Distributed Systems: CAP Theorem
In this article, we will learn about the CAP theorem from a distributed system perspective using a simple database analogy.
Join the DZone community and get the full member experience.
Join For FreeWelcome to the Distributed Systems series. In this article, we will learn and understand what the CAP theorem is. CAP stands for consistency, availability, and partition tolerance. When we talk about the CAP theorem, we mostly talk about distributed systems. First, let’s understand what a distributed system Is. A distributed system is a system that is made up of multiple processes that run on a single machine or multiple machines. In this lecture, we will learn about the CAP theorem from a distributed system perspective using a simple database analogy.
What Is the CAP Theorem?
CAP theorem states that in a Distributed System, while network partition occurs, we can only choose either consistency or availability. This was coined by Eric Brewer to understand distributed systems. CAP stands for consistency, availability, and partition tolerance.
- Consistency: All clients will see the most recent data.
- Availability: The system is available and returns the data even if the node that contains the most recent data fails.
- Partition tolerance: The system should work despite network failures.
Now, we have understood the definition of the CAP theorem. Next, we will see how it plays a role in designing or choosing the distributed system such as database, cache, storage..etc.
Let’s first understand with a simple analogy. We are going to insert a record into the MySQL database. MySQL server runs on a single machine in a single process to handle read and write requests as specified in the below diagram.
The client wants to read and write records to the Relational MySQL DB. Since the database instance is running on a single machine, the system will be consistent, which means that the client will see the most recent write. The system will not be available if the node fails or if there is a network failure between the client and the database server.

As the number of users grows, our database should scale more reads and writes. There are multiple approaches available to scale the database, but we are going to discuss how the CAP theorem is applied when we replicate or partition the database. This is where a distributed system comes into practice. In order to scale more reads, we will replicate the data from mysql master to replica for each change that occurs in the master database. This approach helps to split the write and read requests to separate MySQL instances running on separate machines.
As specified in the diagram below, the MySQL instance is running on the master, which accepts write requests. All the writes are then replicated into the replica machines to handle the read requests. Compared to the previous single instance setup, we have separated the writes and reads into separate machines.
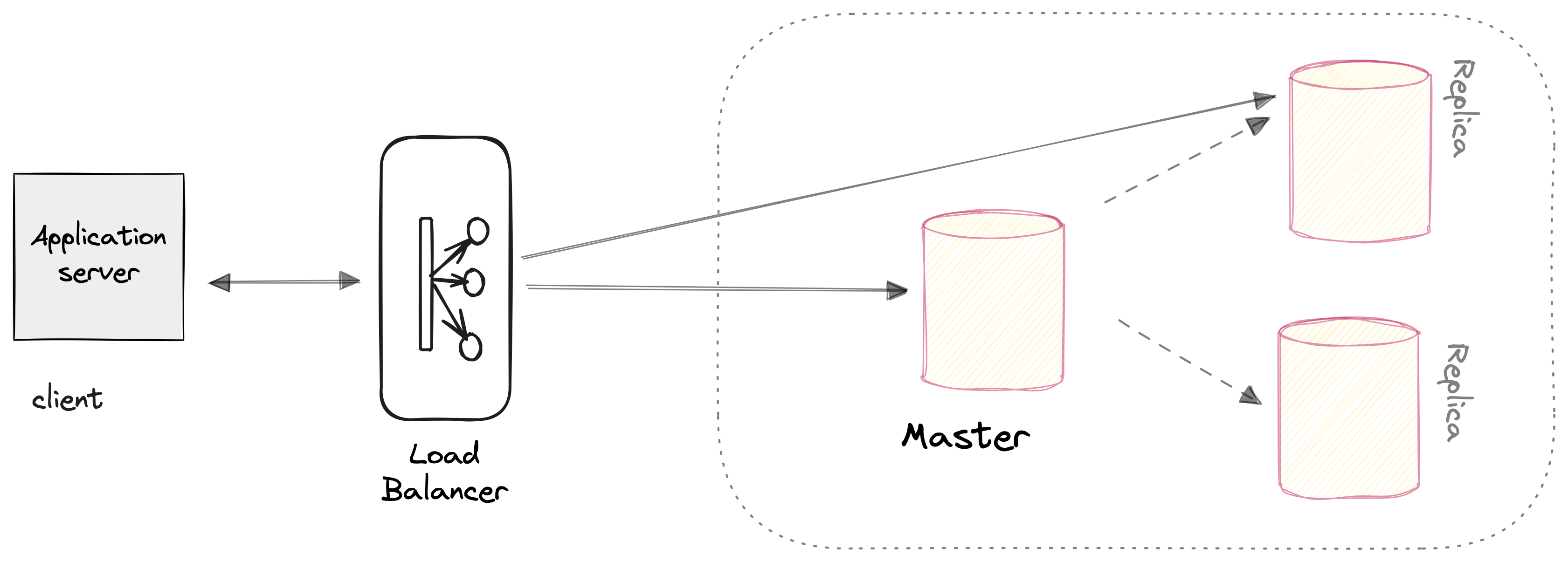
Now, we have distributed the MySQL database, which serves writes and reads from the master and replicates MySQL instances. Let’s look at how the CAP theorem is used to define this MySQL setup. Since our database setup becomes distributed, It is partition tolerant by default, which means when some nodes fail, the system should work to handle some client requests.
In the above example, we have not partitioned the database. Instead, we have only added replication to scale read requests. If the master node fails, replica instances are available to serve the read requests. This is a bit different from the previous single instance setup. The CAP theorem states in a distributed system, we can only choose either consistency or availability.
Choosing Consistency or Availability
Let’s say that our database system is required to be highly consistent. It should return the most recent data at any time when the client makes a request. Let’s consider a simple scenario of writing records to master DB.
If the replica machines are not available, then the master DB has two choices,
- It could return an error to the client. (Synchronous)
- It can write the data to the local machine and return it successfully. (Asynchronous)
If we go by the first choice, we return the error to the client. Our system will be highly consistent if a network partition occurs between master and replica instances. Since master and replica instances have the same data, our client will read the most recent write. Our system is now more of CP.
If we go by the second choice, our system will be highly available. It will return a successful response to our client and store the write to our local machine. Our writes will be replicated asynchronously at a later point in time. Meanwhile, if the client that writes to the master reads from a replica instance, it may or may not see the most recent data. This is due to a delay in asynchronous replication due to network partition or network failure.
Our system is now more of an AP since our client might not see the most recent data from the read replica due to a network partition between the master and replica.
In a distributed system, It’s impossible to achieve all three properties of the CAP. We can only choose any two of the CAPs, such as CA, CP, and AP. CA does not make any sense. In most cases, distributed systems are partition tolerant. So, we either go with CP or AP.
When we choose CP by opting for the first choice of the above example, It is not that our system will not be available. Our database will not be available to answer the write when the master instance can’t connect to the replica instance. In this scenario, we are favoring consistency over availability.
We can call distributed systems as CP or AP because these properties are favored during certain scenarios, such as network failure. Here, we can not sacrifice P(partition tolerance) since distributed systems are partition tolerant by default.
So, we can not build any distributed system without P. We have to favor either C (CP) or A(AP) to define our system.
Conclusion
In this article, we have seen the CAP theorem and how it is used to define the properties of distributed systems. When we build a distributed database, cache, storage, etc. We have the choice to decide how our system should behave. Whether it has to favor consistency or availability during certain scenarios, in this article, we have understood the properties of distributed MySQL read-replica and what we can expect from this during network failures.
Published at DZone with permission of Vetriselvan M. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments