Cross-Pollination for Creativity Leveraging LLMs
Building a RAG application to leverage ideas from one field to another boosting creativity.
Join the DZone community and get the full member experience.
Join For FreeLarge Language models (LLMs) are used for creative tasks such as story writing, poetry, and script writing for plays. There are several GPT-based wrapper tools for advertising slogan creation, generating plot lines, and music compositions. Let's explore how to use LLMs to identify research gaps in a field and leverage the ideas of other fields to inspire new ideas.
Problem Statement
Researchers need inspiration when they are stuck on a problem. It's common for researchers to get fixated on a particular hypothesis or approach. The vast amount of information can be overwhelming. It is a struggle in itself to sift through the information and identify a potential new path. Interdisciplinary collaboration is often challenging with researchers on both sides not familiar with the jargon of the two fields.
The Solution
We can build a solution using Retrieval Augmented Generation (RAG)
Retrieval: By building a vector database of all research articles, we can fetch relevant articles from two fields.
Generation: Once we retrieve the top articles relevant to the two fields, we can then build a prompt and ask the Large Language model to identify gaps in research field A and use articles from field B to come up with solutions.
Since we are forcing a field B, hallucination is expected. Hallucination is a not bug. It is a feature since we are promoting inspiration.
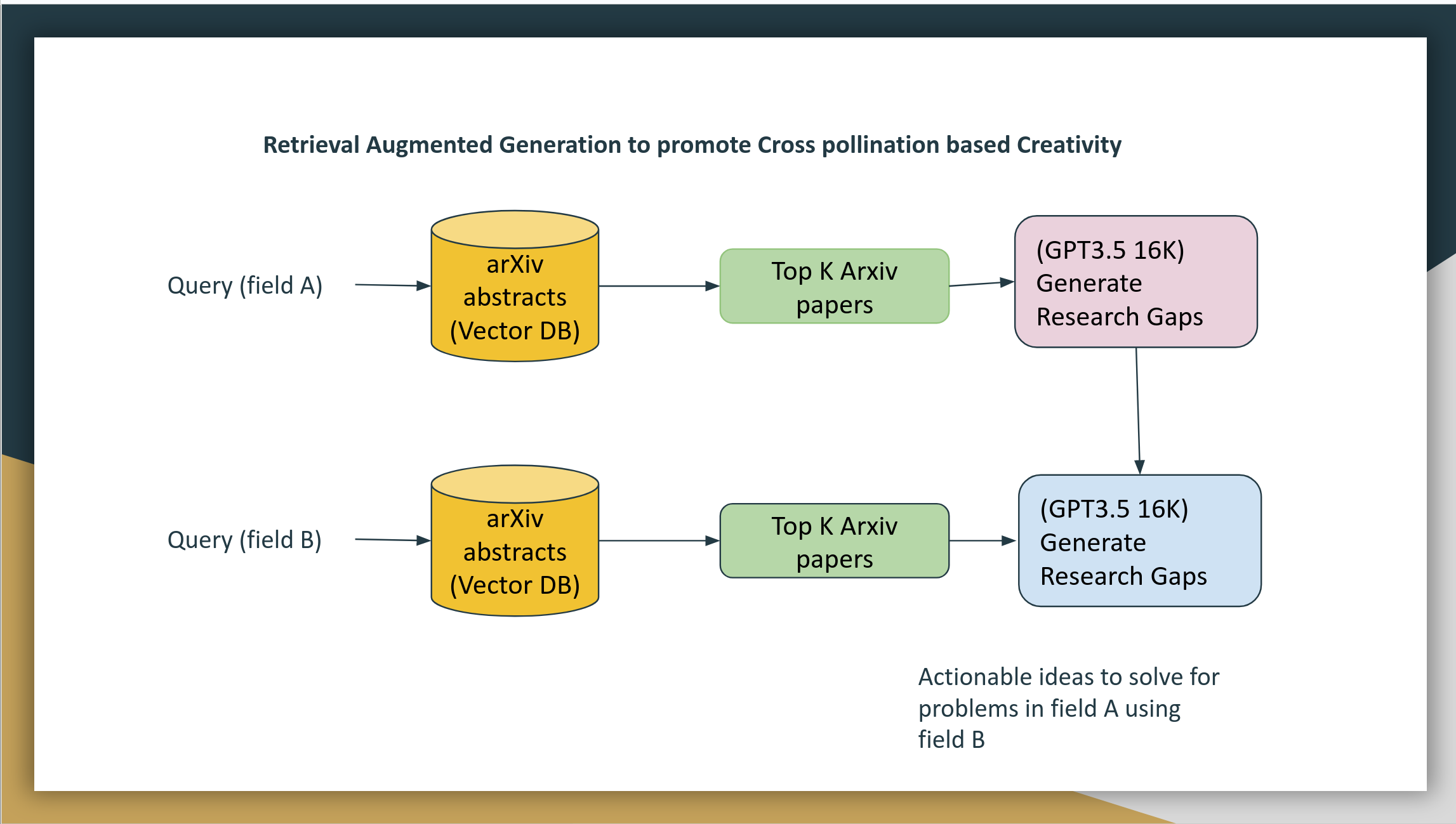
Figure: System design diagram of RAG system for cross-pollination
Building the Vector Index
prerequisite: Python 3.9, pip
1. pip install -r requirements.txt
numpy==1.25.2
torch==2.0.1
annoy==1.17.3
langchain==0.0.237
sentence-transformers==2.2.22. Kaggle arXiv dataset
Create a kaggle account and download the arXiv dataset. After downloading, unzip the file to find a JSON file. This is a limited dataset with a title, abstract, author, and submission date.
3. Build an annoy index using Sentence BERT
import json
from sentence_transformers import SentenceTransformer, util
import numpy as np
import torch
import time
from annoy import AnnoyIndex
file_name = "arxiv-metadata-oai-snapshot.json"
'''
Preprocess the data and build a list
'''
def preprocess(path):
data = []
start = time.time()
with open(path,'r') as f:
for line in f:
data.append(json.loads(line))
start = time.time()
sents = []
for i in range(len(data)):
sents.append(data[i]['title']+'[SEP]'+data[i]['abstract'])
end = time.time()
print("Time taken: ",end-start)
return sents
'''
Use Sentence BERT Specter embedding to build a numpy array
'''
def generate_embeddings(sents,model):
embeddings = model.encode(sents,batch_size=400,show_progress_bar=True,device='cuda',convert_to_numpy=True)
np.save("embeddings.npy",embeddings)
return embeddings
'''
Generate an annoy index.
Instead of choosing angular as distance metric, other options such as euclidean are also available
'''
def generate_annoy(embeddings):
n_trees = 256
embedding_size = 768
top_k_hits = 5
annoy_index = AnnoyIndex(embedding_size, 'angular')
for i in range(len(embeddings)):
annoy_index.add_item(i, embeddings[i])
annoy_index.build(n_trees)
annoy_index.save("vector_index.ann")
return annoy_index
sents = preprocess(file_name)
model = SentenceTransformer('sentence-transformers/allenai-specter', device='cuda')
embeddings = generate_embeddings(sents,model)
annoy_index = generate_annoy(embeddings)if you are running on GPU, adjust batch size appropriately
Prompt 1 - Retrieve Research Gaps
Now that we have built a vector index needed for retrieval, the first step is to retrieve the research gaps of field A
- Query vector index (annoy) to retrieve top K arXiv articles
- Build a prompt based on the title + abstract
- Use a large language model to retrieve research gaps
Our options for LLMs with large token lengths include
- GPT 3.5 with 16K token length
- Yi 34B model with 200K token length
- Anthropic Claude with 100K token length
Token length matters here since we are going to ask LLM to generate research gaps.
Set Up Sentence Bert, Load Annoy, Open AI Credential
model = SentenceTransformer('sentence-transformers/allenai-specter', device='cpu')
OPENAI_API_KEY = getpass("Please enter your OPEN AI API KEY to continue:")
## load the OPENAI LLM model
open_ai_key = OPENAI_API_KEY
sents_from_path = preprocess("<Path to your arxiv.json>")
## index from Annoy
an = generate_annoy("<name of the index.ann>")
llm = OpenAI(openai_api_key=open_ai_key, model_name= "gpt-3.5-turbo-16k")Methods for Retrieving Top K Articles and Metadata
def search(query,annoy_index,model, topK):
query_embedding = model.encode(query,convert_to_numpy=True)
tokens = query.strip().split()
hit_dict = {}
hits = annoy_index.get_nns_by_vector(query_embedding, topK, include_distances=True)
return [hits, hits]
def collect_results(hits,sents, path, prefix=""):
response = ""
for i in range(len(hits[0])):
response += "result " + prefix + str(i) + "\n"
response += "Title:" + sents[hits[0][i]].split('[SEP]')[0] + "\n"
response += "Abstract: " + sents[hits[0][i]].split('[SEP]')[1] + "\n"
return responseConstruct the Prompt for Identifying Research Gaps
fieldA = input("Describe the field (or subfield) as a query:")
query = fieldA
response = collect_results(search(query,an,model,30),sents_from_path1, path1)
template = """ Take a deep breath.
You are a researcher in the FIELD of {query}. You are tasked with identifying research gaps and opportunities. User entered the FIELD. The TOP ARTICLES from the search engine are {response}. Analyze the results and follow the instructions below to identify research gaps in the field of {query}.
TASK DESCRIPTION
In this task, your goal is to recognize areas within a specified FIELD where further research is needed.
By analyzing existing literature and TOP ARTICLES , data, and perhaps the trajectories of ongoing research, the AI can help point out topics or questions that haven't been adequately explored or resolved. This is essential for advancing knowledge and finding new directions that could lead to significant discoveries or developments
For example, consider the domain of renewable energy. one might analyze a vast number of research papers, patents, and ongoing projects in this domain. It could then identify that while there's abundant research on solar and wind energy, there might be a relative lack of research on harnessing tidal energy or integrating different types of renewable energy systems for more consistent power generation.
By identifying these research gaps, you will assisint in pinpointing areas where researchers can focus their efforts to potentially make novel contributions. Moreover, it can help funding agencies and institutions to direct resources and support towards these identified areas of opportunity, fostering advancements that might otherwise be overlooked.
INSTRUCTIONS:
1. Analyze each article returned by the search engine.
2. Identify the research gaps and opportunities for each article
3. Summarize the research gaps and opportunities in the field of {query} across ARTICLES. The research gap should BE GROUNDED on the articles returned by the search engine.
3. Identify an orthogonal field and generate keyword to get articles from that field that can solve the research gaps.
4. Identify a related field and generate keyword to get articles from that field that can solve the research gaps
5. Generate a JSON Response that STRICTLY follow the TYPESCRIPT SCHEMA of class Response below
6. Output MUST BE a JSON with the following fields in the SCHEMA.
SCHEMA:
class Response:
orthogonal_field: String
keyword_orthogonal_field: String
related_field: String
keyword_related_field: String
research_gaps: String
"""
prompt = PromptTemplate(template=template, input_variables=["query", "response"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
output = ""
try:
output = llm_chain.run({'query': query, 'response':response})
except Exception as e:
print (e)
We expect the response to be in JSON format. Sometimes, LLM may not follow the instructions to the dot and cause JSON parsing issues.
Prompt 2- Retrieve Research Gaps
Now that we have the research gaps from the JSON["research_gaps"], we can do a similar retrieval of top papers from field B to come up with new ideas. The output of research gaps from prompt 1 is fed to prompt 2.
llm_response = json.loads(output)
fieldB = input("Enter field B:")
orthogonal_field = fieldB
response = collect_results(search(fieldB,an,model,30),sents_from_path1, path1)
research_gap = llm_response["research_gaps"]
## cross pollination prompt
template = """ Take a deep breath.
You are a researcher in the FIELD1 of {query}. You are tasked with exploring ideas from another FIELD2 of {orthogonal_field} and identify actionable ideas and fix the research gaps.
RESEARCH GAP: You are given the problem of {research_gap} in the FIELD1.
OPPORTUNITIES : You are told the potential opportunities are {opportunies}
Search Engine returned top articles from FIELD2 {response}.
Task description:
You are expected to identify actionable ideas from FIELD2 that can fix the research gap of FIELD1. Ideas should be grounded on the articles returned by the search engine.
Example 1: The application of concepts from physics to biology led to the development of magnetic resonance imaging (MRI) which is now a fundamental tool in medical diagnostics.
Example 2: Concepts from the field of biology (e.g., evolutionary algorithms) have been applied to computational and engineering tasks to optimize solutions in a manner analogous to natural selection.
Follow the instructions below to identify actionable ideas from FIELD2 and fix the research gaps of FIELD1
INSTRUCTIONS:
1. Read every article of FIELD2 from Search engine response and identify actionable ideas that can fix the RESEARCH GAP of FIELD1
2. Summarize the actionable ideas in the field of FIELD2 that can fix the RESEARCH GAP of FIELD1
3. Generate a JSON Response that STRICTLY follow the TYPESCRIPT SCHEMA of class Response below
4. Output MUST BE a JSON ARRAY with the following fields in the SCHEMA.
5. Actionable idea should be a sentence or a paragraph that can fix the research gap of FIELD1
5. Reason should be a sentence or a paragraph that explains why the actionable idea can fix the research gap of FIELD1 using the ideas of FIELD2
6. GENERATE upto 10 ACTIONABLE IDEAS and atleast 3 ACTIONABLE IDEAS
SCHEMA:
Class Response:
actionable_ideas: String
reason: String
"""
prompt = PromptTemplate(template=template, input_variables=["query", "orthogonal_field", "research_gap", "opportunies", "response"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
try:
output = llm_chain.run({'query': query, 'orthogonal_field':orthogonal_field, 'research_gap':research_gap, 'opportunies':opportunies, 'response':response})
print (output)
except Exception as e:
print (e)We have followed the "Chain of Thought" prompting with the popular "Take a deep breath" technique.
It is also possible to let the LLM infer an adjacent or orthogonal field B instead of the researcher input field B.
Anecdotal Example:
FieldA: Urban planning and mobility
FieldB: Artificial Intelligence
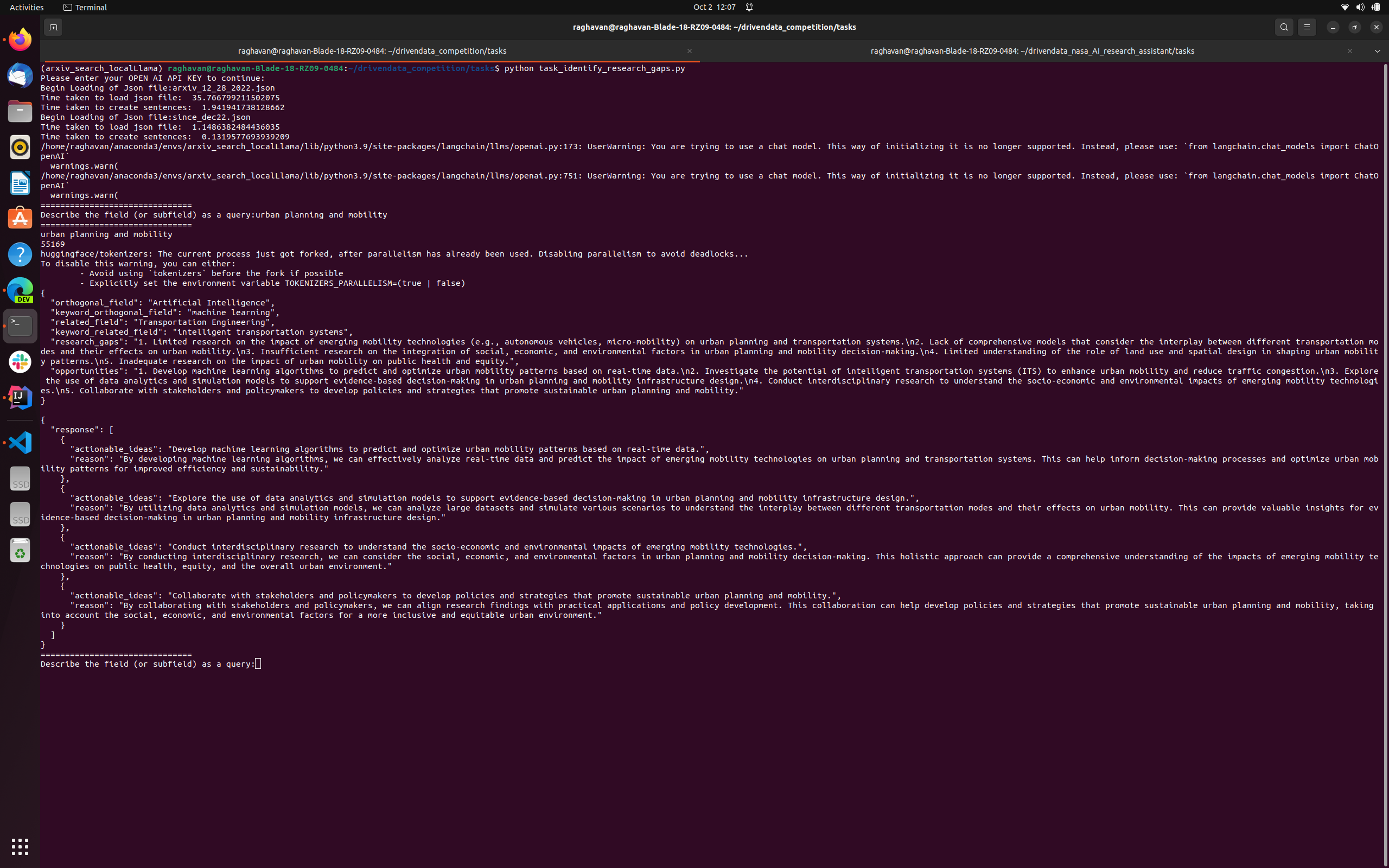
User Member inputs “urban planning and mobility” System reads the top articles from Arxiv and identifies the research gaps and opportunities also suggest an orthogonal field “Artificial Intelligence". It then mines articles from Artificial Intelligence and proposes actionable ideas and reasons to the researcher. This can serve as inspiration
1s actionable idea: "Develop ML algorithms to predict and optimize urban mobility patterns using real-time data". This might remind us of Waze rerouting drivers based on track
2nd actionable idea: "Explore the use of data analytics and simulation models to support evidence-based decision-making in urban planning and mobility infrastructure design"
While these ideas might be very easy for one to discern if they have an AI/ML background, they might be an eye opener and inspiration for urban planning policymakers with no such background.
Conclusion
With an RAG solution, researchers and policymakers can leverage large language models and connect the dots of unrelated fields, promoting effective cross-pollination. Hallucination is certainly a possibility when we force two unrelated fields for cross-pollination but it is now not a bug but a feature for promoting inspiration.
Footnote:
This article is based on multiple hackathon submissions at various venues including lablab.ai
Opinions expressed by DZone contributors are their own.
Comments