Do We Need Event Sourcing?
Is there an alternative to Event Sourcing? Could we achieve the same benefits but without using Event Sourcing? Let's see the answer!
Join the DZone community and get the full member experience.
Join For FreeBefore we start, I would definitely recommend getting familiar with the definition and benefits of Event Sourcing. Sara did an amazing job in explaining what Event Sourcing is in more detail and comparisons. Let's briefly touch upon some Event Sourcing aspects that are going to be important for this article.
In order to validate a business rule and/or make any decision in our software, we need to create a model representation of our domain. For the purposes of this article, I'm going to call this model the Decision Model. There are different ways of storing this model durably.
The first one is called state-stored, which means that we are storing only the current state of the Decision Model.
Another approach is to store the Decision Model as a series of events that describe facts that happened in our system; we say that this model is event-sourced. Now, when we need to load an event-sourced model from the storage, we must read all events related to it. The most suitable storage for events is the Event Store (another concept You should get familiar with).
Some frown on the fact that we need to load a lot of events in order to reconstruct the Decision Model. However, they see the benefits of Event Sourcing. This gave me an idea to explore whether we are able to achieve all the benefits of Event Sourcing while using a state-stored Decision Model.
In my opinion, the best way to approach this challenge is to zoom into the benefits of Event Sourcing and see whether we can obtain the same, but without Event Sourcing. Buckle up!
Benefit: Transactionality
Event Sourcing solves the transactionality challenge by using a single resource - the Event Store. In this scenario, the Decision Model is stored in the Event Store as a series of events, and it is also loaded as a series of events.
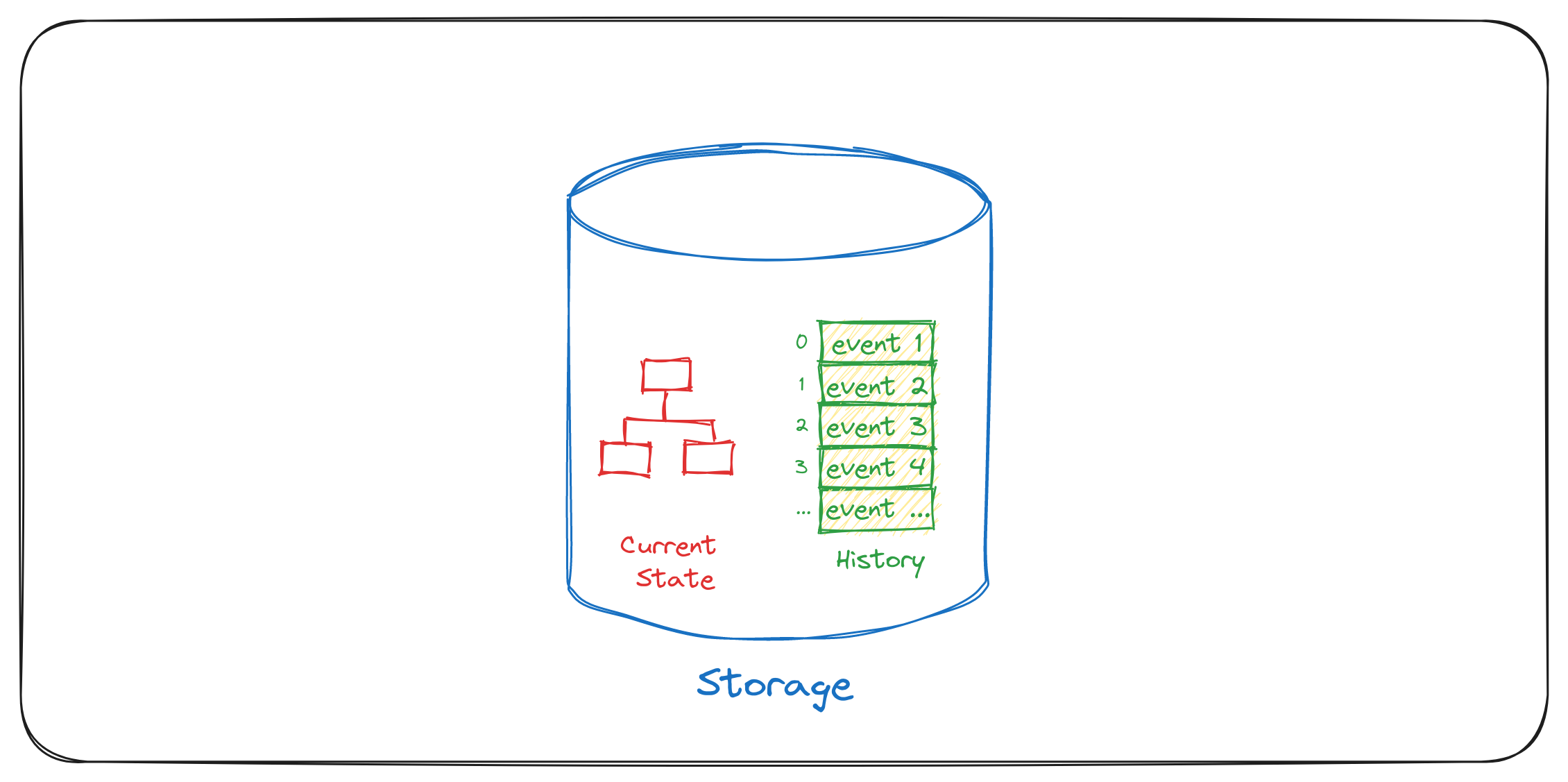
The same challenge could also be solved by having a single resource that can store the current state of the Decision Model and historical events in an ACID way. Here, any storage that guarantees transactionality between (1) storing the current state of the Decision Model and (2) storing events will serve the purpose (see Diagram 1).
Unfortunately, not a single Event Store (at least to my knowledge) is able to store events and a complex Decision Model. However, any Relational Database (RDBMS) could provide capabilities to support this use case.
Benefit: No Information Loss and Auditability
Alongside storing the current state of the Decision Model, we are storing events (in the same transaction) that led to this state. Obviously, no information is lost, we can audit our system, and we can learn from history.
But, not using the proper Event Store will lead us to trouble when the number of events increases. RDBMS doesn't perform well when the history table grows to several billions of rows. Adding a new event will slow down the update of the Decision Model, which will increase the latency and reduce the throughput of our system in the end.
Although I mentioned that RDBMS doesn't perform well with large history tables, certain RDBMS solutions can be optimized for this use case. We must keep in mind that this optimization is not trivial and affects how we are going to index this large table, how we are going to back up data, how we are going to use JOINS, etc. So, not impossible, but definitely not trivial. Anyway, let's move on and see whether we can solve this issue differently.
We can solve this issue by limiting the size of the history we store in RDBMS; we can move older events to more suitable storage, some form of Event Log, for example (see Diagram 2).

In this scenario, we are still persisting the current state of the Decision Model in the RDBMS Storage, but we are storing only recent events in the limited history table. Older events must be moved to the Event Log in order to protect us against Information Loss. For this, we are going to assign an asynchronous process (let's call it the Event Moving Process) to move events from the RDBMS to Event Log.
If we can guarantee that adding events to the Event Log is an idempotent operation, the job of the Event Moving Process is not so complicated (to some extent). However, this idempotency is not widely supported among Event Log implementations in the industry, which means that our Event Moving Process might not be so easy to implement. It would have to take care of Event Log idempotency.
The complexity of implementing this approach should not be underestimated!
Benefit: Event Replay
Having events durably stored gives us the opportunity to go back in time and replay (some of) them so we can recreate certain View Models or create new ones. This gives us quite a relief while we are developing View Models since any information we miss in the View Model can easily be added because the information is present in the form of stored events.
By solving the issue of non-performant writes (limiting the size of history and moving older events to the Event Log), we solved the issue of non-performant reads; the Event Log is much more suited for reading as well. And we need performant reads for Event Replays. The Event Log is eventually consistent, which is a fact we just have to accept.
Conclusion
In situations where the number of events in your system is not high, using the RDBMS only can fit the purpose. Keep in mind that event-driven systems typically tend to grow very quickly in the number of events. As soon as the history table grows to some extent, RDBMS will not fit the purpose anymore.
Evolving this architecture by introducing the Event Moving Process is a completely valid solution. But, You should really ask yourself: Is it really simpler than using Event Sourcing backed up by the Event Store?
Event Sourcing is much easier to reason about since we are dealing with a single resource; the Event Store. We don't need to take care of moving events or optimize it for large amounts of data; the Event Store is built for these purposes. There are techniques that can help us prevent loading too many events. The first one is to snapshot the Decision Model from time to time and load only the events between the last snapshot and now. The second one is using the Dynamic Consistency Boundary, which in combination with snapshotting, will reduce the number of loaded events even further.
Published at DZone with permission of Milan Savic. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments