Database Sharding and Its Challenges
Database sharding can improve efficiency by optimizing data distribution for enhanced scalability and performance.
Join the DZone community and get the full member experience.
Join For FreeDatabase sharding is a powerful technique employed to manage large databases more effectively. It involves partitioning a large database into smaller, more manageable parts, known as shards. The term "shard" signifies a small fragment of a whole, aptly describing this method of breaking down a large database into smaller, more manageable pieces. Sharding is often applied to databases for several reasons, including improving query performance, facilitating data organization, and enhancing scalability. By distributing data across multiple servers, sharding can significantly reduce the response time for data queries, provide a more organized data structure, and allow for easier scaling as the amount of data grows.
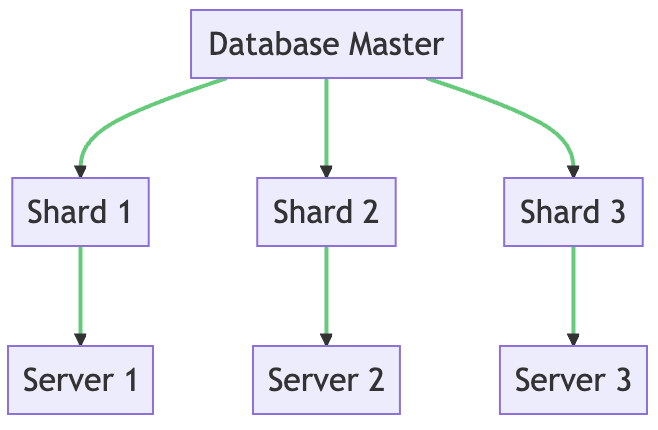
The above diagram presents a visual representation of a sharded database. The primary database is segmented into smaller shards, each of which is stored on a distinct server.
Mechanics of Database Sharding
- Sharding: This involves dividing a large database into smaller fragments. Each shard is an independent database that contains a unique set of data.
- Distribution: Shards are distributed across various servers, each equipped with its own resources. Several factors, such as the geographic location of the data, the type of data, or the anticipated load on the shard, can influence this distribution.
- Independence: Each shard operates independently. Consequently, a query on one shard does not impact the performance of a query on another shard, facilitating high levels of concurrency and speed.
- Scalability: Sharding facilitates horizontal scaling of a database, i.e., by adding more servers, as opposed to vertical scaling, which involves adding more power to a single server. This is particularly beneficial for large databases that need to manage high traffic levels.
- Fault Isolation: If a shard fails, it does not impact the other shards, making it easier to isolate and address issues.
A Simple Sharding Implementation
The following code snippets illustrate how to implement a basic sharding implementation. This implementation is to build understanding and not for use in production systems.
Storing Data
For any new data being inserted into the database, you need to determine which shard to store the data on.
def store_data(data):
# Determine the shard key from the data
shard_key = get_shard_key(data)
# Determine the shard to store the data in based on the shard key
shard = get_shard(shard_key)
# Store the data in the determined shard
shard.store(data)In this example, get_shard_key(data) is a function that determines the shard key based on the data, and get_shard(shard_key) is a function that determines the shard based on the shard key. We will look at implementations of these functions further down below.
Retrieving Data
When retrieving data, we need to determine which shard to retrieve the data from without having to traverse and scour all shards.
def retrieve_data(shard_key):
# Determine the shard to retrieve the data from based on the shard key
shard = get_shard(shard_key)
# Retrieve the data from the determined shard
data = shard.retrieve()
return dataDetermining the Shard Key
The get_shard_key(data) function mentioned in line 3 of both snippets determines the shard key based on the data. The shard key is a piece of data that is used to determine which shard the data should be stored in. The choice of shard key is crucial to the performance of the sharded database, as it affects the distribution of data across the shards.
A common approach is to use a hash function on a particular field in the data. For example, if the data is a user record, the user ID could be used as the shard key. The hash function would take the user ID as input and output a hash value, which is then used as the shard key.
def get_shard_key(data):
# Use a hash function on the user ID to get the shard key
shard_key = hash_function(data.user_id)
return shard_keyDetermining the Shard Based on the Shard Key
The get_shard(shard_key) function determines the shard based on the shard key. This function uses the shard key to select the appropriate shard for storing or retrieving data. A common strategy is to use a consistent hashing ring, where each shard is assigned a range of hash values on the ring. The function finds the shard whose range includes the hash value of the shard key.
def get_shard(shard_key):
# Use the shard key to find the appropriate shard on the consistent hashing ring
shard = consistent_hashing_ring.find_shard(shard_key)
return shard
In this example, consistent_hashing_ring.find_shard(shard_key) is a function that finds the shard whose range includes the hash value of the shard key. The implementation of this function will depend on the specific, consistent hashing algorithm used.
Implementing the Consistent Hashing Ring
Let's consider a simple implementation of the consistent_hashing_ring.find_shard(shard_key) function. This function uses a consistent hashing algorithm to determine the appropriate shard for a given shard key.
class ConsistentHashingRing:
def __init__(self, shards):
self.shards = shards
self.ring = {}
for shard in shards:
hashed_shard = self.hash_function(shard)
self.ring[hashed_shard] = shard
self.sorted_keys = sorted(self.ring)
def hash_function(self, key):
return hash(key)
def find_shard(self, shard_key):
hashed_key = self.hash_function(shard_key)
for key in self.sorted_keys:
if hashed_key <= key:
return self.ring[key]
return self.ring[self.sorted_keys[0]]In this implementation:
- The
__init__method initializes the consistent hashing ring. It hashes each shard and stores it in a dictionary (self.ring), where the hashed shard is the key, and the shard is the value. It also stores the sorted keys inself.sorted_keys. - The
hash_functionmethod is a simple hash function that hashes the input key. In a real-world scenario, you would likely use a more complex hash function to ensure a more even distribution of keys. - The
find_shardmethod finds the appropriate shard for a given shard key. It hashes the shard key and then iterates over the sorted keys until it finds a key that is greater than or equal to the hashed shard key. It then returns the corresponding shard. If it doesn't find a key that is greater than or equal to the hashed shard key, it returns the first shard in the ring. This ensures that the function always returns a shard, even if the hashed shard key is greater than all the keys in the ring.
Challenges of Implementing Sharding
Resharding
Re-sharding is the process of changing the number of shards in a database. It's often necessary when the data distribution becomes uneven or when the database grows or shrinks significantly. For example, if one shard becomes overloaded with data while others are underutilized, re-sharding can help redistribute the data more evenly.
Similarly, if the database has grown and the current number of shards is no longer sufficient, re-sharding can increase the number of shards to improve performance. Re-sharding can be a complex process, as it involves moving data between shards while ensuring that the database remains available and consistent. It often requires careful planning and coordination and may involve temporary performance degradation during the re-sharding process.
Data Distribution
Deciding on a sharding key that ensures data is evenly distributed across all shards can be tricky. Uneven data distribution can lead to some shards being more heavily loaded than others, a condition known as "hot spotting."
Complex Queries
Sharding can make executing complex SQL queries more difficult, as data that would normally reside in one table is spread across multiple shards. This can lead to the need for more complex and potentially slower cross-node joins.
Increased Complexity
Sharding adds an extra layer of complexity to the database architecture. It requires careful planning and management to ensure data consistency and availability. This can also make the system harder to understand and maintain.
Backup and Recovery
Backing up and restoring data can be more complex with sharded databases. Each shard may need to be backed up separately, and restoring data to a specific point in time can be challenging if the shards are not perfectly synchronized.
Transaction Management
In a sharded database, maintaining ACID (Atomicity, Consistency, Isolation, Durability) properties for transactions that span multiple shards can be challenging.
Schema Changes
In a sharded database, making schema changes can be more difficult because the change has to be propagated to all shards.
Despite these challenges, sharding is a powerful technique for managing large-scale databases. With careful design and management, it's possible to overcome these challenges and successfully implement sharding to improve database performance and scalability.
Frameworks for Shard Management
There are several frameworks that assist in shard management for MySQL and PostgreSQL databases. Here are a few notable ones:
- MySQL Cluster: MySQL Cluster automatically and transparently shards across low-cost commodity nodes, allowing scale-out of read and write queries without requiring changes to the application.
- MySQL Fabric: Part of MySQL utilities, MySQL Fabric provides support for sharding. It helps manage a farm of MySQL servers, providing high availability and sharding capabilities.
- Vitess: An open-source database clustering system, Vitess shards MySQL. It is a Cloud Native Computing Foundation project and provides a solution for deploying, scaling, and managing large clusters of MySQL instances.
- Citus for PostgreSQL: PostgreSQL itself does not directly support sharding, but there are several extensions and third-party solutions that provide sharding capabilities. Some of these include Citus, an extension that distributes data and queries across multiple nodes, and Postgres-XL, a fully ACID, horizontally scalable PostgreSQL variant which includes both sharding and parallel query execution.
- ShardingSphere: Related to a database clustering system, ShardingSphere provides data sharding, distributed transactions, and distributed database management. It is an Apache Software Foundation (ASF) project.
These frameworks provide various features that simplify the process of implementing and managing sharding in databases. They help in distributing the data across multiple servers, improving performance, and ensuring high availability. However, the choice of framework depends on the specific requirements of the database system and the application it supports.
Conclusion
Database sharding is a potent technique for managing large databases. While it presents its own set of challenges, careful planning and implementation can ensure effective data distribution and optimized performance. When executed correctly, it can significantly enhance the scalability and performance of your database. There are inherent challenges in implementing a sharding solution. One challenge is having to frequently re-shard to balance the data if its distribution is skewed. It is therefore recommended to use existing frameworks for implementing sharding in your database.
Published at DZone with permission of Faheem Sohail, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments