Designing Communication Architectures With Microservices
Communication between microservices should be robust and efficient.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Modern API Management: Connecting Data-Driven Architectures Alongside AI, Automation, and Microservices.
Microservices-based applications are distributed in nature, and each service can run on a different machine or in a container. However, splitting business logic into smaller units and deploying them in a distributed manner is just the first step. We then must understand the best way to make them communicate with each other.
Microservices Communication Challenges
Communication between microservices should be robust and efficient. When several small microservices are interacting to complete a single business scenario, it can be a challenge. Here are some of the main challenges arising from microservice-to-microservice communication.
Resiliency
There may be multiple instances of microservices, and an instance may fail due to several reasons — for example, it may crash or be overwhelmed with too many requests and thus unable to process requests. There are two design patterns that make communication between microservices more resilient: retry and circuit breakers.
Retry
In a microservices architecture, transient failures are unavoidable due to communication between multiple services within the application, especially on a cloud platform. These failures could occur due to various scenarios such as a momentary connection loss, response time-out, service unavailability, slow network connections, etc. (Shrivastava, Shrivastav 2022).
Normally, these errors resolve by themselves by retrying the request either immediately or after a delay, depending on the type of error that occurred. The retry is carried out for a preconfigured number of times until it times out. However, a point of note is that the logical consistency of the operation must be maintained during the request to obtain repeatable responses and avoid potential side effects outside of our expectations.
Circuit Breaker
In a microservices architecture, as discussed in the previous section, failures can occur due to several reasons and are typically self-resolving. However, this may not always be the case since a situation of varying severity may arise where the errors take longer than estimated to be resolved or may not be resolved at all.
The circuit breaker pattern, as the name implies, causes a break in a function operation when the errors reach a certain threshold. Usually, this break also triggers an alert that can be monitored. As opposed to the retry pattern, a circuit breaker prevents an operation that’s likely to result in failure from being performed. This prevents congestion due to failed requests and the escalation of failures downstream. The operation can be continued with the persisting error enabling the efficient use of computing resources. The error does not stall the completion of other operations that are using the same resource, which is inherently limited (Shrivastava, Shrivastav 2022).
Distributed Tracing
Modern-day microservices-architecture-based applications are made up of distributed systems that are exceedingly complex to design, and monitoring and debugging them becomes even more complicated. Due to the large number of microservices involved in an application that spans multiple development teams, systems, and infrastructures, even a single request involves a complex network of communication. While this complex distributed system enables a scalable, efficient, and reliable system, it also makes system observability more challenging to achieve, thereby creating issues with troubleshooting.
Distributed tracing helps us overcome this observability challenge by using a request-centric view. As a request is processed by the components of a distributed system, distributed tracing captures the detailed execution of the request and its causally related actions across the system's components (Shkuro 2019).
Load Balancing
Load balancing is the method used to utilize resources optimally and to ensure smooth operational performance. In order to be efficient and scalable, more than one instance of a service is used, and the incoming requests are distributed across these instances for a smooth process flow.
In Kubernetes, load balancing algorithms are implemented in a more effective manner using a service mesh, which is based on recorded metrics such as latency. Service meshes mainly manage the traffic between services on the network, ensuring that inter-service communications are safe and reliable by enabling the services to detect and communicate with each other. The use of a service mesh improves observability and aids in monitoring highly distributed systems.
Security
Each service must be secured individually, and the communication between services must be secure. In addition, there needs to be a centralized way to manage access controls and authentication across all services. One of the most popular ways for securing microservices is to use API gateways, which act as proxies between the clients and the microservices. API gateways can perform authentication and authorization checks, rate limiting, and traffic management.
Service Versioning
The deployment of a microservice version update often leads to unexpected issues and breaking errors between the new version of the microservice and other microservices in the system, or even external clients using that microservice. While the team deploying the new version attempts to mitigate and reduce these breaks, multiple versions of the same microservice can be run simultaneously, thereby allowing requests to be routed to the appropriate version of the microservice. This is done using API versioning for API contracts.
Communication Patterns
Communication between microservices can be designed by using two main patterns: synchronous and asynchronous. In Figure 1, we see a basic overview of these communication patterns along with their respective implementation styles and choices.
Figure 1. Synchronous and asynchronous communication with common implementation technologies
Synchronous Pattern
Synchronous communication between microservices is one-to-one communication. The microservice that generates the request is blocked until a response is received from the other service. This is done using HTTP requests or gRPC — a high-performance remote procedure call (RPC) framework. In synchronous communication, the microservices are tightly coupled, which is advantageous for less distributed architectures where communication happens in real time, thereby reducing the complexity of debugging (Newman 2021).
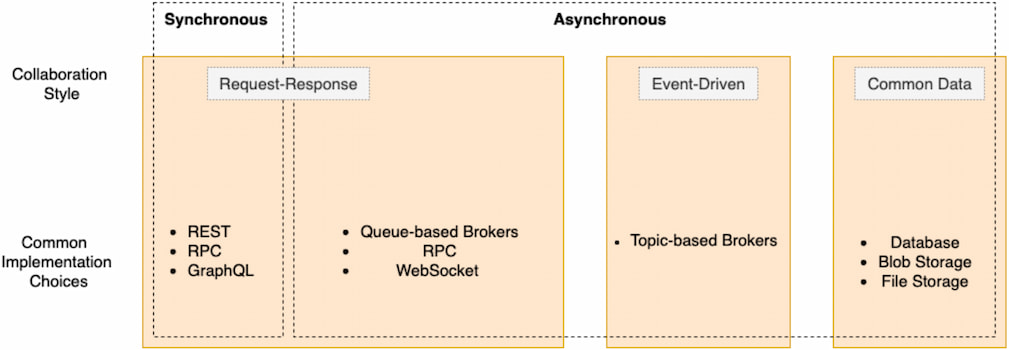
Figure 2. Synchronous communication depicting the request-response model

The following table shows a comparison between technologies that are commonly used to implement the synchronous communication pattern.
Table 1. REST vs. gRPC vs. GraphQL
| REST | gRPC |
GraphQL | |
| Architectural principles |
Uses a stateless client-server architecture; relies on URIs and HTTP methods for a layered system with a uniform interface |
Uses the client-server method of remote procedure call; methods are directly called by the client and behave like local methods, although they are on the server side |
Uses client-driven architecture principles; relies on queries, mutations, and subscriptions via APIs to request, modify, and update data from/on the server |
| HTTP methods |
POST, GET, PUT, DELETE |
Custom methods |
POST |
| Payload data structure to send/receive data |
JSON- and XML-based payload |
Protocol Buffers-based serialized payloads |
JSON-based payloads |
| Request/response caching |
Natively supported on client and server side |
Unsupported by default |
Supported but complex as all requests have a common endpoint |
| Code generation |
Natively unsupported; requires third-party tools like Swagger |
Natively supported |
Natively unsupported; requires third-party tools like GraphQL code generator |
Asynchronous Pattern
In asynchronous communication, as opposed to synchronous, the microservice that initiates the request is not blocked until the response is received. It can proceed with other processes without receiving a response from the microservice it sends the request to. In the case of a more complex distributed microservices architecture, where the services are not tightly coupled, asynchronous message-based communication is more advantageous as it improves scalability and enables continued background operations without affecting critical processes (Newman 2021).
