Debugging Kubernetes Part 1: An Introduction
In this first part of this Kubernetes debugging series, take an in-depth view of the underlying technologies from containers to orchestration.
Join the DZone community and get the full member experience.
Join For FreeWhile debugging in an IDE or using simple command line tools is relatively straightforward, the real challenge lies in production debugging. Modern production environments have enabled sophisticated self-healing deployments, yet they have also made troubleshooting more complex. Kubernetes (aka k8s) is probably the most well-known orchestration production environment. To effectively teach debugging in Kubernetes, it's essential to first introduce its fundamental principles.

This part of the debugging series is designed for developers looking to effectively tackle application issues within Kubernetes environments, without delving deeply into the complex DevOps aspects typically associated with its operations. Kubernetes is a big subject: it took me two videos just to explain the basic concepts and background.
Introduction to Kubernetes and Distributed Systems
Kubernetes, while often discussed in the context of cloud computing and large-scale operations, is not just a tool for managing containers. Its principles apply broadly to all large-scale distributed systems. In this post I want to explore Kubernetes from the ground up, emphasizing its role in solving real-world problems faced by developers in production environments.
The Evolution of Deployment Technologies
Before Kubernetes, the deployment landscape was markedly different. Understanding this evolution helps us appreciate the challenges Kubernetes aims to solve. The image below represents the road to Kubernetes and the technologies we passed along the way.
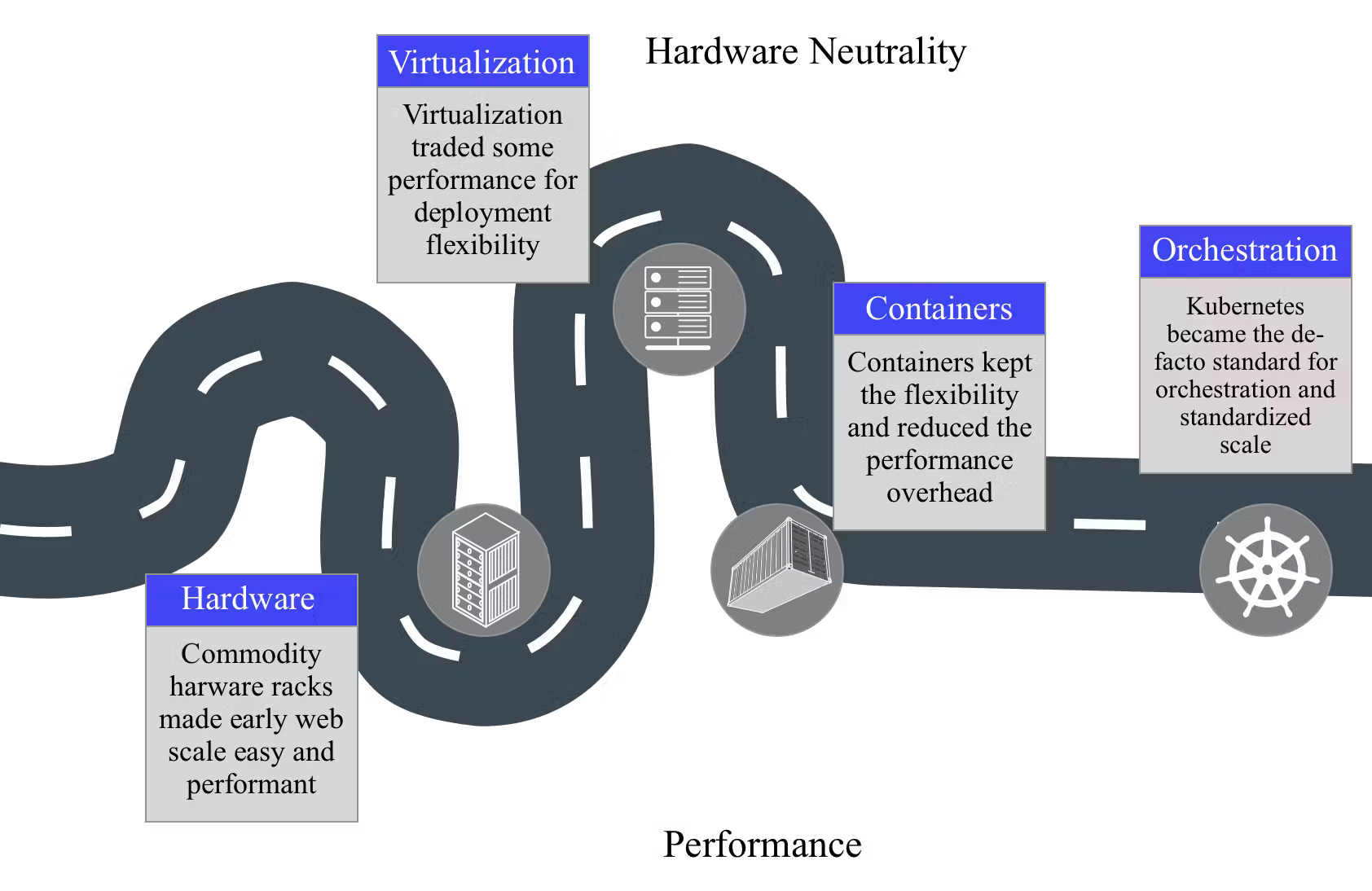
In the image, we can see that initially, applications were deployed directly onto physical servers. This process was manual, error-prone, and difficult to replicate across multiple environments. For instance, if a company needed to scale its application, it involved procuring new hardware, installing operating systems, and configuring the application from scratch. This could take weeks or even months, leading to significant downtime and operational inefficiencies.
Imagine a retail company preparing for the holiday season surge. Each time they needed to handle increased traffic, they would manually set up additional servers. This was not only time-consuming but also prone to human error. Scaling down after the peak period was equally cumbersome, leading to wasted resources.
Enter Virtualization
Virtualization technology introduced a layer that emulated the hardware, allowing for easier replication and migration of environments but at the cost of performance. However, fast virtualization enabled the cloud revolution. It lets companies like Amazon lease their servers at scale without compromising their own workloads.
Virtualization involves running multiple operating systems on a single physical hardware host. Each virtual machine (VM) includes a full copy of an operating system, the application, necessary binaries, and libraries—taking up tens of GBs. VMs are managed via a hypervisor, such as VMware's ESXi or Microsoft's Hyper-V, which sits between the hardware and the operating system and is responsible for distributing hardware resources among the VMs. This layer adds additional overhead and can lead to decreased performance due to the need to emulate hardware.
Note that virtualization is often referred to as "virtual machines," but I chose to avoid that terminology due to the focus of this blog on Java and the JVM where a virtual machine is typically a reference to the Java Virtual Machine (JVM).
Rise of Containers
Containers emerged as a lightweight alternative to full virtualization. Tools like Docker standardized container formats, making it easier to create and manage containers without the overhead associated with traditional virtual machines. Containers encapsulate an application’s runtime environment, making them portable and efficient.
Unlike virtualization, containerization encapsulates an application in a container with its own operating environment, but it shares the host system’s kernel with other containers. Containers are thus much more lightweight, as they do not require a full OS instance; instead, they include only the application and its dependencies, such as libraries and binaries. This setup reduces the size of each container and improves boot times and performance by removing the hypervisor layer.
Containers operate using several key Linux kernel features:
- Namespaces: Containers use namespaces to provide isolation for global system resources between independent containers. This includes aspects of the system like process IDs, networking interfaces, and file system mounts. Each container has its own isolated namespace, which gives it a private view of the operating system with access only to its resources.
- Control groups (cgroups): Cgroups further enhance the functionality of containers by limiting and prioritizing the hardware resources a container can use. This includes parameters such as CPU time, system memory, network bandwidth, or combinations of these resources. By controlling resource allocation, cgroups ensure that containers do not interfere with each other’s performance and maintain the efficiency of the underlying server.
- Union file systems: Containers use union file systems, such as OverlayFS, to layer files and directories in a lightweight and efficient manner. This system allows containers to appear as though they are running on their own operating system and file system, while they are actually sharing the host system’s kernel and base OS image.
Rise of Orchestration
As containers began to replace virtualization due to their efficiency and speed, developers and organizations rapidly adopted them for a wide range of applications. However, this surge in container usage brought with it a new set of challenges, primarily related to managing large numbers of containers at scale.
While containers are incredibly efficient and portable, they introduce complexities when used extensively, particularly in large-scale, dynamic environments:
- Management overhead: Manually managing hundreds or even thousands of containers quickly becomes unfeasible. This includes deployment, networking, scaling, and ensuring availability and security.
- Resource allocation: Containers must be efficiently scheduled and managed to optimally use physical resources, avoiding underutilization or overloading of host machines.
- Service discovery and load balancing: As the number of containers grows, keeping track of which container offers which service and how to balance the load between them becomes critical.
- Updates and rollbacks: Implementing rolling updates, managing version control, and handling rollbacks in a containerized environment require robust automation tools.
To address these challenges, the concept of container orchestration was developed. Orchestration automates the scheduling, deployment, scaling, networking, and lifecycle management of containers, which are often organized into microservices. Efficient orchestration tools help ensure that the entire container ecosystem is healthy and that applications are running as expected.
Enter Kubernetes
Among the orchestration tools, Kubernetes emerged as a frontrunner due to its robust capabilities, flexibility, and strong community support. Kubernetes offers several features that address the core challenges of managing containers:
- Automated scheduling: Kubernetes intelligently schedules containers on the cluster’s nodes, taking into account the resource requirements and other constraints, optimizing for efficiency and fault tolerance.
- Self-healing capabilities: It automatically replaces or restarts containers that fail, ensuring high availability of services.
- Horizontal scaling: Kubernetes can automatically scale applications up and down based on demand, which is essential for handling varying loads efficiently.
- Service discovery and load balancing: Kubernetes can expose a container using the DNS name or using its own IP address. If traffic to a container is high, Kubernetes is able to load balance and distribute the network traffic so that the deployment is stable.
- Automated rollouts and rollbacks: Kubernetes allows you to describe the desired state for your deployed containers using declarative configuration, and can change the actual state to the desired state at a controlled rate, such as to roll out a new version of an application.
Why Kubernetes Stands Out
Kubernetes not only solves practical, operational problems associated with running containers but also integrates with the broader technology ecosystem, supporting continuous integration and continuous deployment (CI/CD) practices. It is backed by the Cloud Native Computing Foundation (CNCF), ensuring it remains cutting-edge and community-focused.
There used to be a site called "doyouneedkubernetes.com," and when you visited that site, it said, "No." Most of us don't need Kubernetes and it is often a symptom of Resume Driven Design (RDD). However, even when we don't need its scaling capabilities the advantages of its standardization are tremendous. Kubernetes became the de-facto standard and created a cottage industry of tools around it. Features such as observability and security can be plugged in easily. Cloud migration becomes arguably easier. Kubernetes is now the "lingua franca" of production environments.
Kubernetes For Developers
Understanding Kubernetes architecture is crucial for debugging and troubleshooting. The following image shows the high-level view of a Kubernetes deployment. There are far more details in most tutorials geared towards DevOps engineers, but for a developer, the point that matters is just "Your Code" - that tiny corner at the edge.
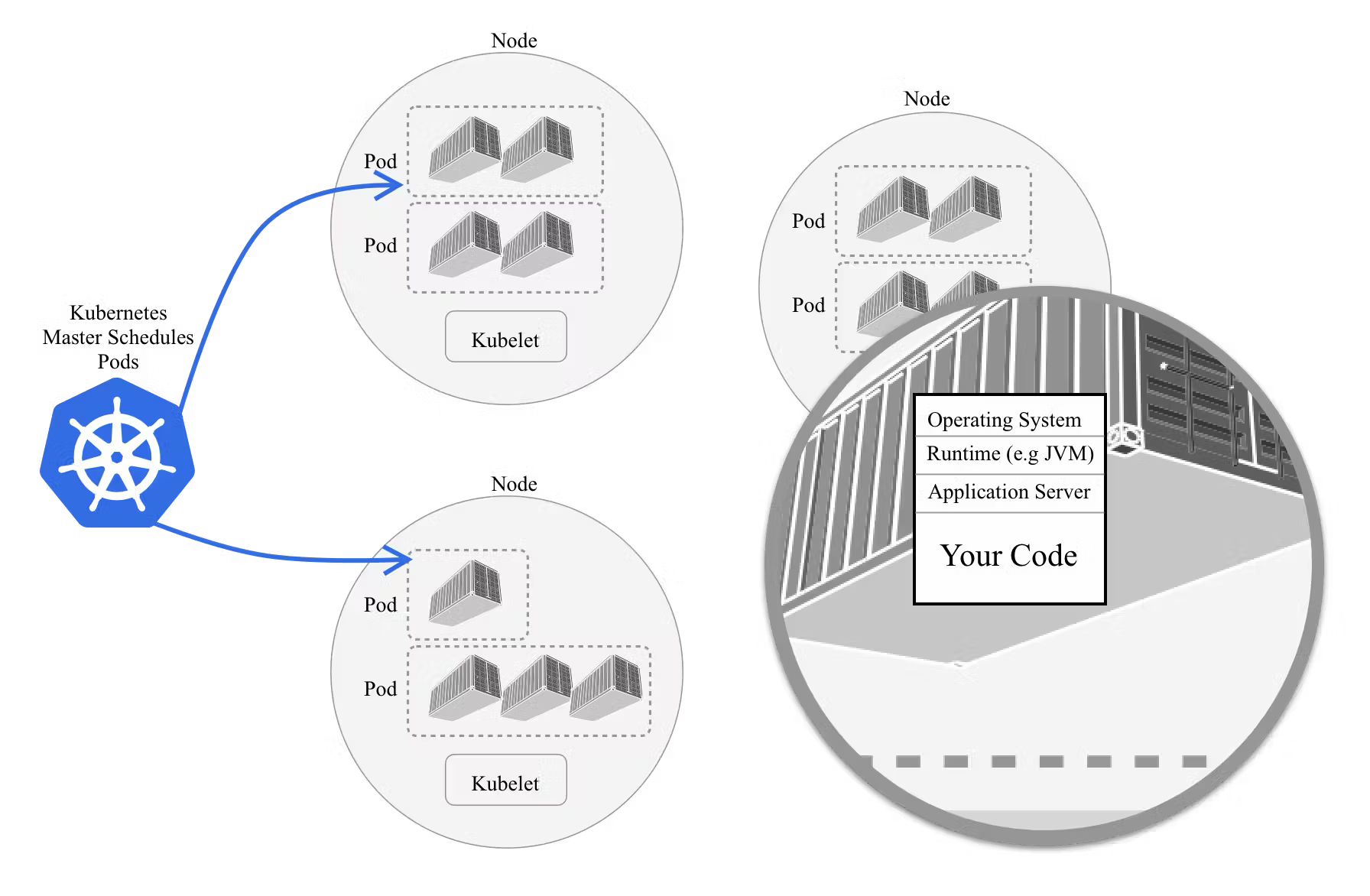
In the image above we can see:
- Master node (represented by the blue Kubernetes logo on the left): The control plane of Kubernetes, responsible for managing the state of the cluster, scheduling applications, and handling replication
- Worker nodes: These nodes contain the pods that run the containerized applications. Each worker node is managed by the master.
- Pods: The smallest deployable units created and managed by Kubernetes, usually containing one or more containers that need to work together
These components work together to ensure that an application runs smoothly and efficiently across the cluster.
Kubernetes Basics In Practice
Up until now, this post has been theory-heavy. Let's now review some commands we can use to work with a Kubernetes cluster. First, we would want to list the pods we have within the cluster which we can do using the get pods command as such:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
my-first-pod-id-xxxx 1/1 Running 0 13s
my-second-pod-id-xxxx 1/1 Running 0 13s
A command such as kubectl describe pod returns a high-level description of the pod such as its name, parent node, etc. Many problems in production pods can be solved by looking at the system log. This can be accomplished by invoking the logs command:
$ kubectl logs -f <pod>
[2022-11-29 04:12:17,262] INFO log data
...
Most typical large-scale application logs are ingested by tools such as Elastic, Loki, etc. As such, the logs command isn't as useful in production except for debugging edge cases.
Final Word
This introduction to Kubernetes has set the stage for deeper exploration into specific debugging and troubleshooting techniques, which we will cover in the upcoming posts. The complexity of Kubernetes makes it much harder to debug, but there are facilities in place to work around some of that complexity.
While this article (and its follow-ups) focus on Kubernetes, future posts will delve into observability and related tools, which are crucial for effective debugging in production environments.
Published at DZone with permission of Shai Almog, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments