Distributed Training on Multiple GPUs
The usefulness of GPUs versus CPUs for machine learning, why distributed training with multiple GPUs is optimal for larger datasets, and how to get started.
Join the DZone community and get the full member experience.
Join For FreeWhy and How to Use Multiple GPUs for Distributed Training
Data Scientists or Machine Learning enthusiasts training AI models at scale will inevitably reach a cap. When the datasets size increases, the processing time can increase from minutes to hours to days to weeks! Data scientists turn to the inclusion of multiple GPUs along with distributed training for machine learning models to accelerate and develop complete AI models in a fraction of the time.
We will discuss the usefulness of GPUs versus CPUs for machine learning, why distributed training with multiple GPUs is optimal for larger datasets, and how to get started training machine learning models using the best practices.
Why Are GPUs Good for Training Neural Networks?
The training phase is the most resource-intensive part of building a neural network or machine learning model. A neural network requires data inputs during the training phase. The model outputs a relevant prediction based on processed data in layers based on changes made between datasets. The first round of input data essentially forms a baseline for the machine learning model to understand; subsequent datasets calculate weights and parameters to train machine prediction accuracy.
For datasets that are simple or in a small number, waiting a couple of minutes is feasible. However, as the size or volume of input data increases, training times could reach hours, days, or even longer.
CPUs struggle to operate on a large amount of data, such as repetitive calculations on hundreds of thousands of floating-point numbers. Deep neural networks are composed of operations like matrix multiplications and vector additions.
One way to increase the speed of this process is to switch distributed training with multiple GPUs. GPUs for distributed training can move the process faster than CPUs based on the number of tensor cores allocated to the training phase.
GPUs or graphics processing units were originally designed to handle repetitive calculations in extrapolating and positioning hundreds of thousands of triangles for the graphics of video games. Coupled with a large memory bandwidth and innate ability to execute millions of calculations, GPUs are perfect for the rapid data flow needed for neural network training through hundreds of epochs (or model iterations), ideal for deep learning training.
What Is Distributed Training in Machine Learning?
Distributed training takes the workload of the training phase and distributes it across several processors. These mini-processors work in tandem to speed up the training process without degrading the quality of the machine learning model. As the data is divided and analyzed in parallel, each mini-processor trains a copy of the machine learning model on a distinct batch of training data.
Results are communicated across processors (either when the batch is completed entirely or as each processor finishes its batch). The next iteration or epoch starts again with a slightly newly trained model until it reaches the desired outcome.
There are two most common ways how to distribute training between mini-processors (in our case, GPUs): data parallelism and model parallelism.
Data Parallelism
Data Parallelism is a division of the data and allocating it to each GPU to evaluate using the same AI model. Once a forward pass is complete by all the GPUs, they output a gradient or the model’s learned parameters. Since there are multiple gradients, only 1 AI model to train, the gradients are compiled, averaged, and reduced to a single value to finally update the model parameters for the training of the next epoch. This can be done synchronously or asynchronously.

Synchronous Data Parallelism is where our groups of GPUs must wait until all other GPUs finish calculating gradients before averaging and reducing them to update the model parameters. Once parameters have been updated, then can the model proceed with the next epoch.
Asynchronous Data Parallelism is where GPUs train independently without having to perform a synchronized gradient calculation. Instead, gradients are communicated back to the parameter server when completed. Each GPU does not wait for the other GPU to finish calculating nor calculate gradient averaging, hence asynchronous. Asynchronous data parallelism requires a separate parameter server for the learning portion of the model, so it is a little more costly.
Calculating the gradients and averaging the training data after each step is the most compute-intensive. Since they are repetitive calculations, GPUs have been the choice for accelerating this step to reach faster results. Data parallelism is reasonably simple and economically efficient, however, there are times when the model is too large to fit on a single mini-processor.
Model Parallelism
In contrast to splitting the data, model parallelism splits the model (or workload to train the model) across the worker GPUs. Segmenting the model assigns specific tasks to a single worker or multiple workers to optimize GPU usage. Model parallelism can be thought of as an AI assembly line creating a multi-layer network that can work through large datasets unfeasible for data parallelism. Model parallelism takes an expert to determine how to partition the model but results in better usage and efficiency.
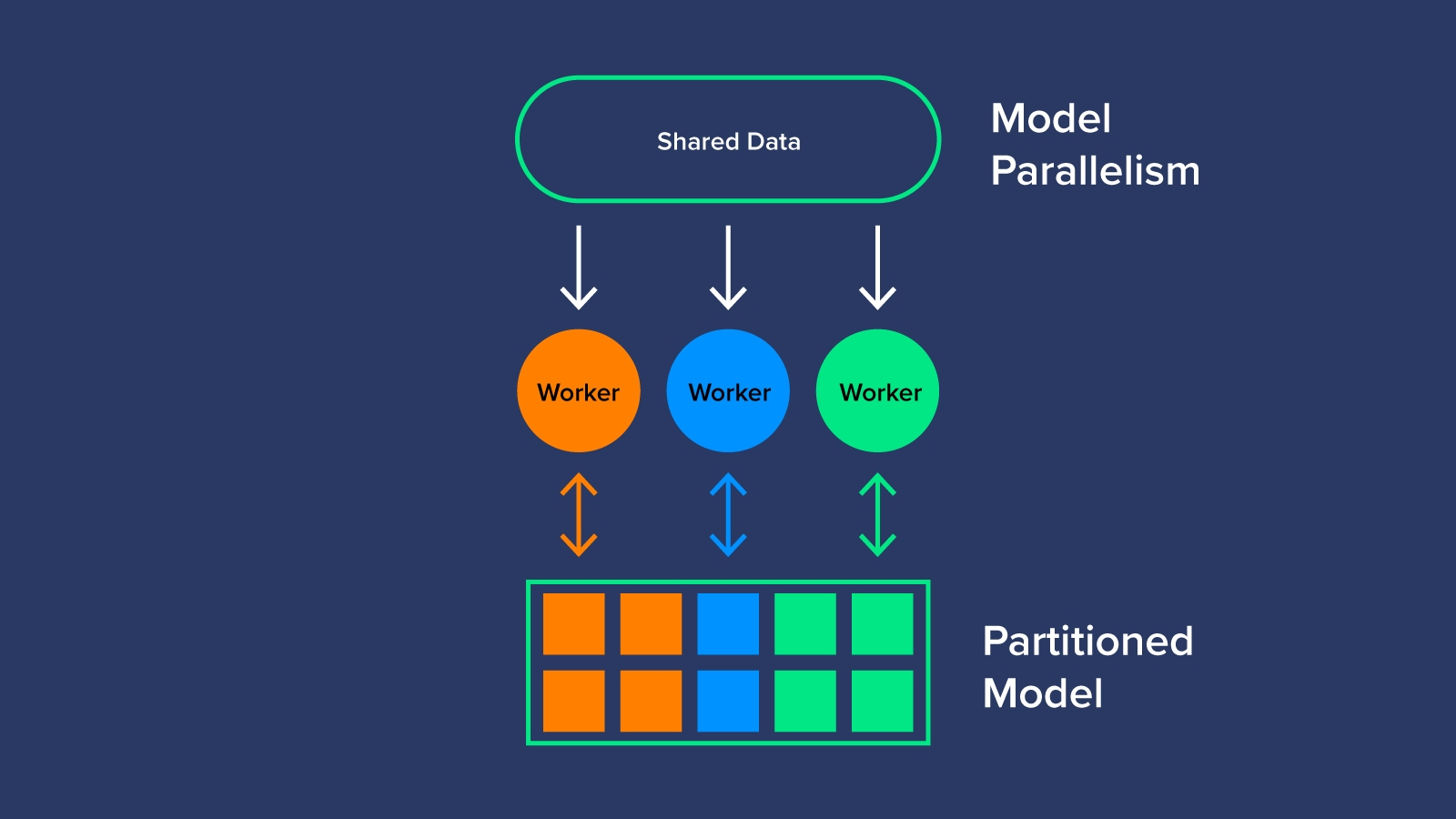
Is Multi-GPU Distributed Training Faster?
Buying multiple GPUs can be an expensive investment but is much faster than other options. CPUs are also expensive and cannot scale like GPUs. Training your machine learning models across multiple layers and multiple GPUs for distributed training increases productivity and efficiency during the training phase.
This means reduced time spent training your models, of course, but it also gives you the ability to produce (and reproduce) results faster and problem-solve before anything gets out of hand. In terms of producing results for your effort, it is the difference between weeks of training versus hours or minutes of training (depending on the number of GPUs in use).
The next problem you need to solve is how to start utilizing multiple GPUs for distributed training in your machine learning models.
How Do I Train With Multiple GPUs?
If you want to tackle distributed training with multiple GPUs, it will first be important to recognize whether you will need to use data parallelism or model parallelism. This decision will be based on the size and scope of your datasets.
Are you able to have each GPU run the entire model with the dataset? Or will it be more time-efficient to run different portions of the model across multiple GPUs with larger datasets? Generally, Data Parallelism is the standard option for distributed learning. Start with synchronous data parallelism before delving deeper into model parallelism or asynchronous data parallelism, where a separate dedicated parameter server is needed.
We can begin to link your GPUs together in your distributed training process.
- Break your data down based on your parallelism decision. For example, you might use the current data batch (the global batch) and divide it across eight sub-batches (local batches). If the global batch has 512 samples and you have eight GPUs, each of the eight local batches will include 64 samples.
- Each of the eight GPUs, or mini-processors, runs a local batch independently: forward pass, backward pass, output the weights' gradient, etc.
- Weight modifications from local gradients are efficiently blended across all eight mini-processors, so everything stays in sync, and the model has trained appropriately (when using synchronous data parallelism).
It is important to remember that one GPU for distributed training will need to host the collected data and results of the other GPUs during the training phase. You can run into the issue of one GPU running out of memory if you are not paying close attention.
Other than this, the benefits far outweigh the cost when considering distributed training with multiple GPUs! In the end, each GPU reduces time spent in the training phase, increases model efficiency, and yields more high-end results when you choose the correct data parallelization for your model.
Looking for More Information On Distributed Training and Other Machine Learning Topics?
Neural networks are highly complex pieces of technology, and the training phase alone can be daunting. By utilizing and learning more about how you can leverage additional hardware to create more effective models in less time, data science can change our world! GPUs for distributed training are well worth the initial investment when you can create more effective neural networks in weeks and months instead of months and years.
Published at DZone with permission of Kevin Vu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments