Hello YugabyteDB: Running Kong on the Distributed PostgreSQL Database
This guide demonstrates how to eliminate this final bottleneck by running Kong on YugabyteDB, a distributed SQL database built on PostgreSQL.
Join the DZone community and get the full member experience.
Join For FreeIn my previous articles, we've discussed in detail how to architect global API layers and multi-region service meshes using Kong and YugabyteDB. However, the solutions presented still harbored a bottleneck and a single point of failure: the database Kong uses internally to store its metadata and application-specific configurations. This guide demonstrates how to eliminate this final bottleneck by running Kong on YugabyteDB, a distributed SQL database built on PostgreSQL.
Kong's Default Database
Kong uses PostgreSQL as a database for its own needs. Taking a look at the database schema created by Kong during the bootstrap process, you'll find dozens of tables and other database objects that store metadata and application-specific configurations:
kong=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------------------------+-------+----------
public | acls | table | postgres
public | acme_storage | table | postgres
public | basicauth_credentials | table | postgres
public | ca_certificates | table | postgres
public | certificates | table | postgres
public | cluster_events | table | postgres
public | clustering_data_planes | table | postgres
public | consumers | table | postgres
public | filter_chains | table | postgres
public | hmacauth_credentials | table | postgres
public | jwt_secrets | table | postgres
public | key_sets | table | postgres
public | keyauth_credentials | table | postgres
public | keys | table | postgres
.. the list goes onPostgreSQL serves perfectly well those Kong deployments that don't need to scale across multiple availability zones, regions, or data centers. However, when an application needs to deploy Kong Gateway or Kong Mesh across various locations, a standalone PostgreSQL server can become a bottleneck or single point of failure.
Initially, Kong offered Apache Cassandra as an alternative to PostgreSQL for those wishing to architect distributed APIs and service meshes. But later, Cassandra support was officially deprecated. Kong team stated that PostgreSQL would remain the only officially supported database.
Why Distributed PostgreSQL?
Even though Cassandra was deprecated, the demand for a distributed version of Postgres by Kong users didn't wane, driven by several reasons:
- High availability: API layers and service meshes must be resilient against all kinds of potential outages, including zone and region-level incidents.
- Scalability: From global load balancers to the API and database layers, the entire solution needs to handle both read and write workloads at low latency.
- Data regulations: When an API or mesh spans multiple jurisdictions, certain API endpoints may be required to store specific settings and configurations within data centers located in a particular geography.
As a result, members from both the Kong and YugabyteDB communities began to work on adapting YugabyteDB for distributed Kong deployments.
Why YugabyteDB?
YugabyteDB is a distributed SQL database that is built on PostgreSQL. The upper half of YugabyteDB, the query layer, is PostgreSQL, with modifications needed for the YugabyteDB's distributed storage layer. Essentially, you can think of YugabyteDB as a distributed Postgres.
Provided that YugabyteDB maintains feature and runtime compatibility with Postgres, the majority of applications, libraries, drivers, and frameworks designed for Postgres should operate seamlessly with YugabyteDB, requiring no code changes. For instance, one of the earlier articles shows how to deploy Kubernetes on YugabyteDB, using the integration initially created for Postgres.
Back in 2022, following the Cassandra deprecation, Kong was not compatible with YugabyteDB due to the absence of certain Postgres features in the distributed database engine. However, this changed with the release of YugabyteDB version 2.19.2, which included support for all the features necessary for Kong.
Next, we'll explore how to get Kong Gateway up and running on a multi-node YugabyteDB cluster.
Starting a Multi-Node YugabyteDB Cluster
There are many ways to start Kong Gateway and YugabyteDB. One of the options is to run everything inside Docker containers. So, let's use this approach today:
First off, create a custom docker network for YugabyteDB and Kong containers:
docker network create custom-networkNext up, get a three-node YugabyteDB cluster running:
mkdir $HOME/yb_docker_data
docker run -d --name yugabytedb_node1 --net custom-network \
-p 15433:15433 -p 7001:7000 -p 9001:9000 -p 5433:5433 \
-v $HOME/yb_docker_data/node1:/home/yugabyte/yb_data --restart unless-stopped \
yugabytedb/yugabyte:latest \
bin/yugabyted start --base_dir=/home/yugabyte/yb_data --daemon=false
docker run -d --name yugabytedb_node2 --net custom-network \
-p 15434:15433 -p 7002:7000 -p 9002:9000 -p 5434:5433 \
-v $HOME/yb_docker_data/node2:/home/yugabyte/yb_data --restart unless-stopped \
yugabytedb/yugabyte:latest \
bin/yugabyted start --join=yugabytedb_node1 --base_dir=/home/yugabyte/yb_data --daemon=false
docker run -d --name yugabytedb_node3 --net custom-network \
-p 15435:15433 -p 7003:7000 -p 9003:9000 -p 5435:5433 \
-v $HOME/yb_docker_data/node3:/home/yugabyte/yb_data --restart unless-stopped \
yugabytedb/yugabyte:latest \
bin/yugabyted start --join=yugabytedb_node1 --base_dir=/home/yugabyte/yb_data --daemon=falseAnd finally, verify the cluster's status by going to the YugabyteDB UI here:
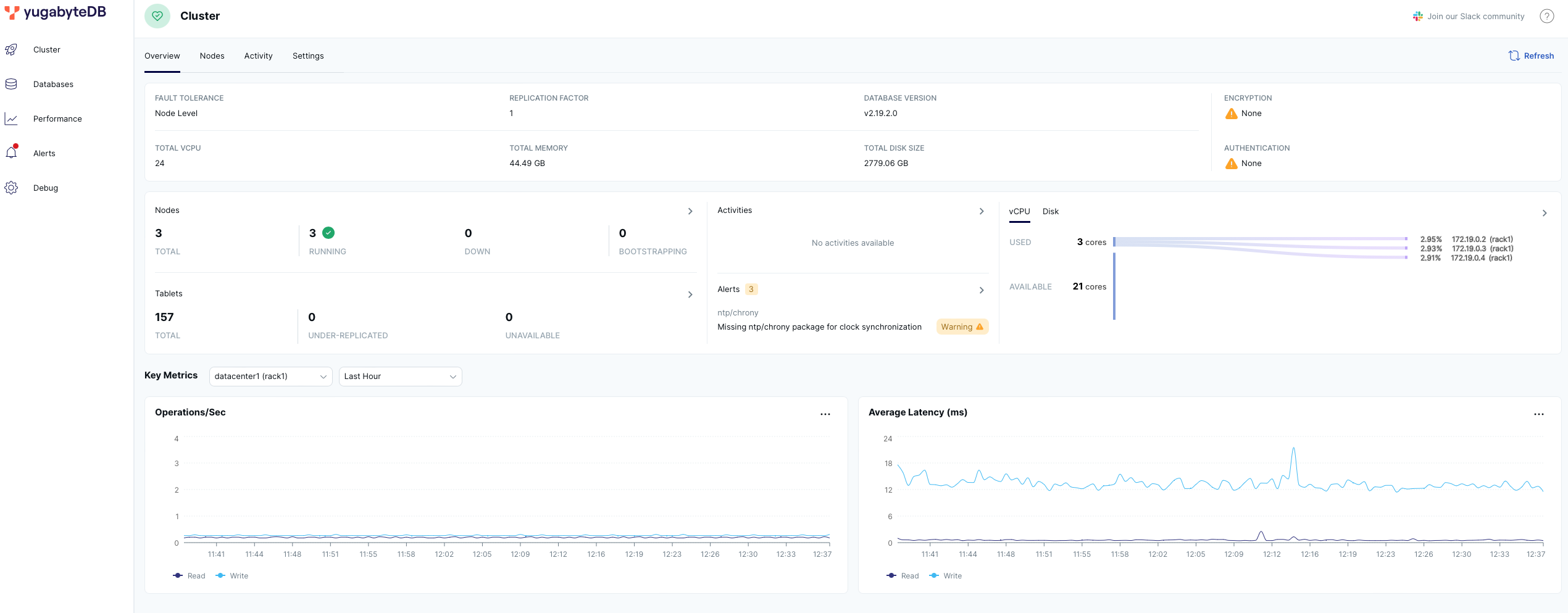
Starting Kong Gateway
To deploy Kong Gateway on YugabyteDB using Docker, follow the steps below.
First, connect to YugabyteDB and create the kong database using psql or your preferred SQL tool:
psql -h 127.0.0.1 -p 5433 -U yugabyte
create database kong;
\q
Next, start the Kong bootstrapping and migration process:
docker run --rm --net custom-network \
-e "KONG_DATABASE=postgres" \
-e "KONG_PG_HOST=yugabytedb_node1" \
-e "KONG_PG_PORT=5433" \
-e "KONG_PG_USER=yugabyte" \
-e "KONG_PG_PASSWORD=yugabyte" \
kong:latest kong migrations bootstrapKONG_DATABASE: is set topostgres, which directs Kong to continue using the PostgreSQL implementation for its metadata storage.KONG_PG_HOST: Kong can interface with any node within the YugabyteDB cluster. The chosen node will route Kong's requests and manage their execution across the cluster.
The bootstrapping process can take up to 5 minutes, during which there may be no log output. Once completed, the following log messages will indicate the happy end:
....
migrating response-ratelimiting on database 'kong'...
response-ratelimiting migrated up to: 000_base_response_rate_limiting (executed)
migrating session on database 'kong'...
session migrated up to: 000_base_session (executed)
session migrated up to: 001_add_ttl_index (executed)
session migrated up to: 002_320_to_330 (executed)
58 migrations processed
58 executed
Database is up-to-dateFinally, launch the Kong Gateway container, configured to utilize YugabyteDB as the database backend:
docker run -d --name kong-gateway \
--net custom-network \
-e "KONG_DATABASE=postgres" \
-e "KONG_PG_HOST=yugabytedb_node1" \
-e "KONG_PG_PORT=5433" \
-e "KONG_PG_USER=yugabyte" \
-e "KONG_PG_PASSWORD=yugabyte" \
-e "KONG_PROXY_ACCESS_LOG=/dev/stdout" \
-e "KONG_ADMIN_ACCESS_LOG=/dev/stdout" \
-e "KONG_PROXY_ERROR_LOG=/dev/stderr" \
-e "KONG_ADMIN_ERROR_LOG=/dev/stderr" \
-e "KONG_ADMIN_LISTEN=0.0.0.0:8001, 0.0.0.0:8444 ssl" \
-p 8000:8000 \
-p 8443:8443 \
-p 127.0.0.1:8001:8001 \
-p 127.0.0.1:8444:8444 \
kong:latestTest Kong’s operation by sending a request to the Gateway:
curl -i -X GET --url http://localhost:8001/servicesThen, return to the YugabyteDB UI, selecting 'kong' from the 'Databases' menu to view the dozens of tables and indexes Kong uses internally.
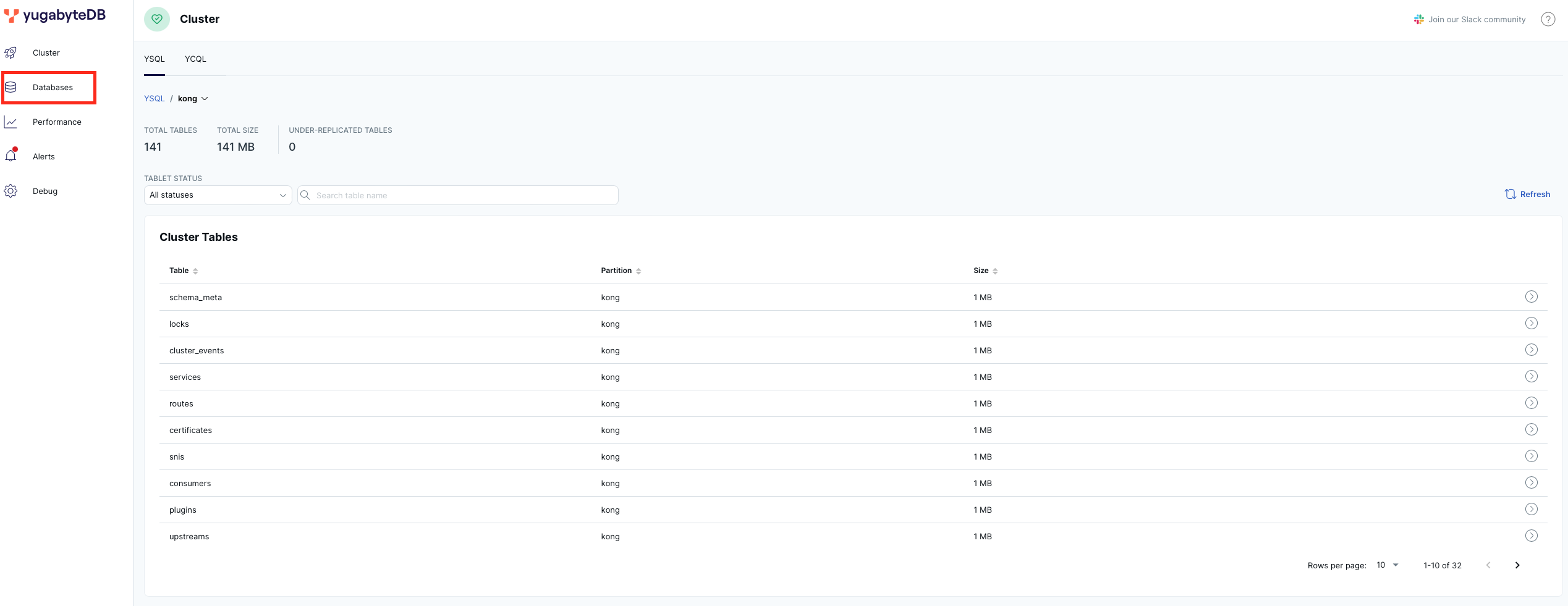
Job done!
In Summary
Even though the Kong team stopped supporting Cassandra for distributed deployments, their initial bet on PostgreSQL paid off over time. As one of the fastest-growing databases, Postgres has a rich ecosystem of extensions and other products that extend its use cases. Kong users required a distributed version of Postgres for APIs and service meshes spanning various locations, and that use case was eventually addressed by YugabyteDB, a distributed database built on PostgreSQL.
Opinions expressed by DZone contributors are their own.
Comments