Gain Lightning Fast Reads and Writes Without Changing Your PostgreSQL Application
Walk through how the YugabyteDB distributed database lowers read and write latency and (most importantly) runs an existing PostgreSQL application with no costly rewrite.
Join the DZone community and get the full member experience.
Join For FreeA leading transport and logistics company had to lower the read and write latency of their electronic radio frequency (RF) system (consisting of an RF gun/scanner and an app) that is used to track and maintain control over every SKU in their supply chain.
The application relies on a low-latency read to a relational database to verify authorizations for every user who clicks on an RF scanner menu system. It defines the allowable action and subsequent screen display and records the user’s action for tracking and security purposes (write).
The company was using Oracle but migrated to PostgreSQL due to Oracle’s high costs. However, lower costs came with significant latency issues, which decimated user productivity and increased the number of errors. While Oracle’s workload response time was 19.8 milliseconds, PostgreSQL’s performance was unacceptable at 102 milliseconds.
The company needed a database that could accommodate a distributed hybrid deployment model, lower read and write latency, and (very importantly) run the existing PostgreSQL application without an expensive rewrite. YugabyteDB, essentially a turbocharged distributed version of PostgreSQL, was chosen for this purpose.
YugabyteDB Architecture
YugabyteDB was deployed as a stretch cluster across three regions: the on-prem PDC* (Region 1) and FDC* (Region 2) data centers and the third cloud region on Azure (Central US), which was designated as Region 3. Both on-prem regions were set up as preferred regions.
*NOTE: The significance of this naming will become apparent further down this blog when we discuss row-level security.

Three nodes are deployed in each region, creating a nine-node, synchronous universe with a replication factor of three (RF=3). Each on-prem region hosts an application server, and application users are typically assigned to the server closest to them.
NOTE: Although the Azure region is part of the stretch cluster and is “online,” the application was designed not to connect to it under normal operating conditions. The Azure region holds a copy of the data for the tables. Its presence ensures data redundancy and enhances the system’s overall resilience, ensuring everything remains up and running if one of the on-prem data centers fails.
Achieving Low Latency With No Application Changes
Tablespaces, locality-optimized workloads, and row-level geo-partitioning were all implemented to reduce latencies by keeping the needed data close to the user.
To ensure no app changes were required, YugabyteDB introduced a powerful feature, locality-optimized geo-partitioning,* which allows for the addition of a new column to tables, specifically a ‘dc’ (i.e. data center) column, which (in this case) will default to the user’s assigned region automatically.
*NOTE: Locality-optimized geo-partitioning combines PostgreSQL’s concepts of partitioning and tablespaces, enhancing performance.
Let me walk through an example of how this was done.
Locality-Optimized Geo-Partitioning
In this example (below), I set up a new main table called ‘test_geo’.*

I then replicated the columns from my main table along with a new ‘dc’ column representing “data center.” As mentioned above, this ‘dc’ column defaults to the value returned by the ‘yb_server_region’ function which dynamically identifies the region (FDC, PDC, or Azure) based on the cluster configuration defined in the cloud location parameter.
*NOTE: For illustration purposes, I utilized a single-node server, whereas for the actual use case these were physical nodes.
For the ‘test_geo’ table, I then created specific partitions—one for PDC, one for FDC, and one for Azure (not shown)—each residing in its respective tablespace and limited to a single region.
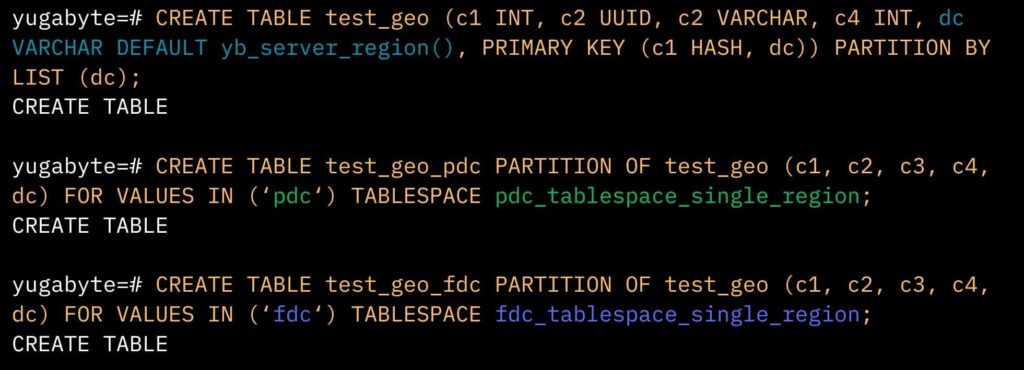
This means all data for each partition is stored in its corresponding region, whether PDC or FDC. If the FDC region (for example) fails, querying the FDC partition would retrieve data from the PDC.
The ability of the ‘dc’ column to default to the ‘yb_server_region’ was crucial, to keep from having to modify the application. By making this modification to the database table instead, no app changes were necessary.
Writes Without Rewriting App
When data is explicitly inserted into this table through the authenticator application, the values are entered as specified. However, if the ‘dc’ column isn’t explicitly listed in the application’s INSERT INTO statements, it’s no big deal. YugabyteDB will intelligently assign the ‘DC’ value based on the server connection, streamlining the data insertion process in a region-specific manner.
Let’s look at an example of this.
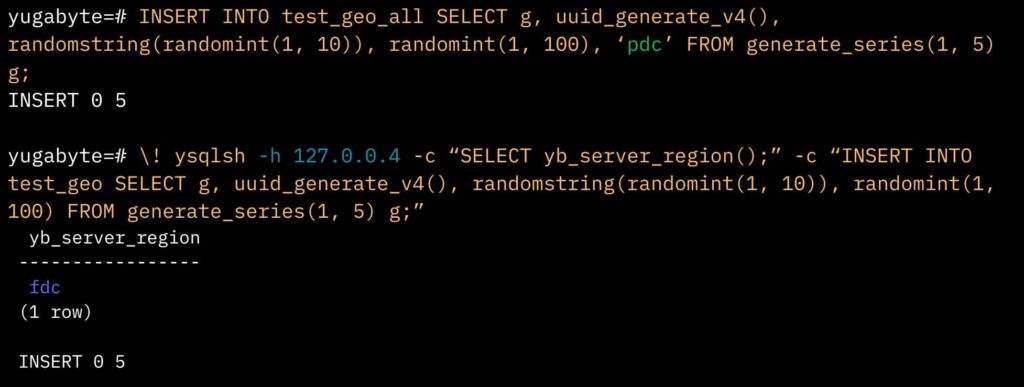
As you can see, manually loading data (INSERT INTO) and explicitly specifying “PDC” overrides the default setting. But if I’m automatically connected to a specific server in the FDC region (e.g., 127.0.0.4) and execute the ‘SELECT yb_server_region’ command, the default ‘FDC’ is used.
Queries Without Rewriting App
But would there need to be modifications to the application’s existing queries?
Implementing row-level security (RLS) streamlined query management by eliminating the need for every query to include a specific “WHERE” (e.g., “WHERE DC=XX) clause. This enhanced efficiency without forcing any changes to the application’s query structure.
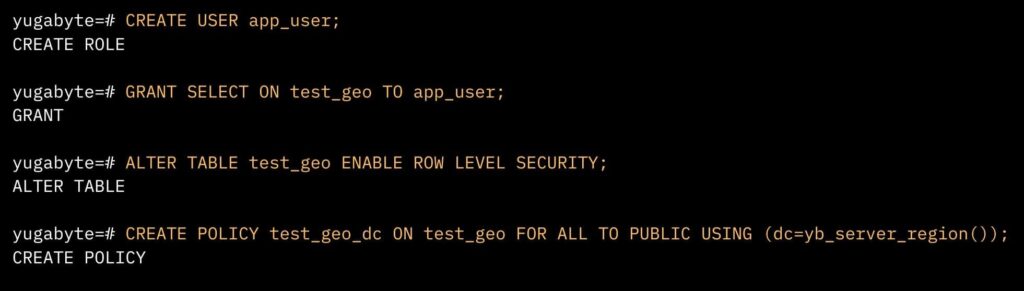
In the example (above), an app user was granted SELECT ON access to the main table (‘test_geo’). Then a new row-level security policy was created. This policy uses ‘dc=yb_server_region’ to automatically append the server’s region (that the user is connected to) to each query.
So if the app user is connected to a PDC node, the query automatically includes ‘WHERE dc = pdc,’ and for an FDC node, it adds ‘WHERE dc = fdc’.
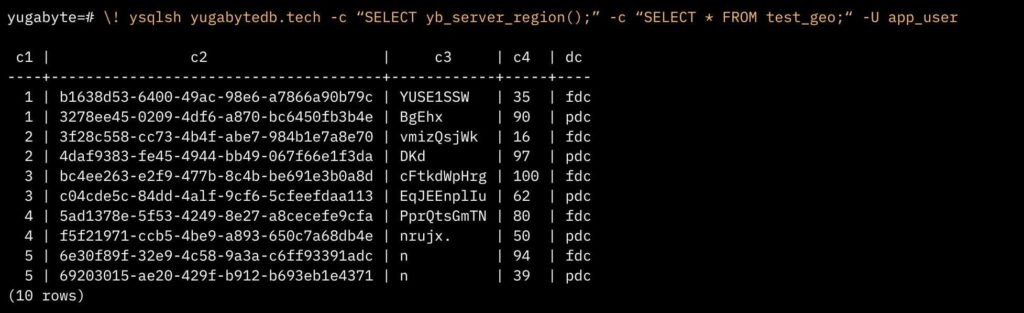
In the first example below, the app user is connected to a node in PDC (Region 1) and executes a query showing the region as PDC. Although the query does not include a ‘WHERE’ clause, the system automatically applies ‘WHERE dc = pdc’, demonstrating the integrated functionality.
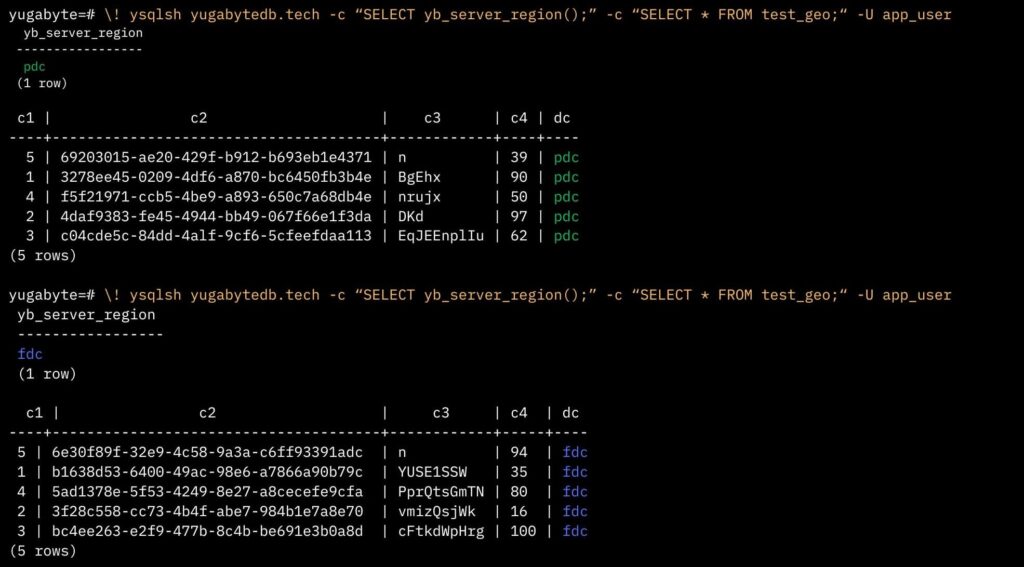
Similarly, if the app user is connected to an FDC node (127.0.0.4) and the same query is run, only rows from FDC are returned, highlighting the system’s ability to adapt queries based on the connected node’s region.

When connected to the Azure region (represented by 127.0.0.7), the query returned no rows, since we are dynamically applying a WHERE clause and there are no localized rows in the tables for Region 3.
No application changes are needed, and it can be changed at the database, user, or session level. The logistics company was pleased with this streamlined, no-modification-required solution.
Lowering Latency: The Results With No App Rewrites

As mentioned at the beginning, the response time for this workload in PostgreSQL was 102 milliseconds, and in Oracle, it was 19.8 milliseconds.
YugabyteDB achieved a workload runtime of 43.7 milliseconds, surpassing Postgres and achieving performance levels nearly equivalent to Oracle but running in a distributed database architecture.
The client’s objective was to transition off of Oracle, but their ultimate goal was to adopt YugabyteDB distributed architecture and capitalize on its superior resiliency. While Postgres was a viable option, developing resilient/low-latency solutions was extremely complex and time-consuming. The Yugabyte database was a clear winner, providing the required resilience while also delivering significantly better response times than PostgreSQL.
Additional Resources
Published at DZone with permission of Jim Knicely. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments