Decision Guidance for Serverless Adoption
This article guides on adoption of Serverless and provides decision guidance for various, architecture and workloads, It shares a list of antipatterns.
Join the DZone community and get the full member experience.
Join For FreeThis article is a part of a series that looks at serverless from diverse points of view and provides pragmatic guides that help in adopting serverless architecture, tackling practical challenges in serverless, and discussing how serverless enables reactive event-driven architectures. The articles stay clear of a Cloud provider serverless services, only referring to those in examples (AWS being a common reference). The articles in this series are published periodically and can be searched with the tag “openupserverless”.
Overview
The Serverless compute model has reached the “Early Adopter” stage in the Hype Curve and moving very fast towards attending the “Early Majority” stage. While the evolution of Serverless has been rapid and phenomenal, enterprises are lacking in strategy in adopting Serverless and leveraging its advancement in technology and architecture for an efficient IT ecosystem. This article attempts to provide simplified decision guidance for Serverless Architecture Adoption while not prescribing specific detailed guidance on the decision matrix of specific FaaS, BaaS, and other serverless services provided by Cloud Service Providers (CSPs) e.g., Serverless Databases, API Gateways or Edge services.
Characteristics of Serverless Candidates
Before we delve into the detailed Serverless adoption guidance, it is important to understand the characteristics of Serverless Candidates that assist in the evaluation process for adoption. The table below provides some technology-neutral traits of application or workload patterns that are an easy fit into serverless. These traits are the building blocks of more complex serverless patterns, solutions, and architectures These characteristics work with a combination and are not exclusive.
S. No. |
Characteristic |
Detail |
Rationale |
1 |
Short Process Running Time |
Functions, applications or services that run for a finite and short time, typically CPU or minimal IO bound.
|
Functions, applications or services' running time affect two important factors:
Cost: Cost is based on execution time (in ms). Concurrency: Processing time affects the throughput and concurrency. The process with a Long running time reduces the throughput. synchronous flows may fail due to time-outs. The following example explains the relation between concurrency, a process running time, and throughput. Concurrency = 2, processing time is 400 ms, and throughput will be 5. If there are more than 5 requests, these will be queued up or throttled.
Simply put, Concurrency = Process Running Time x Request rate per second
The process running time should be short consistently to keep the cost and concurrency in check. |
2 |
Quick Start up |
Lightweight Applications, functions, or services with simple dependencies that use asynchronous execution with quick start-up time. Start-up time may include:
After successful bootstrap and initialization, applications, functions, or services can accept requests to execute |
Typically; Start-up time influences two of serverless challenges 1. Cold Starts 2. Traffic Patterns. Long Start-up time affects the ability to provide consistent throughput. For a traffic pattern that matches a period of idle time (no requests) followed by a sudden spike or burst. During the spike of burst time, functions with significant cold start fail to serve the requests. Inconsistent traffic scenarios, a specified number of function instances are kept in the initialized or warm state by the platform anticipating some requests to be served. Start-up should not impact the required throughput or concurrency in any case, including different traffic scenarios. |
3 |
Consistent and Predictable running time |
Applications, functions, or services that run for consistent and predictable time irrespective of the way and source of the trigger. Variation or semantics of the source of trigger or requests should not impact the running time consistency or predictability. |
Running time impacts the cost, concurrency (and hence throughput) as described in Short Process Running Time characteristic. |
4 |
Consistent and Predictable Usage of Memory |
Serverless platform requires the memory allocation choice as input. Services that use consistent and predictable memory, irrespective of event or a request payload that triggered these, are more suitable for serverless compute form factor than the workloads for which memory requirements vary dynamically. |
Typically, the serverless platform takes the 'memory to be allocated' input and allocated Compute (CPU) based on it. Hence it is important to select the right memory allocation carefully as it controls the allocation of resources like compute by platform and is considered as the key lever for serverless resource allocation. |
5 |
Loose Coupling or Decoupled patterns such as Asynchronous, Reactive, Event Driven |
The genesis of serverless advocates event-driven pattern that essentially provides loose coupling or decoupling. Leveraging the Reactive framework results in IO unlocking or unblocking and optimized use of computing. |
The paradigm of Synchronous execution has two issues i.e., thread blocking and request/execution queueing
In hybrid cloud and distributed environments, this results in poor scalability. The scalability is enhanced significantly with an event-driven pattern that unlocks or unblocks the execution instances, and execution queues are managed by the event-triggering sources. As a result, scaling becomes more dynamic and efficacious. |
6 |
Unpredictable spikes and bursts traffic patterns |
Traffic patterns that cannot be predicted inherently comes with sporadic spikes or bursts. The premise of cloud-native implementation addresses this through elastic scalability making the services resilient and responsive in such situations. |
Serverless compute services are automatically scaled in response to request demand by the platform. Serverless brings this unique differentiation. Without any auto-scaling rules and complexity, the serverless platform handles the request spike and burst, given the specified limit of concurrency and burst capacity. The platform can provide the required number of instances for serverless functions and services to address request spikes if the cold start issue is well managed. |
7 |
Stateless principle of cloud native workloads |
One of the key tenets of 12 factor Cloud Native application is Statelessness. Horizontal scaling helps improve performance by making the required number of instances available to serve the request traffic. Dependency for maintaining state or request affinity to a specific instance leads to ineffective scaling. |
Due to the inherent characteristic of event-driven execution, serverless computing doesn't keep any previous context of request execution. Every instance will execute the request as if it is serving a new request. Other solutions like distributed cache or environment variables can be considered if any state or request context needs to be managed or shared. |
8 |
Execution in parallel |
Parallel execution threads process a service independently without any shared or global state or context. |
Processes or Workloads that can be decomposed into multiple parallel independent functions are suitable for Serverless applications (e.g., processing a large set of structured and unstructured data, Big Data). These types of workloads allow execution of multiple processes as parallel functions. |
9 |
Long Running Process that can be broken into small, short running processes |
Often long-running process that doesn’t maintain a resilient process state can be decomposed into a short-running process that can be executed in parallel. |
Moving to serverless architecture with parallelism and a scalable model for short-running processes will help in reducing sustained execution environment need resulting in lower TCO and improving agility and resiliency. |
10 |
Minimal or no periods of inactivity |
Applications, services, or workload that have the minimum number of requests served without idle time. |
It is sometimes obvious to think that workloads that have a large number of inactivity periods and unpredictable spikes/bursts are suitable for serverless as the platform does not charge for idle time for serverless computing. However, performance is significantly impacted in such cases as the initialization, and bootstrapping context of instances are gone with the instances and cannot be reused as the platform removes these. Such cases are better suited for containers. A minimum consistent number of requests helps maintain a set of initialized and warm functions to serve any traffic. |
11 |
Databases with unpredictable and erratic usage pattern |
Databases that are implemented as serverless services can scale elastically |
Capabilities: A) Databases as serverless services provided by platforms offer capacity-based costing where consumers are charged for the capacity consumed. B) Serverless Database services are elastic in a way that platform manages the underlying storage. For high transaction throughput requirements, the performance provided by Serverless Database services is linear. |
12 |
Quick validation of new ideas |
Validating a new idea/hypothesis that requires quick PoC/PoV. |
Adoption of serverless removes the need for provisioning and configuring any infrastructure. So the function and services can be built rapidly and tested. |
13 |
Continuous data streams that are not bound |
Data streams that are continuous and required to be processed by stream functions such as filters, maps aggregation etc. |
Backend Services, along with FaaS providing processing hooks, can process continuous data streams that are unbound. |
14 |
Processing of IIOT and general IoT Sensor Data |
This also qualifies as Continuous data streams that are not bound. |
Stream processing, IoT analytic & IoT protocol support e.g., MQTT, are provided by Cloud Service Providers. |
15 |
Simplified Operation |
Server maintenance is being viewed as an overhead for the organizations. |
The serverless platform provided managed operation services that can reduce the burden of managing the server environment and simplify operation. |
Candidate Architectures for Serverless
There as certain architectures as follows that are more suitable for serverless adoption across Applications, Data, Integration, AI, IoT, etc.
- Application
- Reactive Systems
- Domain Driven Design based Microservices
- Strangler Transformation
- Data
- Big Data
- Databases that include SQL and No SQL DBs e.g., Document DB, Columnar DB, Key Value, RDBMS, Object Store
- Data Processing
- Stream processing
- CDC
- Batch
- ETL
- Integration
- REST API
- Event Driven
- Notifications
- Messaging
- Event Streams
- Workflows
- Processing
- HTTP/HTTP(s)
- BPM Workflows
- Transcribe
- Transcoding
- AI/ML
- IoT Event Processing
- Blockchain processing
- Cross Cutting (Security & Compliances)
- IAM, identity Federation
- Key, Certificate Management, RBAC, Secret Vaults, HSM
- Firewalls, DDoS,
- Regulatory Data Compliance
- IoT Device Security
- Cross Cutting (DevOps)
- CI/CD
- Observability
- Health Dashboard, Cost Management, Account Management
- IaC
Example Use cases for Serverless Functions
Some of the example use cases for serverless functions are listed below, and the list is not finite but evolving.
- Act on events triggered by internal and external services/sources.
- Schedule tasks according to a specific timetable (periodic), such as taking backups and log analysis.
- Implement API Management for existing services or applications.
- Execute app logic in response to a database change.
- Invoke auto-scalable mobile/API backend services.
- Image processing coupled with Cognitive services for visual recognition.
- Streaming, Image, and Video Manipulation based on targets.
- Perform edge analytics in response to sensor input (IoT).
- Extend and enhance workflows and their data with new functional logic (e.g., send notifications, tag data, add weather data).
- Act as a glue between different services to create a powerful pipeline.
- Implementation of microservices, as well as parallel computing or data processing.
- App requires event-based/asynchronous-based communication to implement use cases.
- Polling use cases, pub-sub kind of realization.
Cases Unfit for Serverless
Also, there are cases where Serverless may not be a suitable option to choose as follows:
- Workloads that need high-performance computing (HPC) with components executed in proximity.
- Processes that have long execution time and require Master/Worker node type of clusters for processing.
- Workloads that require control over the underlying infrastructure components like physical sockets or cores e.g., workload requires licenses that are bound to per-core, per-socket or per-VM.
- Organizations that operate in regulated industries and need compliance with running workloads in dedicated infrastructure instead of multitenant environments.
- Workloads that require complex and/or fine-grained auto-scaling rules with predictive or ML algorithms.
- Tasks are long-running or anticipate long latency (perhaps due to external connections).
- Functions that are complex (non-separable) or take a long time to initialize.
- Requirement mandates stateful sessions to implement the use cases.
- Functions that involve transaction management with DB and, at the same time, have requirements around rapid scaling. DB might become a bottleneck for scaling.
- Compliance requirements mandated by the client (For e.g., if the compliance requires scanning the underlying infrastructure, it is not possible as there are no specific target infrastructures in Serverless).
- Requirements on runtime version for implementation are specific (The reason being we have no control over the serverless runtimes and updates are driven by the vendor).
- Application architecture for serverless is vendor dependent (Potential for vendor lock-in, particularly involving platform capabilities, such as Authentication, Scaling, Monitoring, and Configuration Management).
- Multi-tenancy is not a preferred option when data processed are sensitive in nature.
Simplified Serverless Adoption Decision Guidance Framework
Based on the characteristics, architecture type, and use cases, a simple Serverless Adoption Decision Guidance framework is illustrated below.
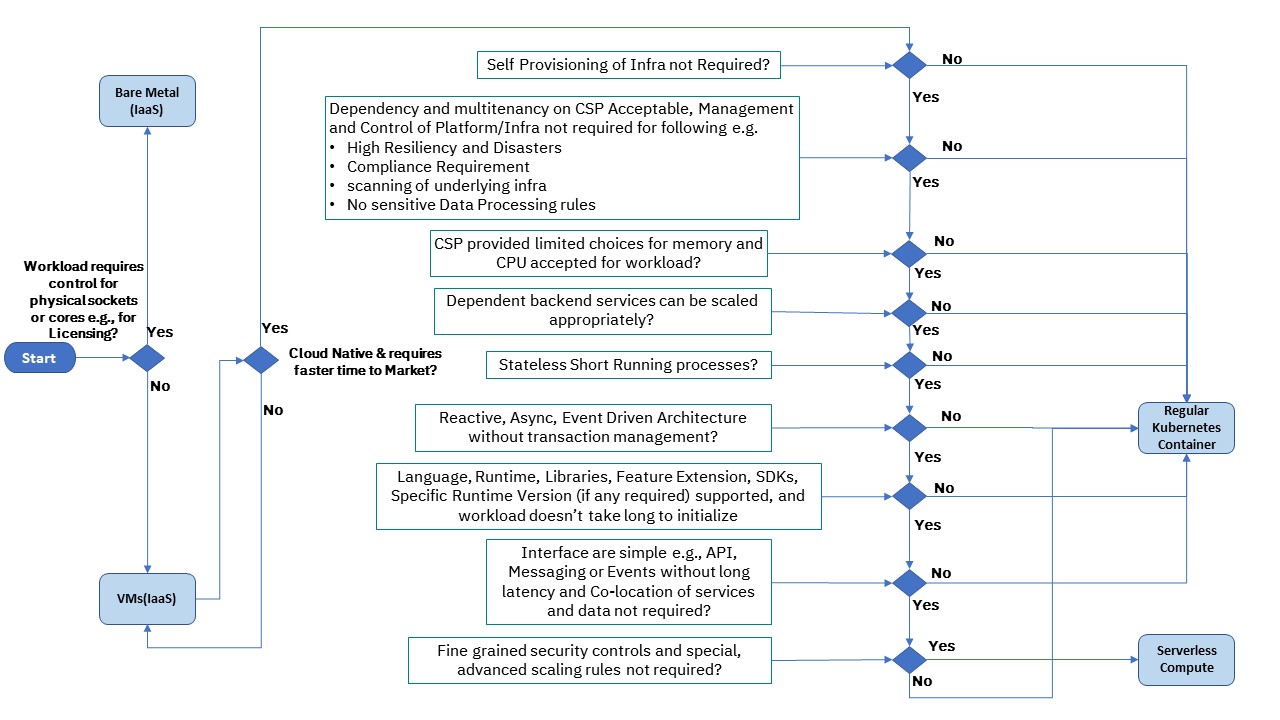
There exist various service types by CSPs for serverless implementation, primarily FaaS/BaaS and Serverless Container Platform.
Key Characteristics of Serverless Platform
Some of the key characteristics of Serverless Platform are listed below.
- Simplified Programming Model because the entire application can be described as event triggers for FaaS and BaaS and that the overall "application" can be composed from smaller serverless building blocks.
- Focus on front-end application Logic using short-running, single-purpose, RESTful functions:
- Simple (JSON) Input / Output
- Localized configuration via environment variables
- Polyglot - Choice of the programming language that suits your needs; Combine functions written in different languages.
- Event Driven - Multiple modes of invocation (Automated via Triggers/Messages, Manual from API invocations)
- Simplified Data and Service Integrations – “out-of-box” integrations with Storage (Database, Object Storage, etc.) Messaging, API Management, and other Provider Services
- Towards “NoOps” - Serverless platform manages operational aspects such as provisioning, deployment, auto-scaling configuration, availability, etc.
- Platform-provided Operational Support Services - “Built-in” support for logging and monitoring, Identity and Access Management, etc.
- Pay for only the Compute you use - Pricing is based on functional execution time or # of requests.
Simple Decision Guide for FaaS/BaaS vs Serverless Platform
It is critical to understand choose between FaaS/BaaS services from CSP or use serverless platform that can run containers. A simple decision guidance is provided below.
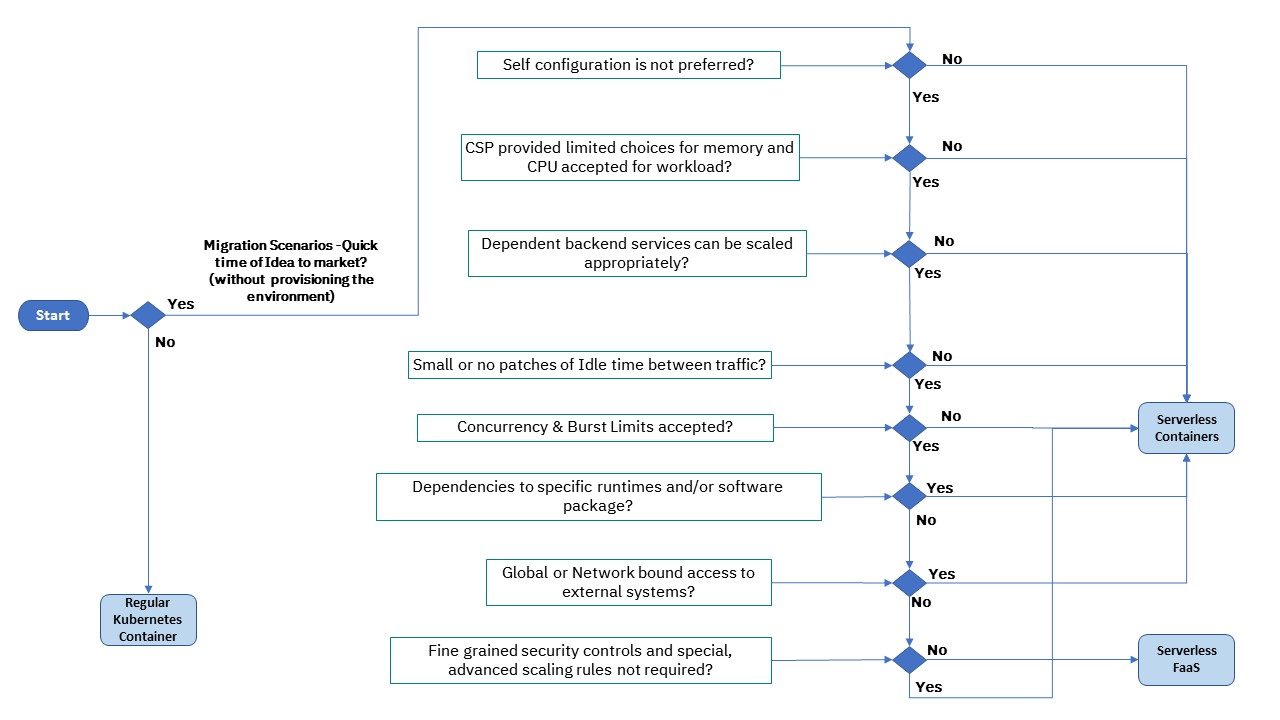
Conclusion
While Serverless Computing is evolving rapidly bring new services and capabilities beyond the typical set of use cases that adopt it currently, may organizations have significant challenges in Serverless adoption strategy fundamentally. This paper attempts to provide simplified guidance that may assists to expedite Serverless adoption.
Opinions expressed by DZone contributors are their own.
Comments