Figure 3. Asynchronous communication
Event-Driven Communication
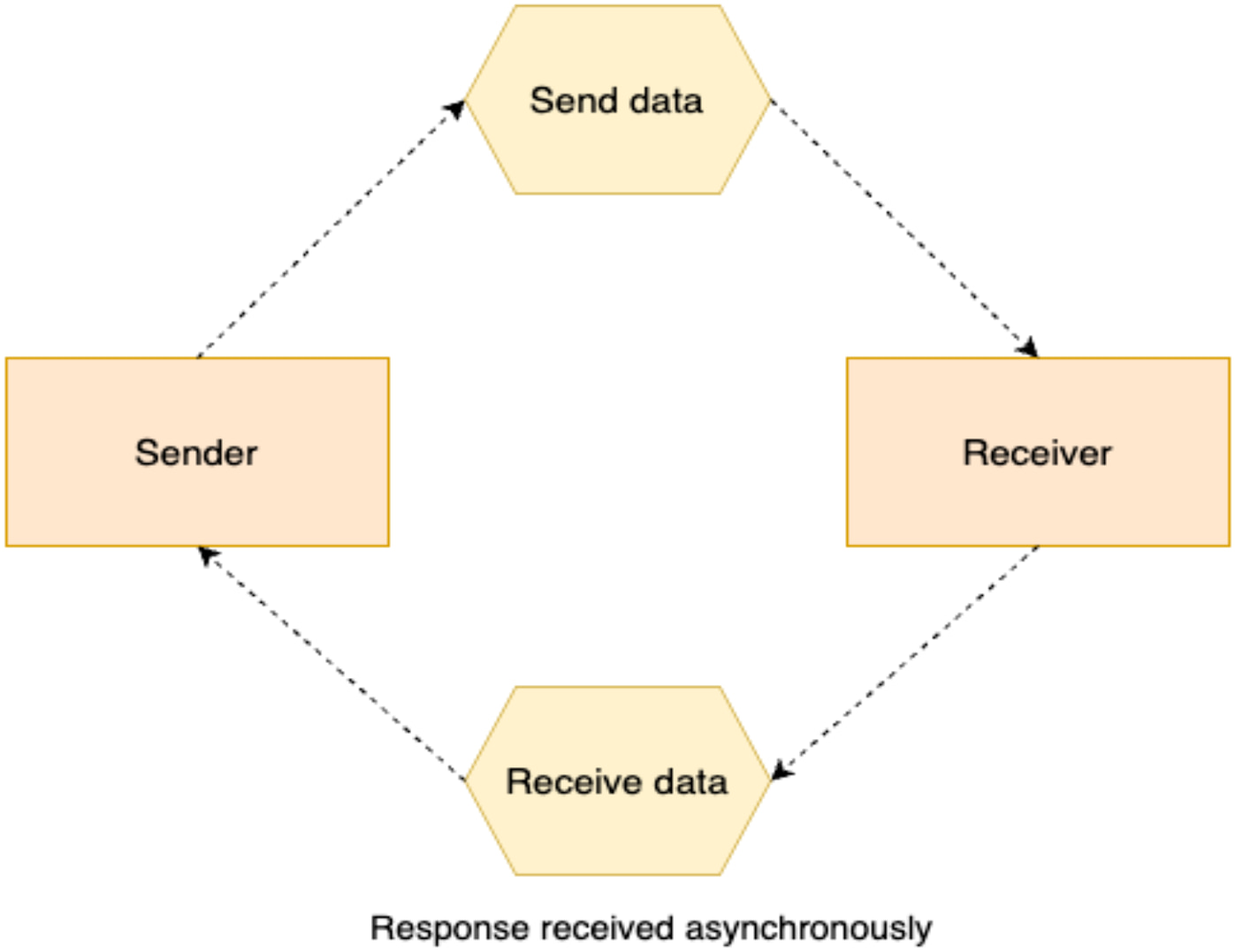
The event-driven communication pattern leverages events to facilitate communication between microservices. Rather than sending a request, microservices generate events without any knowledge of the other microservices' intents. These events can then be used by other microservices as required. The event-driven pattern is asynchronous communication as the microservices listening to these events have their own processes to execute.
The principle behind events is entirely different from the request-response model. The microservice emitting the event leaves the recipient fully responsible for handling the event, while the microservice itself has no idea about the consequences of the generated event. This approach enables loose coupling between microservices (Newman 2021).
Figure 4. Producers emit events that some consumers subscribe to
Common Data
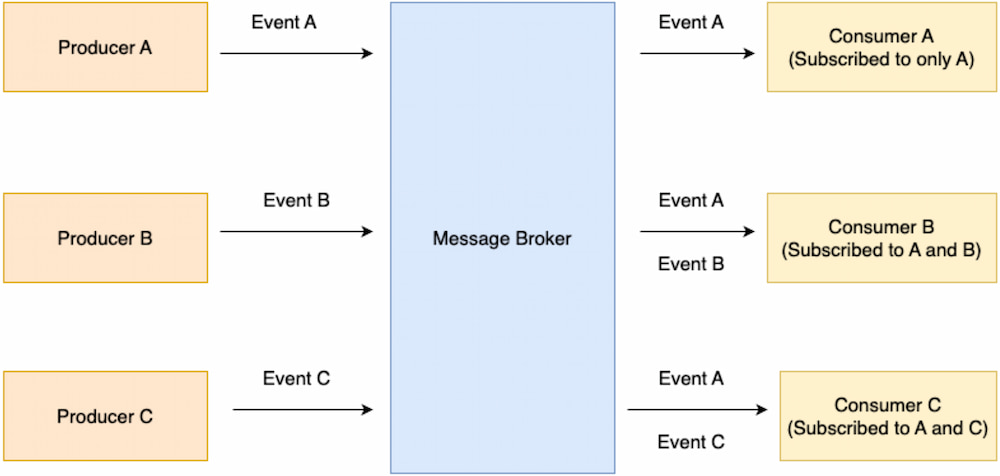
Communication through common data is asynchronous in nature and is achieved by having a microservice store data at a specific location where another microservice can then access that data. The data's location must be persistent storage, such as data lakes or data warehouses.
Although common data is frequently used as a method of communication between microservices, it is often not considered a communication protocol because the coupling between microservices is not always observable when it is used. This communication style finds its best use case in situations that involve large volumes of data as a common data location prevents redundancy, makes data processing more efficient, and is easily scalable (Newman 2021).
Figure 5. An example of communication through common data
Request-Response Communication
The request-response communication model is similar to the synchronous communication that was previously discussed — where a microservice provides a request to another microservice and has to await a response. Along with the previously discussed protocols (HTTP, gPRC, etc.), message queues are used as well.
Request-response is implemented as one of the following two methods:
- Blocking synchronous – Microservice A opens a network connection and sends a request to Microservice B along this connection. The established connection stays open while Microservice A waits for Microservice B to respond.
- Non-blocking asynchronous – Microservice A sends a request to Microservice B, and Microservice Bneeds to know implicitly where to route the response. Also, message queues can be used; they provide an added benefit of buffering multiple requests in the queue to await processing.
- This method is helpful in situations where the rate of requests received exceeds the rate of handling these requests. Rather than trying to handle more requests than its capacity, the microservice can take its time generating a response before moving on to handle the next request (Newman 2021).
Figure 6. An example of request-response non-blocking asynchronous communication

Conclusion
In recent years, we have observed a paradigm shift from designing large, clunky, monolithic applications that are complex to scale and maintain to using microservices-based architectures that enable the design of distributed applications — ones that can integrate multiple communication patterns and protocols across systems. These complex distributed systems can be developed, deployed, scaled, and maintained independently by different teams with fewer conflicts, resulting in a more robust, reliable, and resilient application.
Using the most optimal communication pattern and protocol for the exact operation that a microservice must achieve is a crucial task and has a huge impact on the functionality and performance of an application. The aim is to make the communication between microservices as seamless as possible to establish an efficient system.
In-depth knowledge regarding the available communication patterns and protocols is an essential aspect of modern-day cloud-based application design that is not only dynamic but also highly competitive with multiple contenders providing identical applications and services. Speed, scalability, efficiency, security, and other additional features are often crucial in determining the overall quality of an application, and proper microservices communication is the backbone to achieving those capabilities.
References:
- Shrivastava, Saurabh. Shrivastav, Neelanjali. 2022. Solutions Architect's Handbook, 2nd Edition. Packt.
- Shkuro, Yuri. 2019. Mastering Distributed Tracing. Packt.
- Newman, Sam. 2021. Building Microservices, 2nd Edition. O'Reilly.
This is an excerpt from DZone's 2024 Trend Report, Modern API Management: Connecting Data-Driven Architectures Alongside AI, Automation, and Microservices.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments