Developing With Dragonfly: Solve Caching Problems
Investigate three frequently encountered caching challenges and delve into the most effective best practices to successfully mitigate them.
Join the DZone community and get the full member experience.
Join For FreeIn our previous blog post within the Developing with Dragonfly series, we delved into one of the simplest caching patterns known as Cache-Aside. It's a straightforward approach to caching that's relatively easy to implement. However, as we'll explore in this blog post, it can also uncover some common issues that may have significant consequences for your services. We'll shine a light on the three major problems in cache management and share best practices to steer clear of them.
It's important to note that these caching problems are not unique to Dragonfly. Even with Dragonfly's exceptional efficiency and performance, these challenges persist across various caching solutions. Dragonfly is protocol and command compatible with Redis, which means it's readily available for integration into your backend services at no development cost. By addressing these caching problems and harnessing Dragonfly's advantages, we aim to help you smoothly transition to Dragonfly and achieve greater success in your caching infrastructure.
1. Cache Penetration
Firstly, let's take a look at cache penetration. A cache miss occurs when the caching layer fails to find the requested data and forwards the request directly to the primary database. This scenario is quite common in caching systems. However, cache penetration occurs when there is a cache miss, but the primary database also lacks the required data.
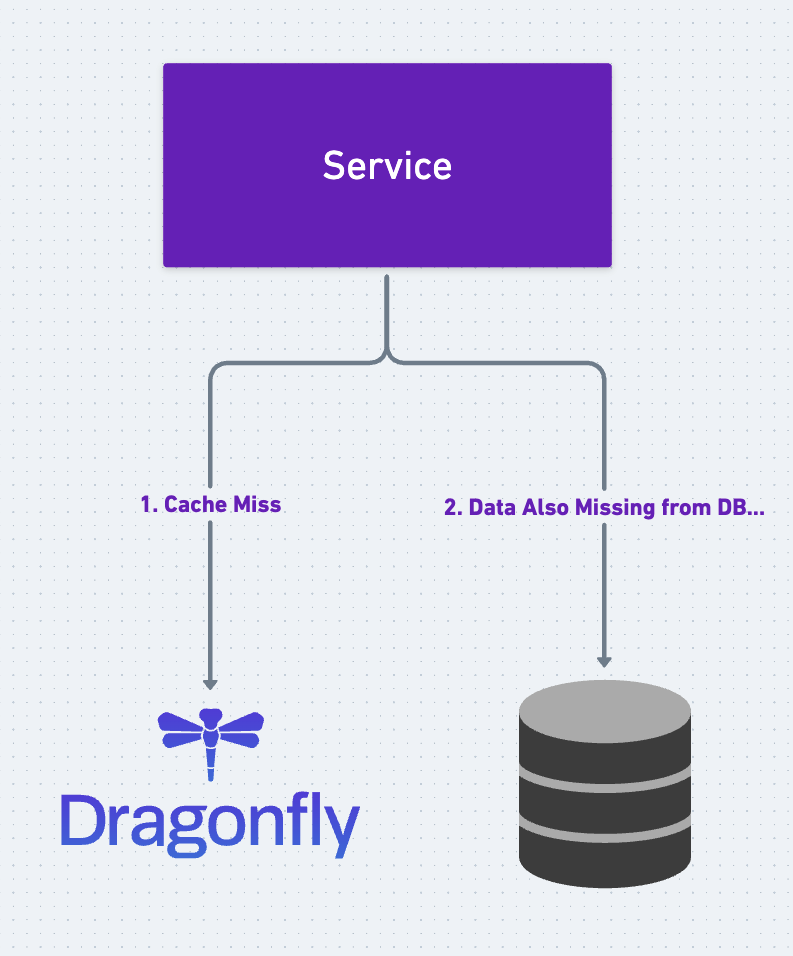
Cache penetration effectively renders the caching layer ineffective, and the primary database becomes the point of contention. If a hacker were to flood the system with numerous requests containing random keys, all of which result in cache misses and are subsequently absent from the primary database, it could lead to a scenario where the primary database becomes overwhelmed, potentially causing it to fail. Now, let's delve into two widely used techniques to mitigate the issue of cache penetration.
Caching Empty Results
One effective technique to address cache penetration is to cache empty results. When the primary database doesn't contain the requested data, as the caching layer, we can still store the empty result (i.e., null, nil) in Dragonfly. This approach is relatively straightforward to implement, but it does come with a significant drawback. Although an empty value occupies very little memory space, if the service experiences a high volume of requests with non-existing keys, it could lead to wasteful utilization of valuable in-memory storage.
To manage this issue efficiently, it's crucial to evict empty results from the caching layer. Here are two methods for doing so:
- Expire the empty result after a certain, normally short, period of time. This is a simple and effective way to evict the empty result, which is also easy to implement.
- Employ a strong and smart eviction policy to evict the empty results. This approach involves making eviction decisions based on various factors, such as cache usage patterns, access frequency, or memory constraints. We will discuss this approach in more detail in the Dragonfly LFRU Eviction Policy section below.
Bloom Filter
Another valuable technique to combat cache penetration is the use of a Bloom Filter. A Bloom Filter is a probabilistic data structure employed to determine whether an element belongs to a specific set. It stands out for its space efficiency, often requiring much less memory than a traditional hash table, albeit with the trade-off of potentially allowing false positives. In the context of cache penetration, a Bloom Filter can serve as a protective mechanism, implementing either an allow-list or a block-list to filter requests before they reach the primary database.
As of the current version of Dragonfly (v1.9.0), the Bloom Filter functionality is not yet natively supported. However, the Dragonfly community is highly active, constantly evolving the project to meet users' needs. If features like Bloom Filter are essential for your use cases, we encourage you to engage with the community. You can do so by opening an issue or connecting with the Dragonfly community via Twitter or Discord, as indicated at the bottom of this page.
As a side note, it's worth mentioning that the Dragonfly community has a track record of responsiveness to user feedback and enhancement requests. For instance, they recently addressed a usability concern by transitioning from glob-style backup scheduling to a more universally accepted cron-style format. This change was proposed and implemented by community members, showcasing the collaborative spirit and responsiveness of the Dragonfly team and its remarkable community. You can read more about the cron-based backup scheduling in our documentation and witness the positive synergy between Dragonfly team members and the enthusiastic community here.
2. Cache Breakdown
Next, let's explore the cache breakdown problem. A cache breakdown occurs when a cached key containing a piece of hot data either expires or gets evicted from the cache unexpectedly. When this happens, multiple requests simultaneously query the same data, overwhelming the database due to the high concurrency.
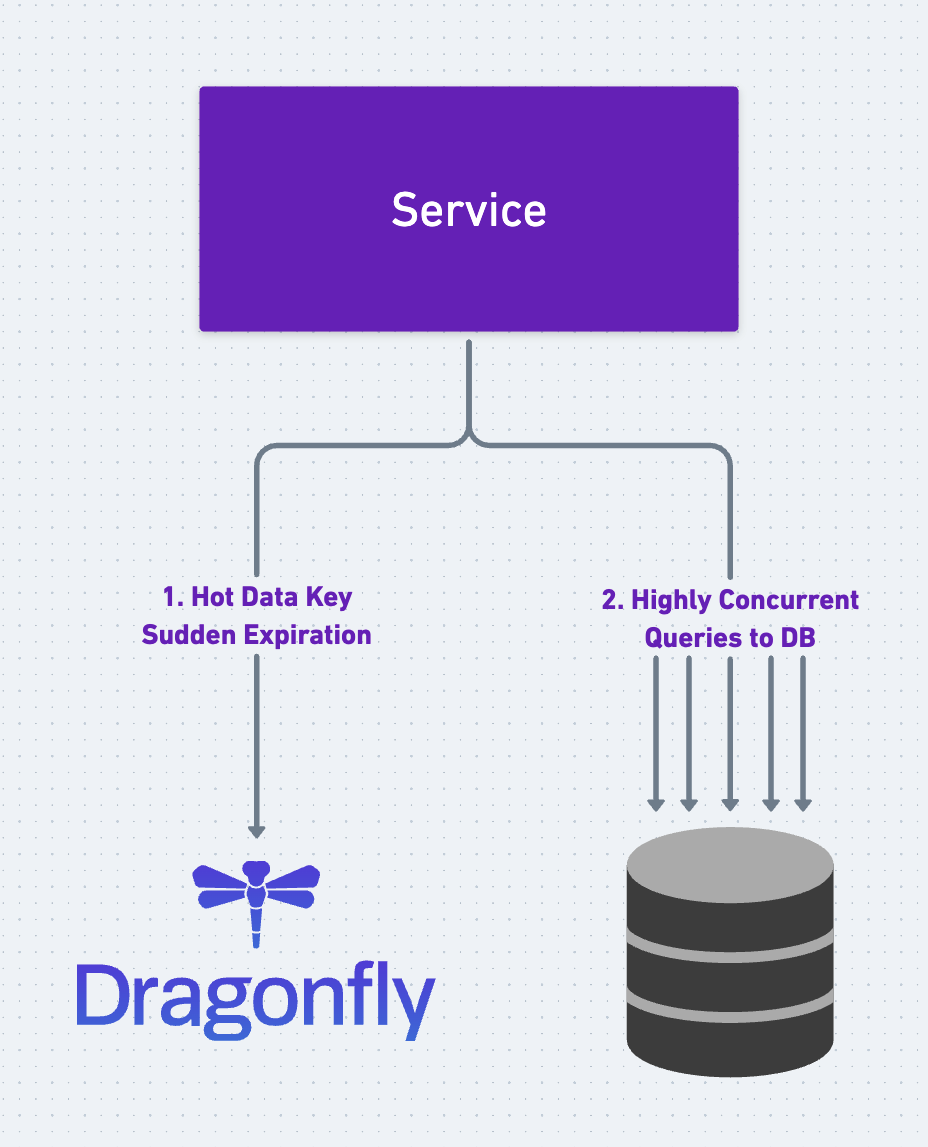
The Cache-Aside strategy is not effective in this situation either. Since Cache-Aside loads data into Dragonfly passively, during periods of intense activity (imagine a celebrity's blog post suddenly disappearing from the cache), multiple highly concurrent queries can still reach and exert pressure on the database. Let's dive into techniques to mitigate the cache breakdown issue.
Refresh-Ahead Caching Strategy
The Refresh-Ahead caching strategy presents a practical solution to mitigate the cache breakdown problem effectively. Refresh-Ahead is a strategy that takes a proactive approach by refreshing the cache before the cached key expires, keeping data hot until it's no longer in high demand. Here are the common steps to implement the Refresh-Ahead strategy:
- Start by choosing a refresh-ahead factor, which determines the time before the cached key expires when the cache should be refreshed.
- For example, if your cached data has a lifetime of 100 seconds and you choose a refresh-ahead factor of 50%:
- If the data is queried before the 50th second, the cached data will be returned as usual.
- If the data is queried after the 50th second, the cached data will still be returned, but a background worker will trigger the data refresh.
- It's important to ensure that only one background worker is responsible for refreshing the data to avoid redundant reads to the database.
This caching strategy strikes a balance between keeping the cache fresh and minimizing the load on both the cache and the primary database. As a result, it's an effective means of ensuring reliable and responsive services even during high-traffic periods.
3. Cache Avalanche
Finally, let's examine the cache avalanche problem. A cache avalanche is a situation that arises when a significant number of cached keys cannot be located in the caching layer simultaneously, leading to a sudden surge of queries overwhelming the primary database.
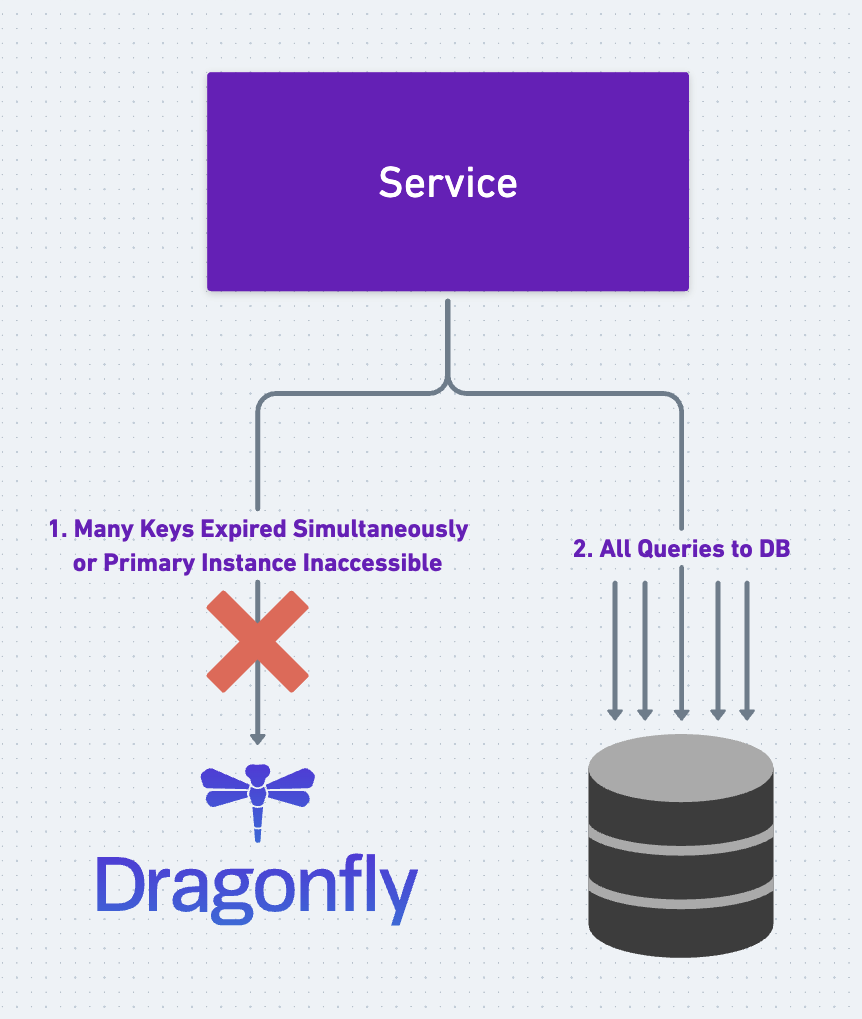
There are two primary reasons behind cache avalanches:
- Many cached keys expire simultaneously.
- The caching layer experiences a crash or becomes inaccessible for a period of time.
Let's also explore best practices to mitigate the cache avalanche problem.
Expiration Time Jitter
Expiration time jitter is a valuable technique employed to address the cache avalanche problem. When the strict timing of cache expirations is not essential from a business perspective, introducing a random jitter to the expiration time of each cached key can be beneficial, particularly when dealing with cached keys generated in batches. This method involves adding a random time variance to the expiration time, ensuring that cached keys do not all expire simultaneously, effectively mitigating the cache avalanche issue.
Refresh-Ahead Caching Strategy
The Refresh-Ahead caching strategy, which we discussed earlier in the context of mitigating the cache breakdown problem, can also serve as a valuable tool to address the cache avalanche issue. In this scenario, rather than relying on fixed expiration times for hot data, the Refresh-Ahead strategy is applied to ensure that data is refreshed before it expires, as long as it continues to be in high demand through frequent queries.
By employing the Refresh-Ahead approach in the context of cache avalanche mitigation, you can proactively refresh and maintain hot data in the cache, preventing it from expiring altogether. This strategy helps ensure that frequently accessed data remains readily available, reducing the risk of cache avalanche scenarios where a multitude of cached keys suddenly become invalid and overwhelm the primary database.
High-Availability
The last technique to mitigate the cache avalanche problem is to make the caching layer highly available. When the caching layer is highly available, it means that even if the primary instance of the caching layer experiences a crash or downtime, the database will not be inundated by an unexpected surge of queries. We will explore the high-availability options available in Dragonfly in more detail in the Dragonfly High Availability section below.
Discussion
In this blog post, we've delved into some of the most prevalent caching challenges that can disrupt your services:
- Cache penetration: Cache is always bypassed by a key/ID that doesn't exist in the system
- Cache breakdown: A hotkey suddenly expires or gets evicted, causing a surge of queries
- Cache avalanche: A lot of cached keys become invalid/inaccessible simultaneously
We have also explored techniques to mitigate these problems, such as:
- Caching empty results (cache penetration)
- Bloom filter (cache penetration)
- Refresh-ahead caching strategy (cache breakdown and cache avalanche)
- Expiration time jitter (cache avalanche)
- High-availability (cache avalanche)
Among these techniques, the Refresh-Ahead caching strategy has proven to be particularly powerful. We have added it to our Dragonfly examples repository to illustrate its implementation. Here is a brief walkthrough of the most important snippets of the example code.
Upon receiving a request, the service first checks the cache for the requested data. A GET command and a TTL command are pipelined to Dragonfly to retrieve the data and its expiration time. The cacheKey is based on the HTTP path (i.e., /blogs/{blog_uuid}).
// cache_refresh_ahead.go
// Pipeline a GET command and a TTL command.
commands, err := m.client.Pipelined(ctx, func(pipe redis.Pipeliner) error {
pipe.Get(ctx, cacheKey)
pipe.TTL(ctx, cacheKey)
return nil
})
// Extract results & errors from the pipelined commands.
var (
cacheData, dataErr = commands[0].(*redis.StringCmd).Bytes()
cacheTTL, ttlErr = commands[1].(*redis.DurationCmd).Result()
)If the data is not found in the cache, the service will read it from the database and passively load it into Dragonfly, just like the Cache-Aside strategy. This implies that the data is not in high demand anymore. Otherwise, its cache would have been continuously accessed and refreshed.
// cache_refresh_ahead.go
// Cache miss.
if errors.Is(dataErr, redis.Nil) {
log.Info("cache miss - reading from database")
return m.refreshCacheAndSendResponse(c, cacheKey)
}If the data is found in the cache, the service will check the expiration time of the data. If the data is about to expire (the urgency would be based on the refresh-ahead factor), the service will refresh the cache and return the data. Otherwise, the service will return the data directly. It is important to note that the sendResponseAndRefreshCacheAsync method utilizes a new goroutine to run the refresh operation in the background after the current HTTP handler is returned, thus ensuring that the response is sent to the client without delay.
// cache_refresh_ahead.go
// Cache hit.
if cacheTTL < m.refreshAheadDuration {
log.Info("cache hit - refreshing")
m.sendResponseAndRefreshCacheAsync(uid, cacheKey)
return m.sendResponse(c, cacheData)
} else {
log.Info("cache hit - no refreshing")
return m.sendResponse(c, cacheData)
}
Within the sendResponseAndRefreshCacheAsync method, the middleware first tries to acquire refreshLock for the current cacheKey. If the lock is acquired successfully, the middleware will refresh the cache by reading the data from the database and writing it to Dragonfly. Otherwise, the middleware will simply return without doing anything else. This implies that the current data is in high demand, and another concurrent request has already triggered the process of refreshing the cache. The lock mechanism ensures that, under high concurrency, only one goroutine performs the refresh operation.
While the Refresh-Ahead caching strategy needs to be implemented in the service code, as shown above, the idea behind it is simple: we are basically trying to identify the hot data and avoid expiring it prematurely. Similarly, for the caching empty results technique, even though the cached values are invalid (i.e., null, nil), we are still trying to identify the hot data (as it is being requested more frequently by attackers) and avoid evicting it too soon.
It's notable that these caching challenges and strategies are not unique to Dragonfly; they are common issues in many caching scenarios. While the implementation of these techniques may require some adjustments to your service code, Dragonfly offers several advantages that can be beneficial in addressing caching problems effectively. Let's explore some of these advantages below.
Dragonfly LFRU Eviction Policy
In the previous installment of the Developing with Dragonfly series, we introduced Dragonfly's innovative LFRU eviction policy. This policy represents a fusion of the LFU (least frequently used) and LRU (least recently used) strategies, offering a sophisticated approach to managing cache eviction efficiently.
To enable the LFRU eviction policy in Dragonfly, simply pass the cache_mode=true argument during Dragonfly server initialization. What's remarkable about this policy is that it incurs zero memory overhead per cached item, making it highly resource-efficient. Moreover, it's designed to be robust in the face of fluctuations in traffic patterns.
The LFRU eviction policy acts as an additional layer of protection when combined with the Refresh-Ahead caching strategy implemented in the service layer. On the Dragonfly server side, LFRU strives to identify and retain hot data, automatically evicting data with lower demand as the cache approaches its maximum memory limit. This combination of proactive and passive management helps maintain optimal cache performance and responsiveness in dynamic and high-traffic environments.
Dragonfly High Availability
Dragonfly offers several robust methods to ensure high availability in your caching layer, which can be instrumental in preventing cache avalanches and maintaining system stability:
- Replication: Dragonfly supports replication, allowing you to set up secondary instances. In the event of a primary instance failure, the secondary instance can take over via manual failover, ensuring moderately highly available services.
- Compatibility with Redis Sentinel: Dragonfly's compatibility with the Redis protocol and commands means it can also be used with Redis Sentinel, a high-availability solution. This integration enables you to leverage the established capabilities of Redis Sentinel to maintain high availability in your Dragonfly-based caching layer.
- Kubernetes operator: Dragonfly provides an official Kubernetes operator, which streamlines the deployment and management of Dragonfly in Kubernetes environments. Leveraging this operator allows you to achieve high availability in Kubernetes clusters, enhancing your caching layer's resilience and scalability. You can learn more about this operator by referring to our documentation.
Conclusion
This blog post explored common caching challenges, including Cache Penetration, Cache Breakdown, and Cache Avalanche, and has provided practical techniques to mitigate these issues. We've discussed strategies such as the Refresh-Ahead caching strategy, the caching empty results technique, and the expiration time jitter technique, which help optimize cache performance while maintaining data availability. Additionally, Dragonfly's universal LFRU eviction policy and high availability options have been highlighted as powerful tools to enhance caching resilience. By combining these strategies and leveraging Dragonfly's capabilities, you can create a robust caching solution that not only mitigates common pitfalls but also ensures high availability, safeguarding your system against cache-related disruptions. In a future installment of the Developing with Dragonfly series, we will summarize all the other caching strategies and techniques that we have not covered yet.
Explore Dragonfly by having it running in minutes, and join our community to share your feedback and ideas with us. Happy building with Dragonfly, and see you next time!
Published at DZone with permission of Joe Zhou. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments