How a Distributed File System in Go Reduced Memory Usage by 90%
Learn JuiceFS Enterprise Edition’s metadata engine design and optimization methods that reduced its metadata memory usage by 90%.
Join the DZone community and get the full member experience.
Join For FreeJuiceFS, written in Go, can manage tens of billions of files in a single namespace. Its metadata engine uses an all-in-memory approach and achieves remarkable memory optimization, handling 300 million files with 30 GiB of memory and 100 microseconds response time. Techniques like memory pools, manual memory management, directory compression, and compact file formats reduced metadata memory usage by 90%.
JuiceFS Enterprise Edition, a cloud-native distributed file system written in Go, can manage tens of billions of files in a single namespace. After years of iteration, it can manage about 300 million files with a single metadata service process using 30 GiB of memory while maintaining the average processing time of metadata requests at 100 microseconds. In production, 10 metadata nodes, each with 512 GB of memory, collectively manage over 20 billion files.
For ultimate performance, our metadata engine uses an all-in-memory approach and undergoes continuous optimization. Managing the same number of files requires only 27% of the memory of HDFS NameNode or 3.7% of the CephFS Metadata Server (MDS). This extremely high memory efficiency means that with the same hardware resources, JuiceFS can handle more files and more complex operations, thus achieving higher system performance.
In this post, we’ll delve into JuiceFS’ architecture, our metadata engine design, and optimization methods that reduced our average memory usage for metadata to 100 bytes. Our goal is to provide JuiceFS users with deeper insights and confidence in handling extreme scenarios. We also hope this post will serve as a valuable reference for designing large-scale systems.
JuiceFS Architecture
JuiceFS consists of three major components:
- Client: This is the access layer that interacts with the application. JuiceFS supports multiple protocols, including POSIX, Java SDK, Kubernetes CSI Driver, and S3 Gateway.
- Metadata engine: It maintains the directory tree structure of the file system and the properties of individual files.
- Data storage: It stores the actual content of regular files, typically handled by object storage services like Amazon S3.
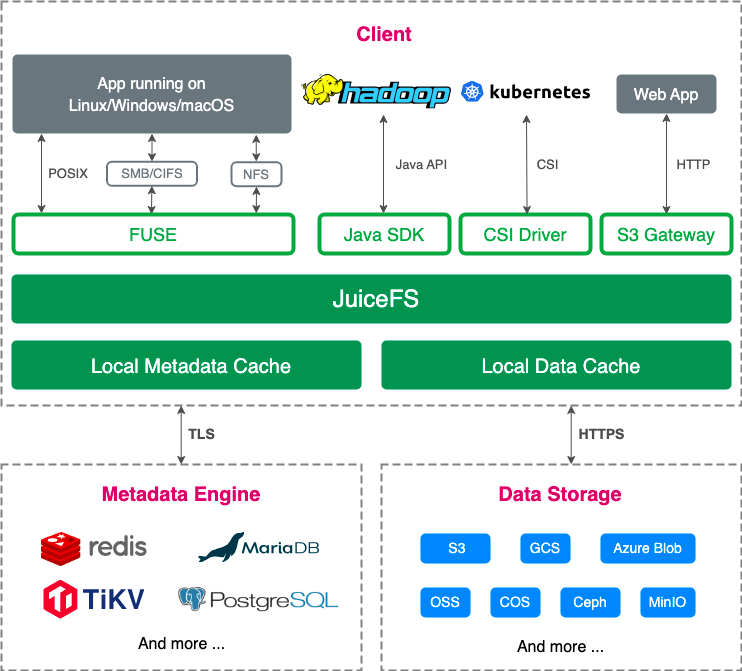
Currently, JuiceFS offers two editions: Community Edition and Enterprise Edition. While their architectures share similarities, the key distinction lies in the implementation of the metadata engine:
- The Community Edition's metadata engine uses existing database services, such as Redis, PostgreSQL, and TiKV.
- The Enterprise Edition features an in-house developed metadata engine. This proprietary engine not only delivers enhanced performance with reduced resource consumption but also provides additional support for enterprise-level requirements.
The subsequent sections will explore our considerations and methodologies in developing the exclusive metadata engine for JuiceFS Enterprise Edition.
