Failure Is Required: Understanding Fail-Safe and Fail-Fast Strategies
Learn how embracing failure can improve your app's quality, leading to early error detection, robust error handling, and better overall stability.
Join the DZone community and get the full member experience.
Join For FreeFailures in software systems are inevitable. How these failures are handled can significantly impact system performance, reliability, and the business’s bottom line. In this post, I want to discuss the upside of failure. Why you should seek failure, why failure is good, and why avoiding failure can reduce the reliability of your application. We will start with the discussion of fail-fast vs. fail-safe, this will take us to the second discussion about failures in general.
As a side note, if you like the content of this and the other posts in this series check out my Debugging book that covers this subject. If you have friends that are learning to code I'd appreciate a reference to my Java Basics book. If you want to get back to Java after a while check out my Java 8 to 21 book.
Fail-Fast
Fail-fast systems are designed to immediately stop functioning upon encountering an unexpected condition. This immediate failure helps to catch errors early, making debugging more straightforward.
The fail-fast approach ensures that errors are caught immediately. For example, in the world of programming languages, Java embodies this approach by producing a NullPointerException instantly when encountering a null value, stopping the system, and making the error clear. This immediate response helps developers identify and address issues quickly, preventing them from becoming more serious.
By catching and stopping errors early, fail-fast systems reduce the risk of cascading failures, where one error leads to others. This makes it easier to contain and resolve issues before they spread through the system, preserving overall stability.
It is easy to write unit and integration tests for fail-fast systems. This advantage is even more pronounced when we need to understand the test failure. Fail-fast systems usually point directly at the problem in the error stack trace.
However, fail-fast systems carry their own risks, particularly in production environments:
- Production disruptions: If a bug reaches production, it can cause immediate and significant disruptions, potentially impacting both system performance and the business’s operations.
- Risk appetite: Fail-fast systems require a level of risk tolerance from both engineers and executives. They need to be prepared to handle and address failures quickly, often balancing this with potential business impacts.
Fail-Safe
Fail-safe systems take a different approach, aiming to recover and continue even in the face of unexpected conditions. This makes them particularly suited for uncertain or volatile environments.
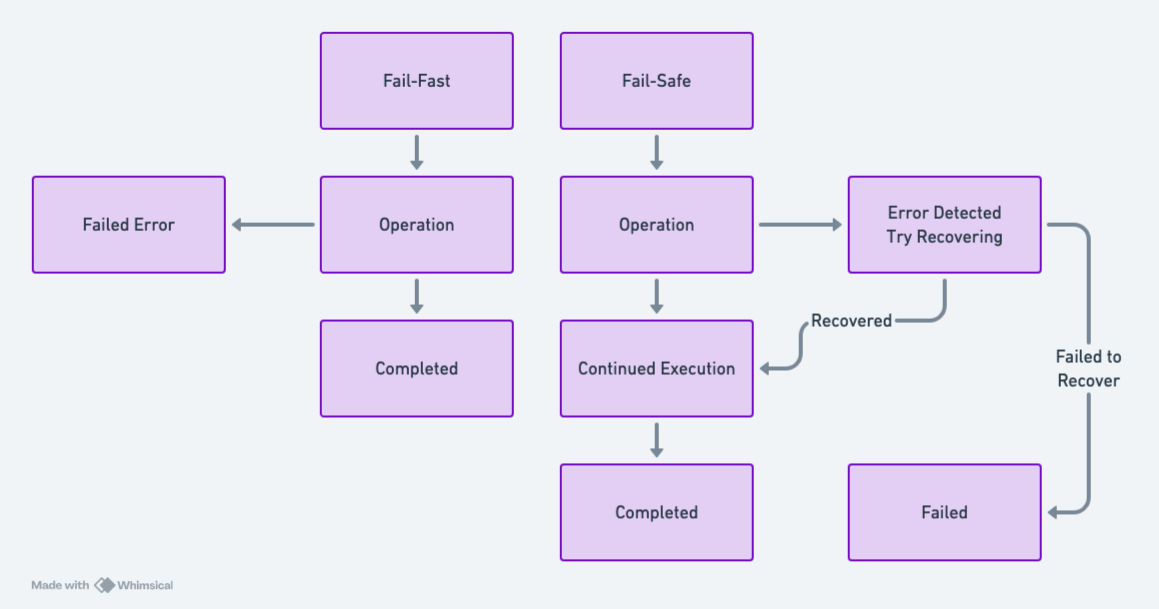
Microservices are a prime example of fail-safe systems, embracing resiliency through their architecture. Circuit breakers, both physical and software-based, disconnect failing functionality to prevent cascading failures, helping the system continue operating.
Fail-safe systems ensure that systems can survive even harsh production environments, reducing the risk of catastrophic failure. This makes them particularly suited for mission-critical applications, such as in hardware devices or aerospace systems, where smooth recovery from errors is crucial.
However, fail-safe systems have downsides:
- Hidden errors: By attempting to recover from errors, fail-safe systems can delay the detection of issues, making them harder to trace and potentially leading to more severe cascading failures.
- Debugging challenges: This delayed nature of errors can complicate debugging, requiring more time and effort to find and resolve issues.
Choosing Between Fail-Fast and Fail-Safe
It's challenging to determine which approach is better, as both have their merits. Fail-fast systems offer immediate debugging, lower risk of cascading failures, and quicker detection and resolution of bugs. This helps catch and fix issues early, preventing them from spreading.
Fail-safe systems handle errors gracefully, making them better suited for mission-critical systems and volatile environments, where catastrophic failures can be devastating.
Balancing Both
To leverage the strengths of each approach, a balanced strategy can be effective:
- Fail-fast for local services: When invoking local services like databases, fail-fast can catch errors early, preventing cascading failures.
- Fail-safe for remote resources: When relying on remote resources, such as external web services, fail-safe can prevent disruptions from external failures.
A balanced approach also requires clear and consistent implementation throughout coding, reviews, tooling, and testing processes, ensuring it is integrated seamlessly. Fail-fast can integrate well with orchestration and observability. Effectively, this moves the fail-safe aspect to a different layer of OPS instead of into the developer layer.
Consistent Layer Behavior
This is where things get interesting. It isn't about choosing between fail-safe and fail-fast. It's about choosing the right layer for them. E.g. if an error is handled in a deep layer using a fail-safe approach, it won't be noticed. This might be OK, but if that error has an adverse impact (performance, garbage data, corruption, security, etc.) then we will have a problem later on and won't have a clue.
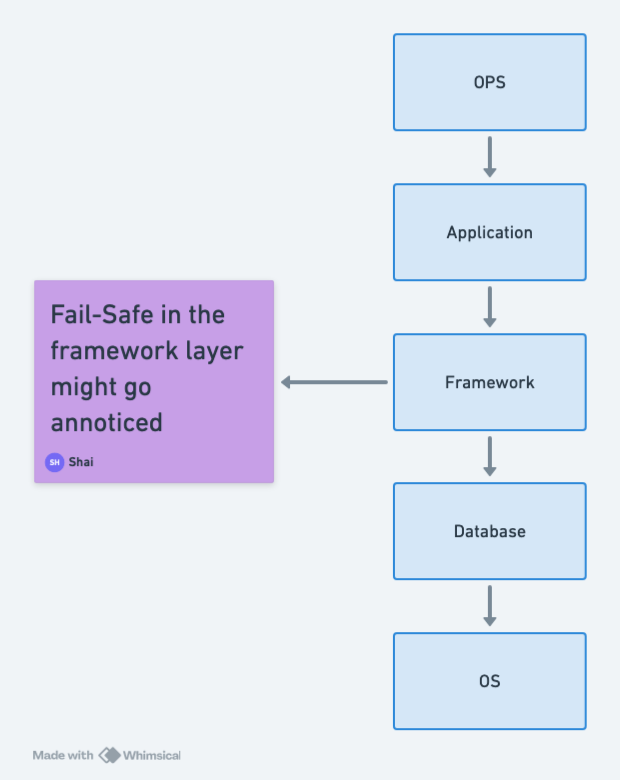
The right solution is to handle all errors in a single layer, in modern systems the top layer is the OPS layer and it makes the most sense. It can report the error to the engineers who are most qualified to deal with the error. But they can also provide immediate mitigation such as restarting a service, allocating additional resources, or reverting a version.
Retry’s Are Not Fail-Safe
Recently I was at a lecture where the speakers listed their updated cloud architecture. They chose to take a shortcut to microservices by using a framework that allows them to retry in the case of failure. Unfortunately, failure doesn't behave the way we would like. You can't eliminate it completely through testing alone. Retry isn't fail-safe. In fact: it can mean catastrophe.
They tested their system and "it works", even in production. But let's assume that a catastrophic situation does occur, their retry mechanism can operate as a denial of service attack against their own servers. The number of ways in which ad-hoc architectures such as this can fail is mind-boggling.
This is especially important once we redefine failures.
Redefining Failure
Failures in software systems aren't just about crashes. A crash can be seen as a simple and immediate failure, but there are more complex issues to consider. In fact, crashes in the age of containers are probably the best failures. A system restarts seamlessly with barely an interruption.
Data Corruption
Data corruption is far more severe and insidious than a crash. It carries with it long-term consequences. Corrupted data can lead to security and reliability problems that are challenging to fix, requiring extensive reworking and potentially unrecoverable data.
Cloud computing has led to defensive programming techniques, like circuit breakers and retries, emphasizing comprehensive testing and logging to catch and handle failures gracefully. In a way, this environment sent us back in terms of quality.
A fail-fast system at the data level could stop this from happening. Addressing a bug goes beyond a simple fix. It requires understanding its root cause and preventing reoccurrence, extending into comprehensive logging, testing, and process improvements. This ensures that the bug is fully addressed, reducing the chances of it reoccurring.
Don't Fix the Bug
If it's a bug in production you should probably revert, if you can't instantly revert production. This should always be possible and if it isn't this is something you should work on.
Failures must be fully understood before a fix is undertaken. In my own companies, I often skipped that step due to pressure, in a small startup that is forgivable. In larger companies, we need to understand the root cause. A culture of debriefing for bugs and production issues is essential. The fix should also include process mitigation that prevents similar issues from reaching production.
Debugging Failure
Fail-fast systems are much easier to debug. They have inherently simpler architecture and it is easier to pinpoint an issue to a specific area. It is crucial to throw exceptions even for minor violations (e.g. validations). This prevents cascading types of bugs that prevail in loose systems.
This should be further enforced by unit tests that verify the limits we define and verify proper exceptions are thrown. Retries should be avoided in the code as they make debugging exceptionally difficult and their proper place is in the OPS layer. To facilitate that further, timeouts should be short by default.
Avoiding Cascading Failure
Failure isn't something we can avoid, predict, or fully test against. The only thing we can do is soften the blow when a failure occurs. Often this "softening" is achieved by using long-running tests meant to replicate extreme conditions as much as possible with the goal of finding our application's weak spots. This is rarely enough, robust systems need to revise these tests often based on real production failures.
A great example of a fail-safe would be a cache of REST responses that lets us keep working even when a service is down. Unfortunately, this can lead to complex niche issues such as cache poisoning or a situation in which a banned user still had access due to cache.
Hybrid in Production
Fail-safe is best applied only in production/staging and in the OPS layer. This reduces the amount of changes between production and dev, we want them to be as similar as possible, yet it's still a change that can negatively impact production. However, the benefits are tremendous as observability can get a clear picture of system failures.
The discussion here is a bit colored by my more recent experience of building observable cloud architectures. However, the same principle applies to any type of software whether embedded or in the cloud. In such cases we often choose to implement fail-safe in the code, in this case, I would suggest implementing it consistently and consciously in a specific layer.
There's also a special case of libraries/frameworks that often provide inconsistent and badly documented behaviors in these situations. I myself am guilty of such inconsistency in some of my work. It's an easy mistake to make.
Final Word
This is my last post on the theory of debugging series that's part of my book/course on debugging. We often think of debugging as the action we take when something fails, it isn't. Debugging starts the moment we write the first line of code. We make decisions that will impact the debugging process as we code, often we're just unaware of these decisions until we get a failure.
I hope this post and series will help you write code that is prepared for the unknown. Debugging, by its nature, deals with the unexpected. Tests can't help. But as I illustrated in my previous posts, there are many simple practices we can undertake that would make it easier to prepare. This isn't a one-time process, it's an iterative process that requires re-evaluation of decisions made as we encounter failure.
Published at DZone with permission of Shai Almog, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments