Effective Prompt Engineering Principles for Generative AI Application
In this article, I'll walk you through the concept and principles of effective prompt engineering techniques using Langchain and OpenAI ChatGPT API.
Join the DZone community and get the full member experience.
Join For FreeIn this article, I'll walk you through another important concept of Generative AI Prompt Engineering. Prompt Engineering in the field of AI, involves the creation of concise pieces of text or phrases designed according to specific principles. These prompts are then utilized with Large Language Models (LLMs) to generate output content effectively. The process of prompt engineering serves as a crucial building block because improperly constructed prompts can lead to LLM models like ChatGPT generating illogical, meaningless, or out-of-context responses. Therefore, it is considered a best practice to validate the input texts passed to the LLM model's API based on well-defined principles of prompt engineering.
Depending on the intent or purpose of the input phrases, the model can exhibit various capabilities. These may include summarizing extensive pools of texts or content, inferring or clarifying topics, transforming the input texts, or expanding upon the provided information. By adhering to the principles of prompt engineering, the AI model can harness its full potential while ensuring accurate and contextually relevant output.
Why Prompt Engineering Is Important While Designing a Generative AI-Based Product?
As you see effective prompt would yield the best response from the Large Language Model that would be used in the AI product we will be building. If enough brainstorming is not done while designing the Prompts for the inbound instruction or query sent to the LLM, the application may not fulfill the user's satisfaction. So when we are designing the Generative AI-based product, we should engage the Prompt Engineers or Natural Language Analysts to deep dive and select effective prompts to be selected while interacting with the LLM model. Even if the product is going to generate dynamic prompts, it should follow clear guidelines and principles to generate accurate results for the users.
In the following sections, I'll walk you through some sample prompts, techniques, and responses from the LLM to demonstrate how to use prompt engineering and why we have it as an important building block.
I'll be using Python code and Open AI's "text-davinci-003" LLM model with the temperature set to 0 so that the answers from the LLM always remain consistent and not random.
Before running the code snippet, make sure to install the required package.
pip openai
pip langchainThe following simple code snippet shows a quick prompting with OpenAI.
from langchain.llms.openai import OpenAI
OPEMAI_API_KEY = "<your API key>"
llm = OpenAI(model_name='text-davinci-003', openai_api_key=OPEMAI_API_KEY)
prompt_text = "Can you suggest some popular Indian breakfast meals?"
print(llm(prompt_text))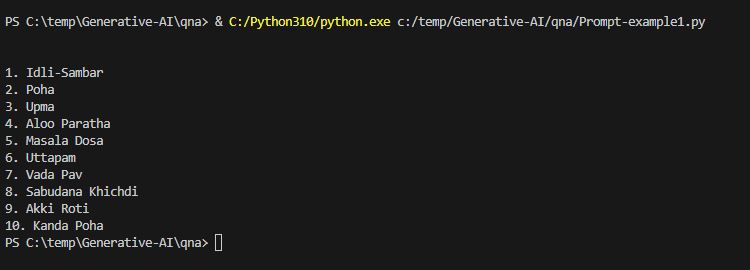
In the following examples, I'll be using Langchain's built-in PromptTemplate class to demonstrate some principles we should follow strictly while designing the effective prompts for our NextGen AI project as part of the Prompt Engineering.
Principles (Best Practices) of Effective Prompt Engineering:
There are no predefined hard and fast rules for prompt engineering. There is no rulebook published by any committee that we should be adhering to while doing prompt engineering. However, if we follow some guidelines and principles as best practices, it would help to get the best output generated from the LLM and results in customer satisfaction.
Instructions Should Be CLEAR and SPECIFIC
Let's see a couple of examples.
In the first example, I'll ask the model to summarize some supplied contents I got from Wikipedia. I'll instruct the model to summarize only whatever is mentioned within the triple backticks (```)
from langchain import PromptTemplate
from langchain.llms.openai import OpenAI
OPEMAI_API_KEY = "<Insert Your OpenAI API Key here>"
llm = OpenAI(model_name='text-davinci-003', openai_api_key=OPEMAI_API_KEY)
template = """Summarize the content delimited by triple backticks into one single sentence.```{input_content}```"""
content = """LangChain is a framework designed to simplify the creation of applications
using large language models (LLMs). As a language model integration framework,
LangChain's use-cases largely overlap with those of language models in general,
including document analysis and summarization, chatbots, and code analysis"""
prompt = PromptTemplate(template=template, input_variables=['input_content'])
print("###################### Formatted Prompt Template to pass to the LLM ######################")
prompt_text = prompt.format(input_content=content)
print(prompt_text + "\n")
print("###################### Output from the LLM ######################")
print(llm(prompt_text))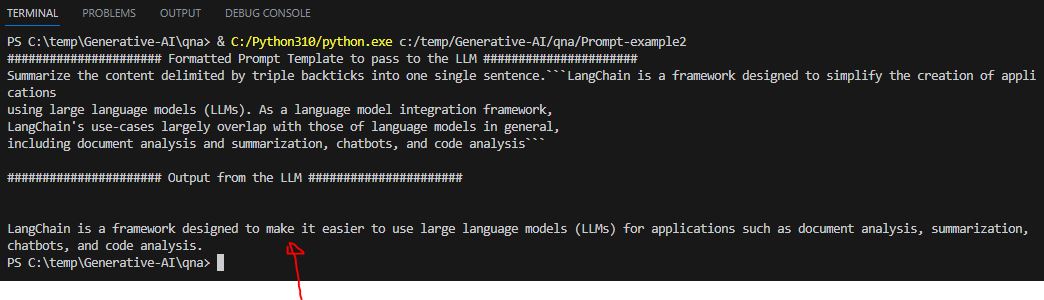
When you put your context within a delimiter and add the instruction, you not only stop any wrong prompt injection but also clearly ask the LLM what to do with the supplied content.
In the following example, I'll show how the output from the model can be controlled. For example, I'll ask the model to generate three made-up movie titles in JSON format.
from langchain.llms.openai import OpenAI
OPEMAI_API_KEY = "<Your API key from OpenAI>"
llm = OpenAI(model_name='text-davinci-003', openai_api_key=OPEMAI_API_KEY)
input_instruction = """Generate 3 hollywood fictitious movie titles with director names,
future release dates of year 2050, lead actor and actress in JSON format"""
print(llm(input_instruction))
Provide Meaningful Reference Text or Content for the LLM
While sending the prompts to the LLM, if you would like to keep the answers within the supplied context, then a concise reference should be provided. OpenAI GPT has limitations on the input reference, so you need to put a lot of effort into designing the reference content. Providing effective and correct references would help get the best output from the LLM.
from langchain import PromptTemplate
from langchain.llms.openai import OpenAI
OPEMAI_API_KEY = "<Insert your OpenAI API key>"
llm = OpenAI(model_name='text-davinci-003', openai_api_key=OPEMAI_API_KEY)
template = """Read the Context provided and answer the following question within the Context.
Context: There are six main areas that LangChain is designed to help with. These are, in increasing order of complexity,
LLMs and Prompts- This includes prompt management, prompt optimization, a generic interface for all LLMs, and common utilities for working with LLMs.
Chains- Chains go beyond a single LLM call and involve sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
Data Augmented Generation- Data Augmented Generation involves specific types of chains that first interact with an external data source to fetch data for use in the generation step. Examples include summarization of long pieces of text and question/answering over specific data sources.
Agents- Agents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end-to-end agents.
Memory- Memory refers to persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.
Evaluation- Generative models are notoriously hard to evaluate with traditional metrics.
Question: {question}
Answer:"""
input_question = """ What is LangChain useful for?"""
prompt = PromptTemplate(template=template, input_variables=['question'])
print("###################### Formatted Prompt Template to pass to the LLM ######################")
prompt_text = prompt.format(question=input_question)
print(prompt_text + "\n")
print("###################### Output from the LLM ######################")
print(llm(prompt_text))
Provide "Time to THINK" to the GPT
Prompt engineering should be designed in such a way that GPT shouldn't be rushing to answer; rather, it should do the THINKING and then provide the correct meaningful answer. If you are providing statistical or mathematical problems in wording and do not provide time to think, then most of the time LLM model also makes mistakes like how human does. So in order to get proper answers, your prompt engineering should utilize wordings in such a way that GPT should get some time to think and answer. Below examples would show how models can make mistakes and how to rectify that.
The following Prompts instruct the LLM to do certain tasks and don't provide clear instructions, so while rushing to the answer, the LLM makes a mistake and omits the instruction at no 3. See the results.
from langchain.llms.openai import OpenAI
OPEMAI_API_KEY = "<Your OpenAI key>"
llm = OpenAI(model_name='text-davinci-003', openai_api_key=OPEMAI_API_KEY)
input_instruction = """
Perform the following actions:
1 - Summarize the following Context in one sentence.
2 - Translate the summary into French.
3 - List each name in the French summary
4 - Output JSON with keys: french_summary, no_of_names
Separate your answer with line breaks.
Context: Satya Narayana Nadella was born in Hyderabad in Andhra Pradesh state, India into a Telugu-speaking Hindu family.
His mother Prabhavati was a Sanskrit lecturer and his father, Bukkapuram Nadella Yugandhar, was an Indian
Administrative Service officer of the 1962 batch.Satya Nadella did his MS in computer science at the University of Wisconsin-Milwaukee.
"""
print(llm(input_instruction))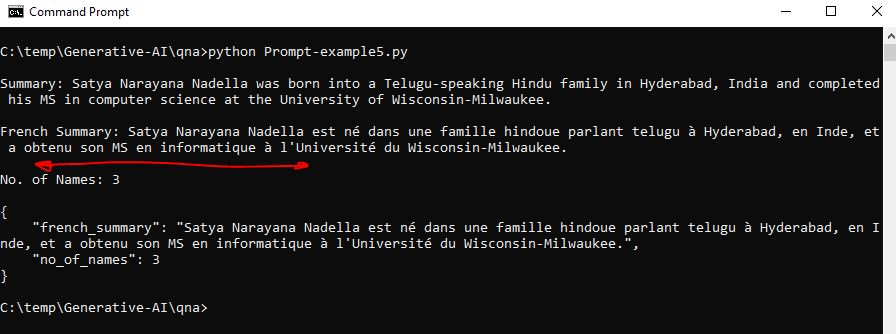
However, the same prompts with some change would provide more THINKING capability to the LLM to output correct results.
from langchain.llms.openai import OpenAI
OPEMAI_API_KEY = "Your API Key"
llm = OpenAI(model_name='text-davinci-003', openai_api_key=OPEMAI_API_KEY)
input_instruction = """
Perform the following actions:
1 - Summarize the following text delimited by [] in one sentence.
2 - Translate the summary into French.
3 - List each name in the French summary
4 - Output JSON with keys: french_summary, no_of_names
Use the following format:
Text: <text to summarize>
Summary: <summary>
Translation: <summary translation>
Names: <List of names in the French summary>
Output JSON: <json with french summary and num_names>
[Satya Narayana Nadella was born in Hyderabad in Andhra Pradesh state, India into a Telugu-speaking Hindu family.
His mother Prabhavati was a Sanskrit lecturer and his father, Bukkapuram Nadella Yugandhar, was an Indian
Administrative Service officer of the 1962 batch.Satya Nadella did his MS in computer science at the University of Wisconsin-Milwaukee.]
"""
print(llm(input_instruction))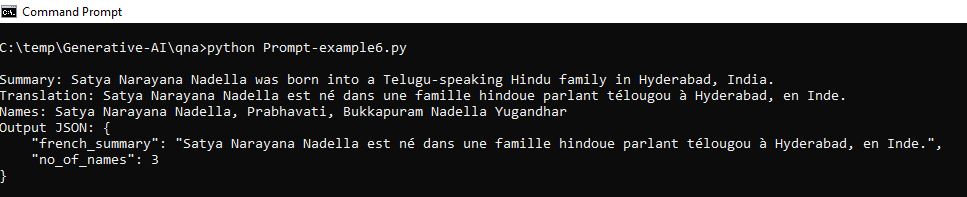
Do's and Don'ts
While doing effective, prompt engineering few things we should do and a few we should avoid, like:
Don'ts:
- Avoid providing overloaded information.
- Don't ask Open-ended questions which might confuse the LLM.
Do's:
- Specify the correct output format that you are expecting.
- Include meaningful context.
Conclusion
In this article, we explore valuable insights into effective prompting techniques. We also explored the significance of a well-crafted prompt and discussed essential guidelines, including dos and don'ts, for designing an effective prompt. Some practical examples are also included to illustrate these principles.
Opinions expressed by DZone contributors are their own.
Comments