Metadata Engine Design
Choosing Go as the Development Language
The development of underlying system software is usually based on C or C++, while JuiceFS chose Go as the development language. This is because Go has the following advantages:
- High development efficiency: Go syntax is more concise compared to C, with stronger expressive capabilities. Additionally, Go comes with built-in memory management functionality and powerful toolchains like pprof.
- Excellent program execution performance: Go itself is a compiled language, and programs written in Go generally do not lag behind C programs in the vast majority of cases.
- Better program portability: Go has better support for static compilation, making it easier for programs to run directly on different operating systems.
- Support for multi-language SDKs: With the help of the native cgo tool, Go code can also be compiled into shared library files (.so files), facilitating loading by other languages.
While Go brings convenience, it hides some low-level details. This may affect the program's efficiency in using hardware resources to a certain extent, especially the management of memory by the garbage collector (GC). Therefore, targeted optimizations are needed at critical performance points.
Performance Boost Strategies: All-In-Memory, Lock-Free Services
To improve performance, we need to understand the core responsibilities of the metadata engine in a distributed file system. Typically, it’s mainly responsible for two important tasks:
- Managing metadata for a massive number of files
- Quickly processing metadata requests
All-In-Memory Mode for Managing Massive Files’ Metadata
To accomplish this task, there are two common design approaches:
- Loading all file metadata into memory, such as HDFS NameNode. This can provide excellent performance but inevitably requires a large amount of memory resources.
- Caching only part of the metadata in memory, such as CephFS MDS. When the requested metadata is not in the cache, the MDS holds the request temporarily, retrieves the corresponding content from the disk (metadata pool) over the network, parses it, and then retries the operation. This can easily lead to latency spikes, affecting the user experience. Therefore, in practice, to meet the low-latency access needs of the application, the MDS memory limit is increased as much as possible to cache more files, even all files.
JuiceFS Enterprise Edition pursues ultimate performance and thus adopts the first all-in-memory approach, continuously optimizing to reduce the memory usage of file metadata. All-in-memory mode typically uses real-time transaction logs to persist data for reliability. JuiceFS also uses the Raft consensus algorithm to implement metadata multi-server replication and automatic failover.
Lock-Free Approach for Quick Metadata Processing
The key performance metric of the metadata engine is the number of requests it can process per second. Typically, metadata requests need to ensure transactions and involve multiple data structures. Complex locking mechanisms are required during concurrent multithreading to ensure data consistency and security. When transactions conflict frequently, multithreading does not effectively improve throughput; instead, it may increase latency due to too many lock operations. This is especially evident in high-concurrency scenarios.
JuiceFS adopted a different approach, similar to Redis' lock-free mode. In this mode, all core data structure operations are executed in a single thread. This approach has the following advantages:
- The single-threaded approach ensures the atomicity of each operation (avoiding operations being interrupted by other threads) and reduces thread context switching and resource contention. Thereby it improves the overall efficiency of the system.
- At the same time, it significantly reduces system complexity and enhances stability and maintainability.
- Thanks to the all-in-memory metadata storage mode, requests can be efficiently processed, and the CPU is not easily bottlenecked.
Multi-Partition Horizontal Scaling
The memory available to a single metadata service process has its limits, and efficiency gradually declines as memory usage per process increases. JuiceFS achieves horizontal scaling by aggregating metadata distributed across multiple nodes in virtual partitions, supporting larger data scales and higher performance demands.
Specifically, each partition is responsible for a portion of the file system's subtree, and clients coordinate and manage files across partitions to assemble the files into a single namespace. These files in the partitions can dynamically migrate as needed. For example, a cluster managing over 20 billion files may use 10 metadata nodes with 512 GB of memory each, deployed across 80 partitions. Typically, it's recommended to limit the memory of a single metadata service process to 40 GiB and manage more files through multi-partition horizontal scaling.
File system access often has a strong locality, with files moving within the same directory or adjacent directories. Therefore, JuiceFS implemented a dynamic subtree splitting mechanism that maintains larger subtrees, minimizing most metadata operations to occur within a single partition. This approach significantly reduced the use of distributed transactions, ensuring that even after extensive scaling, the cluster maintains metadata response latencies similar to those of a single partition.
How To Reduce Memory Usage
As data volume increases, the memory requirements for metadata services also rise. This impacts system performance and escalates hardware costs. Thus, reducing metadata memory usage is critical for maintaining system stability and cost control in scenarios involving massive files.
To achieve this goal, we've explored and implemented extensive optimizations in memory allocation and usage. Below, we'll discuss some measures that have proven effective through years of iteration and optimization.
Using Memory Pools To Reduce Allocation
Using memory pools to reduce allocation is a common optimization technique in Go programs, primarily using the sync.Pool structure from the standard library. The principle is not discarding data structures after use but returning them to a pool. When the same type of data structure is needed again, it can be retrieved directly from the pool without allocation. This approach effectively reduces the frequency of memory allocation and deallocation, thereby enhancing performance.
For example:
pool := sync.Pool{
New: func() interface{} {
buf := make([]byte, 1<<17)
return &buf
},
}
buf := pool.Get().(*[]byte)
// do some work
pool.Put(buf)During initialization, typically, we need to define a New function to create a new structure. When we use the structure, we use the Get method to obtain the object and convert it to the corresponding type. After we finish using it, we use the Put method to return the structure to the pool. It's worth noting that after being returned, the structure in the pool has only a weak reference and may be garbage-collected at any time.
The structure in the example above is a segment of pre-allocated memory slices, essentially creating a simple memory pool. When combined with the finer management techniques discussed in the next section, it enables efficient memory utilization in programs.
Manual Management of Small Memory Allocations
In the JuiceFS metadata engine, the most critical aspect is maintaining the directory tree structure, which roughly looks like this:
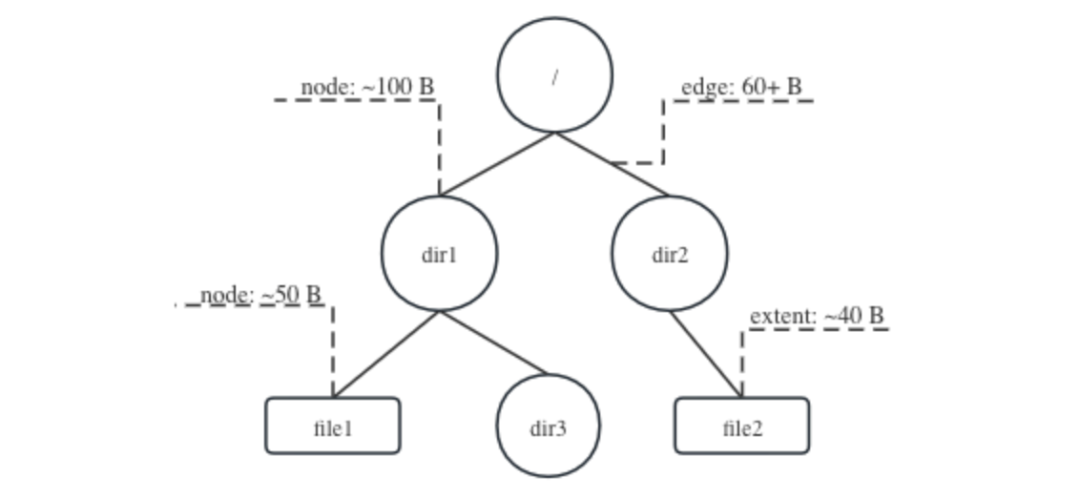
In this structure:
- A node records attributes of each file or directory, typically occupying 50 to 100 bytes.
- An edge describes the relationship between parent and child nodes, generally occupying 60 to 70 bytes.
- An extent records the location of data, typically occupying about 40 bytes.
These structures are small but numerous. Go's GC does not support generations. This means if they are all managed by the GC, it needs to scan them all during each memory scan and mark all referenced objects. This process can be slow, preventing timely memory reclamation and consuming excessive CPU resources.
To efficiently manage these massive small objects, we used the unsafe pointer (including uintptr) to bypass Go's GC for manual memory allocation and management. In implementation, the metadata engine requests large blocks of memory from the system and then splits them into small blocks of the same size. When saving pointers to these manually allocated memory blocks, we preferred using unsafe.Pointer or even uintptr types, relieving the GC from scanning these pointers and significantly reducing its workload during memory reclamation.
We designed a metadata memory pool named Arena, containing multiple buckets to isolate structures of varying sizes. Each bucket holds large memory blocks, such as 32 KiB or 128 KiB. When metadata structures are needed, the Arena interface locates the corresponding bucket and allocates a small segment from it. After use, it informs Arena to return it to the memory pool. Arena’s design diagram is as follows: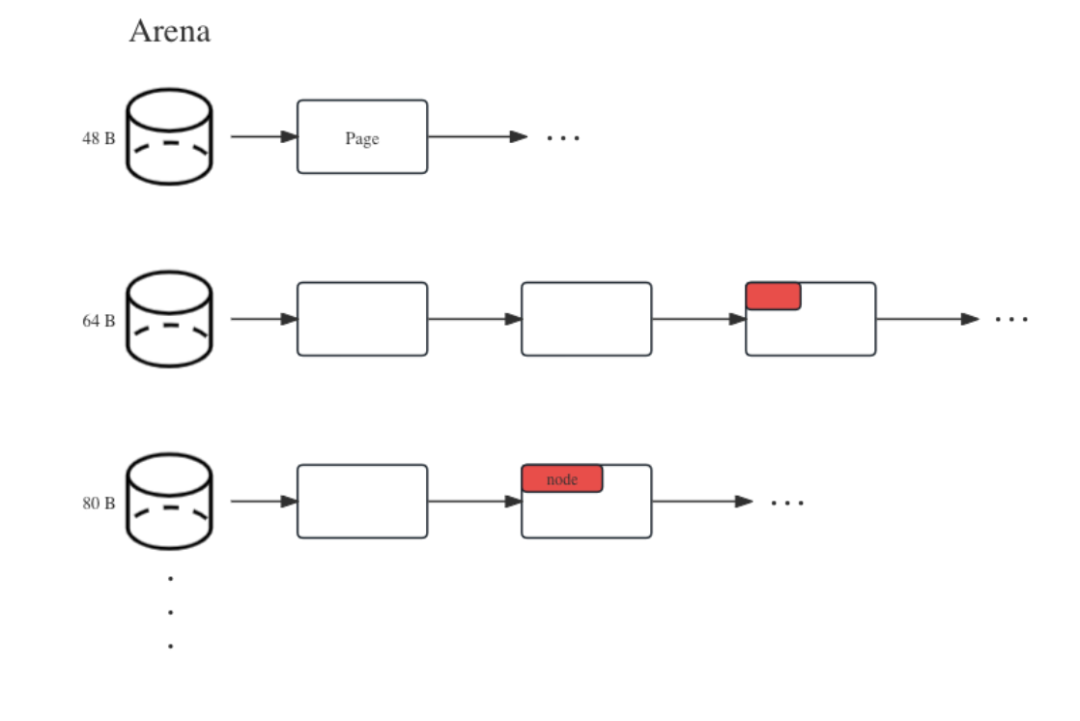
The management details are complicated. If you’re interested, you can learn more about the implementation principles of memory allocators such as tcmalloc and jemalloc. Our design ideas are similar to them. Below is a block of key code in Arena:
// Resident memory blocks
var slabs = make(map[uintptr][]byte)
p := pagePool.Get().(*[]byte) // 128 KiB
ptr := unsafe.Pointer(&(*p)[0])
slabs[uintptr(ptr)] = *pHere, slabs is a global map that records all allocated memory blocks in Arena. It allows the GC to know that these large memory blocks are in use. The following code creates structures:
func (a *arena) Alloc(size int) unsafe.Pointer {...}
size := nodeSizes[type]
n := (*node)(nodeArena.Alloc(size))
// var nodeMap map[uint32, uintptr]
nodeMap[n.id] = uintptr(unsafe.Pointer(n)))The Alloc function of Arena requests memory of a specific size and returns an unsafe.Pointer pointer. When we create a node, we first determine the size required by its type and then convert the obtained pointer to the desired structure type. If necessary, we convert this unsafe.Pointer to uintptr and store it in nodeMap. This map is a large mapping used to quickly find the corresponding structure based on the node ID.
From the perspective of the GC, it appears that the program has requested many 128 KiB memory blocks that are constantly in use, but it doesn't need to worry about the content inside. Additionally, although nodeMap contains hundreds of millions or even billions of elements, all its key-value pairs are of numeric types, so the GC doesn't need to scan each key-value pair. This design is friendly to the GC, and even with hundreds of gigabytes of memory, it can easily complete the scan.
Compressing Idle Directories
As mentioned above, file system access has a strong locality, with applications often accessing only a few specific directories frequently, leaving other parts idle. Based on this observation, we compressed inactive directory metadata to reduce memory usage. The process is as follows:
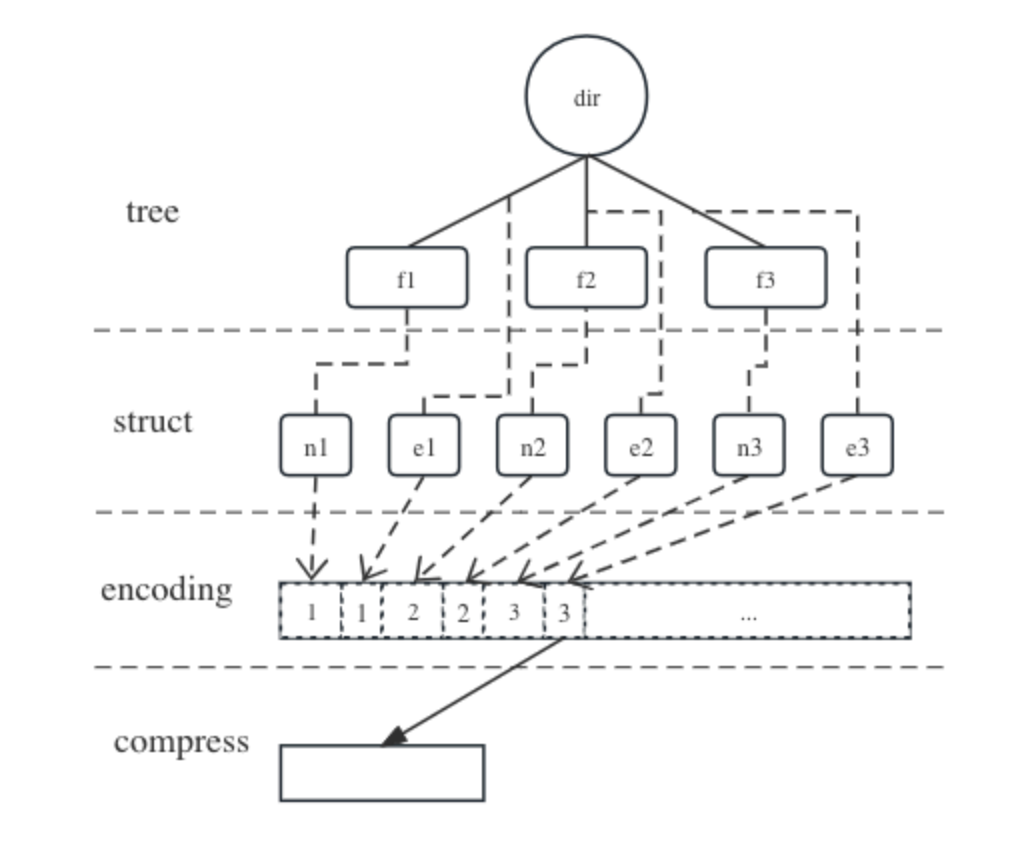
When the dir directory is idle, its metadata, along with all its immediate child items, can be compactly serialized into a contiguous memory buffer according to a predefined format. Then, this buffer can be compressed to a smaller size.
Typically, serializing multiple structures together can save nearly half of the memory, and compression can further reduce memory usage by approximately one-half to two-thirds. Thus, this method significantly lowers the average memory usage of individual file metadata. However, the serialization and compression processes consume certain CPU resources and may increase request latency. To balance efficiency, we monitor CPU status internally and trigger this process only when the CPU is idle, limiting the number of files processed to 1,000 per operation to ensure quick completion.
Designing More Compact Formats for Small Files
To support efficient random read and write operations, JuiceFS indexes metadata of regular files into three levels: fnodes, chunks, and slices. Chunks are an array, and slices are stored in a hash table. Initially, each file required the allocation of these three memory blocks. However, we found this method inefficient for most small files because they typically have only one chunk, which in turn has only one slice, and the slice's length is the same as the file's length.
Therefore, we introduced a more compact and efficient memory format for such small files. In the new format, we only need to record the slice ID and derive the slice length from the file's length without storing the slice itself. Additionally, we adjusted the structure of fnodes. Previously, fnodes stored a pointer to the chunks array, which contained only an 8-byte slice ID. Now, we store this ID in the pointer variable. This usage is similar to a union structure in the C language, storing different types of data in the same memory location based on the situation. After these adjustments, each small file only has one fnode object without requiring additional chunk lists and slice information.
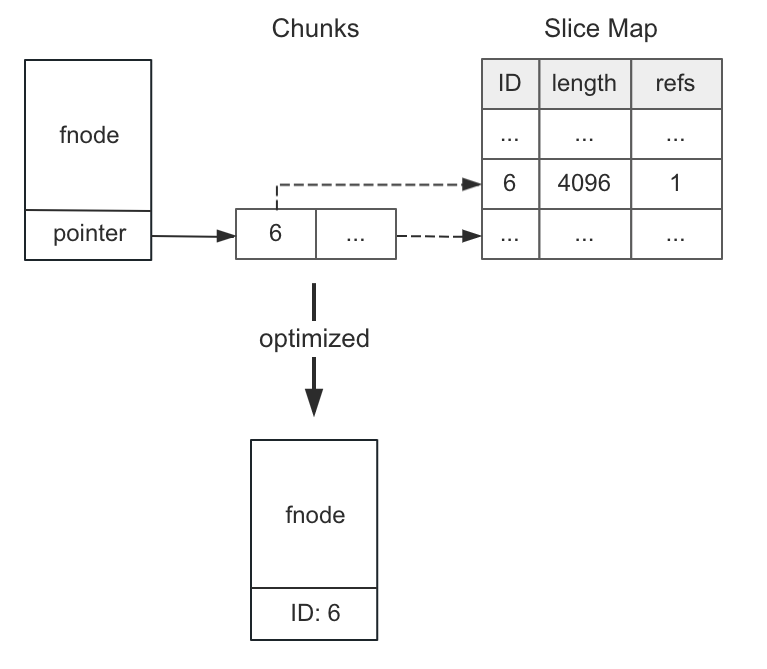
The optimized format saved about 40 bytes of memory per small file. Moreover, it reduced memory allocation and indexing operations, resulting in faster access.
Overall Optimization Effects
The figure below summarizes our optimization results:
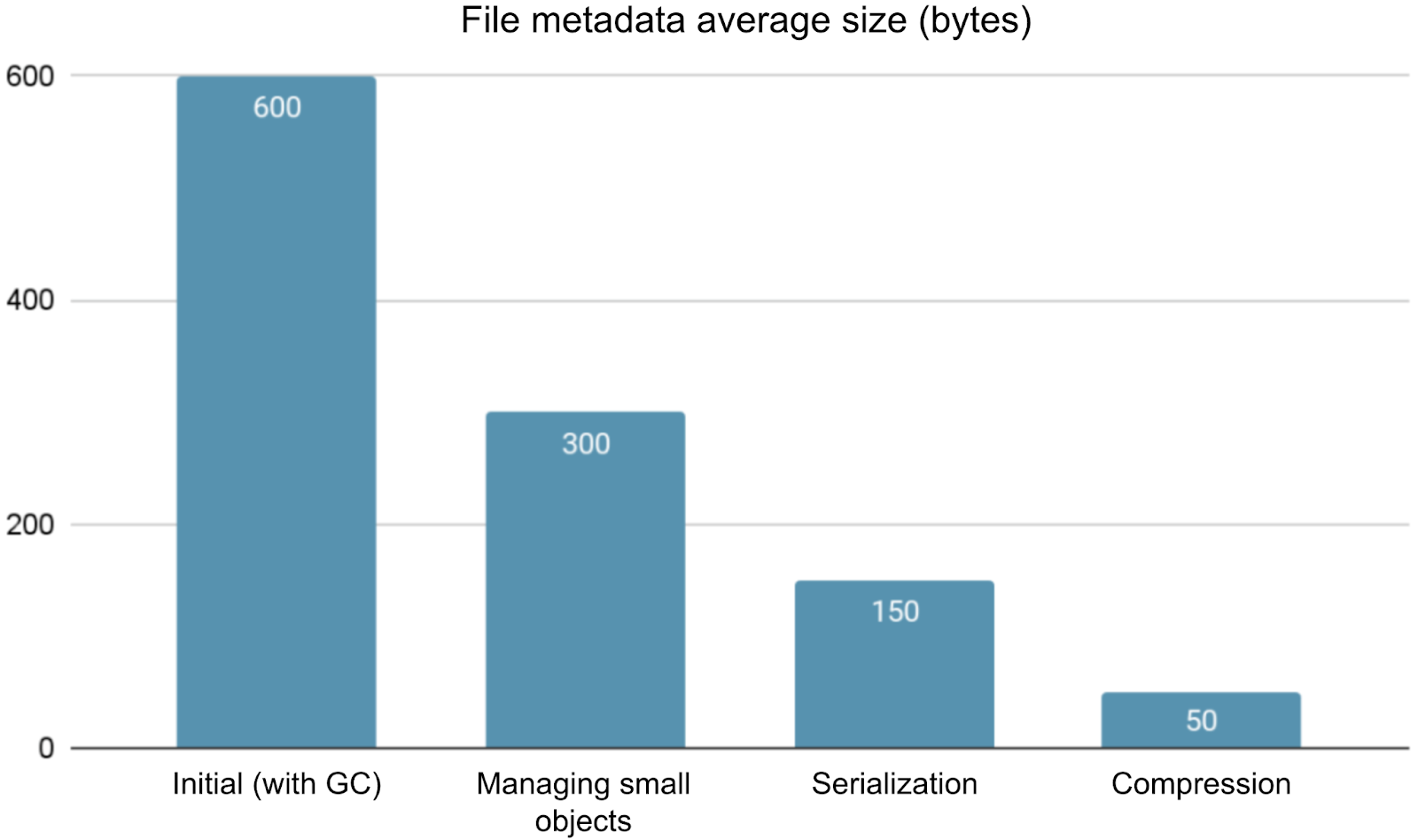
In the figure, the average metadata size of files significantly decreased:
- Initially, the average metadata size per file was nearly 600 bytes.
- Through manual memory management, this number dropped to about 300 bytes, substantially reducing GC overhead.
- Subsequently, by serializing idle directories, it was further reduced to about 150 bytes.
- Finally, through memory compression techniques, the average size decreased to about 50 bytes.
However, the metadata service also does tasks such as status monitoring, session management, and handling network transfers. This may increase memory usage beyond this core value. Therefore, we generally estimate hardware resources based on 100 bytes per file.
The single-file memory usage of common distributed file systems is as follows:
- HDFS: 370 bytes (source: online cluster monitoring — 52 GB memory, 140 million files)
- CephFS: 2,700 bytes (source: Nautilus version cluster monitoring — 32 GB memory, 12 million files)
- Alluxio (heap mode): 2,100 bytes (source: Alluxio documentation — 64 GB memory, 30 million files)
- JuiceFS Community Edition Redis engine: 430 bytes (source: Redis Best Practices)
- JuiceFS Enterprise Edition: 100 bytes (source: online cluster monitoring — 30 GB memory, 300 million files)
JuiceFS demonstrates outstanding performance in metadata memory usage, accounting for only 27% of HDFS NameNode and 3.7% of CephFS MDS. This not only signifies higher memory efficiency but also means that JuiceFS, with the same hardware resources, can handle more files and more complex operations, thereby improving overall system performance.
Conclusion
One of the core components of a file system lies in its metadata management. When building a distributed file system capable of handling tens of billions of files, this design task becomes particularly complex.
This article introduced JuiceFS’ key decisions in designing its metadata engine and elaborated on four memory optimization techniques: memory pools, manual management of small memory blocks, compression of idle directories, and optimization of small file formats. These measures are the results of our continuous exploration, experimentation, and iteration, ultimately reducing JuiceFS’ average memory usage for file metadata to 100 bytes. This makes JuiceFS more adaptable to a wider range of extreme application scenarios.
Published at DZone with permission of Sandy Xu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments