Deep Learning vs. Machine Learning
If you have often wondered to yourself about the difference between machine learning and deep learning, read on to get a detailed comparison in simple layman language.
Join the DZone community and get the full member experience.
Join For FreeMachine learning and deep learning are becoming all the rage! Suddenly, everyone is talking about them — regardless of whether they understand the differences! Whether or not you've been actively following data science, you've heard these terms.
Just to show you the kind of attention they are getting, here is the Google trend for these keywords:

If you have often wondered to yourself about the difference between machine learning and deep learning, read on to get a detailed comparison in simple layman language. I explain each of these terms in detail. Then, I compare both of them and explain where we can use them.
What Are Machine Learning and Deep Learning?
Let's start with the basics: what is machine learning and what is deep learning? If you already know this, feel free to skip ahead.
What Is Machine Learning?
The widely quoted definition of Machine learning by Tom Mitchell best explains machine learning in a nutshell. Here’s what it says:
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.”
Did that sound puzzling or confusing? Let’s break this down with simple examples.
Example 1: Machine Learning and Predicting Weights Based on Height
Let's say you want to create a system that tells expected weight based on the height of a person. There could be several reasons why something like this could be of interest. You can use this to filter out any possible frauds or data capturing errors. The first thing you do is collect data. Let's say this is how your data looks:
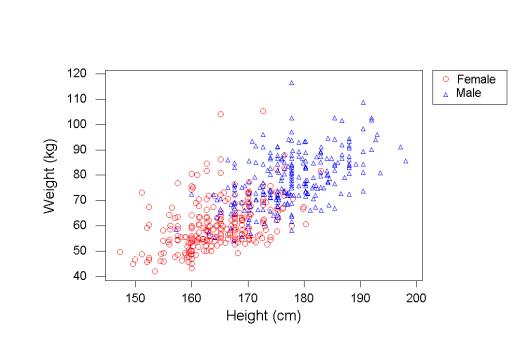
Each point on the graph represents one data point. To start with, we can draw a simple line to predict weight based on height.
For example, a simple line:
Weight (in kg) = Height (in cm) - 100...can help us make predictions. While the line does a decent job, we need to understand its performance. In this case, we can say that we want to reduce the difference between the predictions and actuals. That is our way to measure performance.
Further, the more data points we collect (experience), the better will our model become. We can also improve our model by adding more variables (i.e. gender) and creating different prediction lines for them.
Example 2: Storm Prediction System
Let's take a slightly more complex example. Suppose you are building a storm prediction system. You are given the data of all the storms that have occurred in the past, along with the weather conditions three months before the occurrence of these storms.
If we were to manually build a storm prediction system, what do we have to do?

We have to first scour through all the data and find patterns in this data. Our task is to search which conditions lead to a storm.
We can either model conditions (i.e. if the temperature is greater than 40 degrees Celsius, humidity is in the range of 80-100, etc.) and feed these "features" manually to our system.
We could also make our system understand from the data what will be the appropriate values for these features.
To find these values, you would go through all the previous data and try to predict if there will be a storm. Based on the values of the features set by our system, we evaluate how the system performs; in other words, how many times the system correctly predicts the occurrence of a storm. We can further iterate the above step multiple times, giving performance as feedback to our system.
Let’s take our formal definition and try to define our storm prediction system: Our task T is to determine the atmospheric conditions that would set off a storm. Performance P would be, of all the conditions provided to the system, how many times it will correctly predict a storm. And experience E would be the reiterations of our system.
What Is Deep Learning?
The concept of deep learning is not new. It has been around for a couple of years now. But nowadays with all the hype, deep learning is getting more attention. As we did in machine learning, we will look at a formal definition of deep learning and then break it down with an example.
“Deep learning is a particular kind of machine learning that achieves great power and flexibility by learning to represent the world as nested hierarchy of concepts, with each concept defined in relation to simpler concepts, and more abstract representations computed in terms of less abstract ones.”
That's a bit confusing. Let's break it down with a simple example.
Example 1: Shape Detection
Let me start with a simple example that explains how things happen at a conceptual level. Let's try to understand how we recognize a square from other shapes.

The first thing our eyes do is check if there are four lines associated with a figure (simple concept). If we find four lines, we further check if they are connected, closed, and perpendicular, and also that they are equal (nested hierarchy of concept).
So, we took a complex task (identifying a square) and broke it in simple, less abstract tasks. Deep learning essentially does this at a large scale.
Example 2: Cat vs. Dog
Let’s take an example of an animal recognizer, where our system has to recognize whether the given image is a cat or a dog. Read here how deep learning has taken one step ahead of machine learning in solving this.
Comparison of Machine Learning and Deep Learning
Now that you have gotten an overview of machine learning and deep learning, we will learn a few important points and compare the two techniques.
Data Dependencies
The most important difference between deep learning and traditional machine learning is its performance as the scale of data increases. When the data is small, deep learning algorithms don’t perform that well. This is because deep learning algorithms need a large amount of data to understand it perfectly. On the other hand, traditional machine learning algorithms with their handcrafted rules prevail in this scenario. The below image summarizes this fact.

Hardware Dependencies
Deep learning algorithms heavily depend on high-end machines, contrary to traditional machine learning algorithms, which can work on low-end machines. This is because the requirements of deep learning algorithms include GPUs, which are an integral part of its working. Deep learning algorithms inherently do a large amount of matrix multiplication operations. These operations can be efficiently optimized using a GPU because GPU is built for this purpose.
Feature Engineering
Feature engineering is a process of putting domain knowledge into the creation of feature extractors to reduce the complexity of the data and make patterns more visible to learning algorithms to work. This process is difficult and expensive in terms of time and expertise.
In machine learning, most of the applied features need to be identified by an expert and then hand-coded as per the domain and data type.
For example, features can be pixel values, shape, textures, positions, and orientations. The performance of most machine learning algorithms depends on how accurately the features are identified and extracted.
Deep learning algorithms try to learn high-level features from data. This is a very distinctive part of deep learning and a major step ahead of traditional machine learning. Therefore, deep learning reduces the task of developing a new feature extractor for every problem. For example, convolutional neural networks will try to learn low-level features such as edges and lines in early layers then parts of faces of people and then the high-level representation of a face. Learn more about neural networks and their interesting implementation in deep learning with required codes.
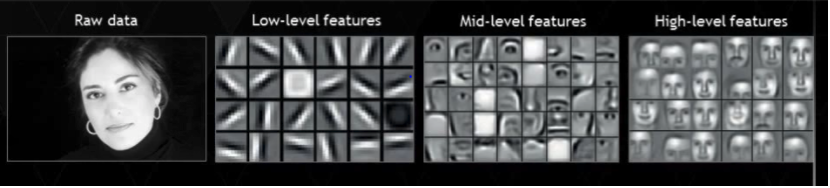
Problem-Solving Approach
When solving a problem using a traditional machine learning algorithm, it is generally recommended to break the problem down into different parts, solve them individually, and combine them to get the result. Deep learning, by contrast, advocates solving the problem end-to-end.
Let’s look at an example to understand this.
Suppose you have a task of multiple object detection. The task is to identify what is the object and where is it present in the image.

In a typical machine learning approach, you would divide the problem into two steps: object detection and object recognition. First, you would use a bounding box detection algorithm like grabcut to skim through the image and find all the possible objects. Then, of all the recognized objects, you would use an object recognition algorithm like SVM with HOG to recognize relevant objects.
On the contrary, in a deep learning approach, you would do the process end-to-end. For example, in a YOLO net (which is a type of deep learning algorithm), you would pass in an image and it would give out the location along with the name of an object.
Execution Time
Usually, a deep learning algorithm takes a long time to train. This is because there are so many parameters in a deep learning algorithm that training them takes longer than usual. The state-of-the-art deep learning algorithm ResNet takes about two weeks to train completely from scratch, whereas machine learning comparatively takes much less time to train, ranging from a few seconds to a few hours.
This is turn is completely reversed on testing time. At test time, the deep learning algorithm takes much less time to run. If you compare it with k-nearest neighbors (a type of machine learning algorithm), test time increases when we increase the size of data. Although this is not applicable on all machine learning algorithms, as some of them have small testing times, too.
Interpretability
Last but not the least, we have interpretability as a factor for comparing machine learning and deep learning.
Let’s take an example. Suppose we use deep learning to automatically score essays. The performance it gives in scoring is quite excellent — it's near-human performance. But there’s an issue. It does not reveal why it has given a score. Indeed, mathematically, you can find out which nodes of a deep neural network were activated. But we don’t know what the neurons were supposed to model and what these layers of neurons were doing collectively. So we fail to interpret the results.
On the other hand, machine learning algorithms like decision trees give us crisp rules as to why they chose what they chose, so it is particularly easy to interpret the reasoning behind it. Therefore, algorithms like decision trees and linear/logistic regression are primarily used in industry for interpretability.
Where Are Machine Learning and Deep Learning Used?
The Wikipedia article on machine learning provides an overview of all the domains where machine learning has been applied. These include:
- Computer vision for applications like vehicle number plate identification and facial recognition.
- Information retrieval for applications like search engines — both text search and image search.
- Marketing for applications like automated email marketing and target identification.
- Medical diagnosis for applications like cancer identification and anomaly detection.
- Natural language processing for applications like sentiment analysis and photo tagging.

The image above aptly summarizes the applications areas of machine learning and covers the broader topic of machine intelligence as a whole.
One prime example of a company using machine learning/deep learning is Google.
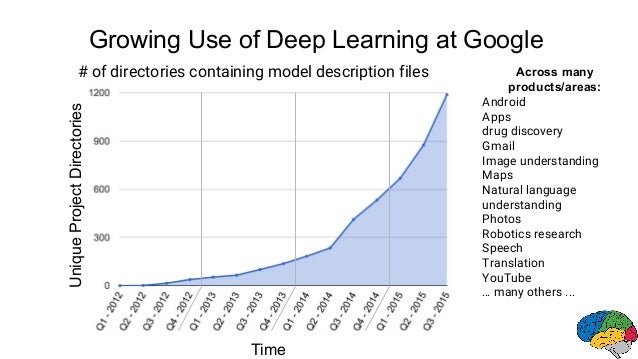
In the above image, you can see how Google is applying machine learning to its various products. Applications of machine learning/deep learning are endless — you just have to look for the right opportunity!
Pop Quiz
To assess if you really understood the difference, we will do a quiz. You can post your answers in this thread.
Please mention the steps below to completely respond to each scenario.
- How would you solve the below problem using machine learning?
- How would you solve the below problem using deep learning?
- Conclusion: Which is a better approach?
Scenario 1
You have to build a software component for a self-driving car. The system you build should take in the raw pixel data from cameras and predict what would be the angle by which you should steer your car wheel.
Scenario 2
Given a person’s credentials and background information, your system should assess whether a person should be eligible for a loan grant.
Scenario 3
You have to create a system that can translate a message written in Russian to Hindi so that a Russian delegate can address the local masses.
Find the discussions and perspectives of various data scientists related to above problems here.
Future Trends
This article provides an overview of machine learning and deep learning and the differences between them. In this section, I’m sharing my views on how machine learning and deep learning will progress in the future.
- First of all, seeing the increasing trend of using data science and machine learning in the industry, it will become increasingly important for each company who wants to survive to inculcate machine learning in their business. Apple is using the power of machine learning in the iPhone X, which marks the growth of this technology.
- Deep learning is surprising us each and every day and will continue to do so in the near future. This is because deep learning is proving to be one of the best techniques with state-of-the-art performance.
- Research is continuous in machine learning and deep learning. But unlike in previous years when research was limited to academia, research in machine learning and deep learning are exploding in both the industry and in academia. And with more funds available than ever before, it is more likely to be a keynote in human development overall.
Published at DZone with permission of Faizan Shaikh. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments