now be able to write our first query, using the same query language as we used in section 5.
if you start typing in the query field, you’ll get code-completion to help you get started. in the image below, i’ve typed “acc” which immediately results in a number of things we could add to our dashboard.
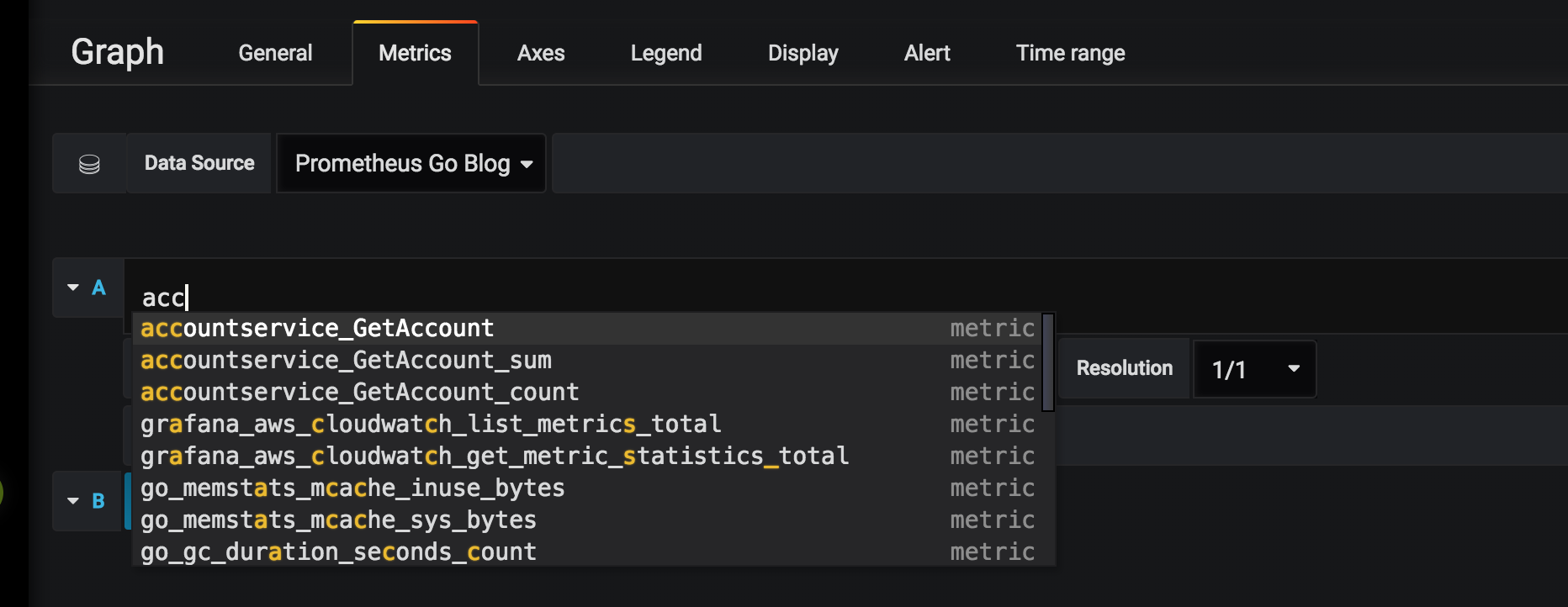
grafana is very powerful with an overwhelming amount of options and capabilities for creating graphs, dashboards, and analytics. there are people and blogs better suited to digging into exquisite details and graph skills, so i’ll settle for describing the queries used for creating a dashboard with two panels. both show the system running three instances of the “accountservice” under a light load.
accountservice average latency over a 1-minute sliding window
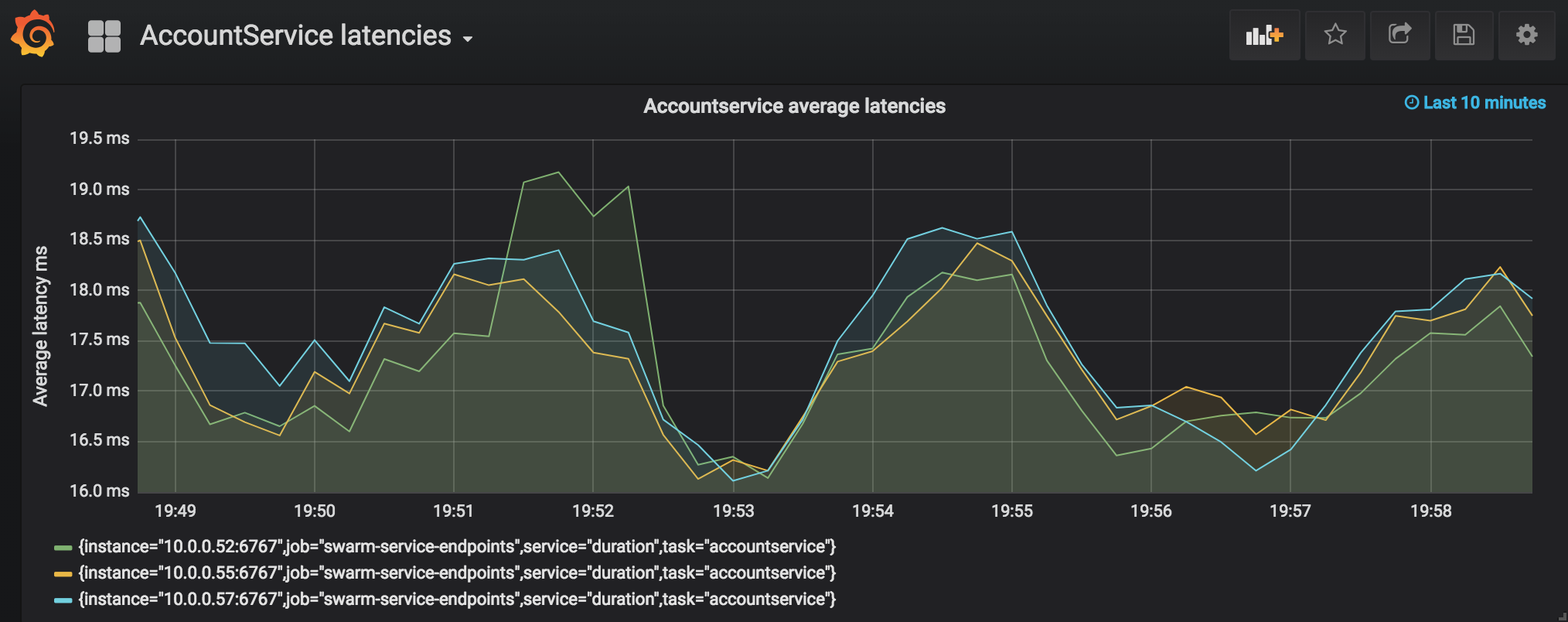
for the average latencies, we’ll use the following query:
avg_over_time(accountservice_getaccount_sum{service="duration"}[1m]) /
avg_over_time(accountservice_getaccount_count{service="duration"}[1m])
* 1000the avg_over_time() function allows us to specify the time window during which we want to aggregate values in the time series, one minute in this case. to get the average, we’re dividing the sum of latencies by the count which gets us the average, finally multiplying by 1000 to get the result in milliseconds instead of fractions of a second.
due to the broken y-axis the results seem to fluctuate a lot, but is actually within approx 16-19 ms.
accountservice memory utilization in megabytes
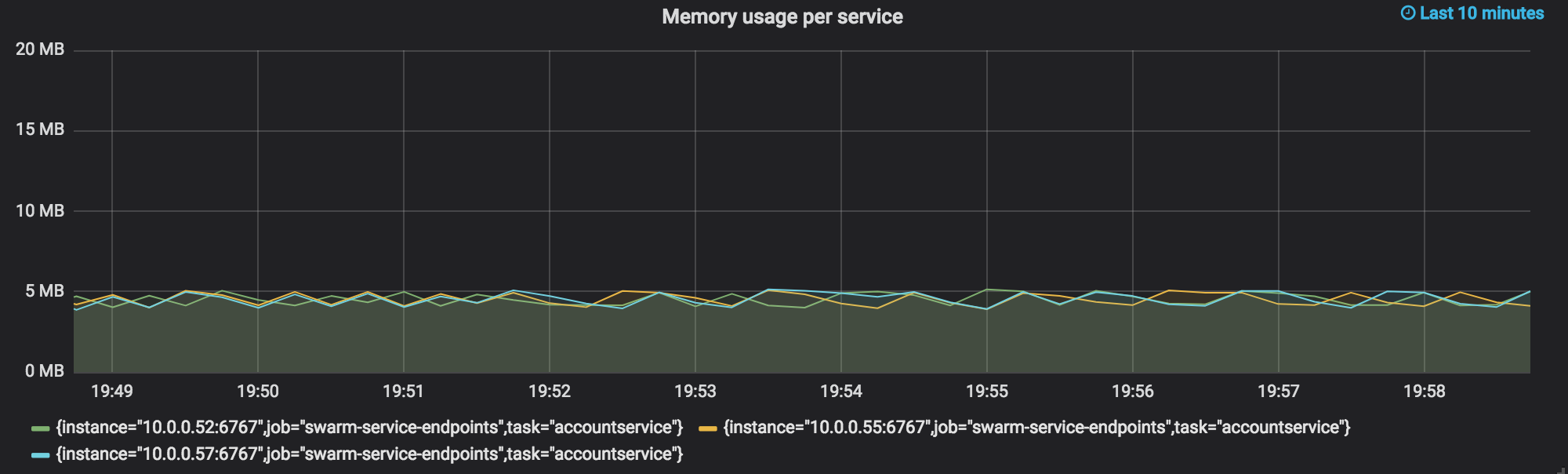
memory utilization is a classic metric in the world of monitoring. the default http.handler from prometheus automatically exposes this as a gauge metric we can use in a grafana dashboard. the query looks like this:
go_memstats_heap_inuse_bytes{task="accountservice"} / 1000000we see our three instances of the “accountservice” hovering around the 5mb mark.
as previously stated, grafana offers great possibilities for visualizing and analyzing monitoring data exposed by the equally capable prometheus ecosystem, whose finer details is out of scope for this post.
8. summary
in this part of the series, we’ve finally added monitoring, where prometheus (go client lib + server) and grafana was our stack of choice. we’ve accomplished the following:
- wrote a simple service discovery mechanism so the prometheus server can find scrape targets on docker swarm.
- added prometheus /metrics endpoint and added middleware for exposing metrics from our restful endpoints.
- deployed prometheus server + grafana
- showcased a few queries.
in the next part, i hope i can finally do something on the huge topic of security.
please help spread the word! feel free to share this blog post using your favorite social media platform.
Published at DZone with permission of Erik Lupander, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments