Data Warehouse for Data Science: Adopting Arrow Flight SQL for 10X Data Transfer
Apache Doris 2.1 supports Arrow Flight SQL protocol for reading data from Doris. It delivers tenfold speedups compared to PyMySQL and Pandas.
Join the DZone community and get the full member experience.
Join For FreeFor years, JDBC and ODBC have been commonly adopted norms for database interaction. Now, as we gaze upon the vast expanse of the data realm, the rise of data science and data lake analytics brings bigger and bigger datasets. Correspondingly, we need faster and faster data reading and transmission, so we start to look for better answers than JDBC and ODBC. Thus, we include the Arrow Flight SQL protocol in Apache Doris 2.1, which provides tens-fold speedups for data transfer.
High-Speed Data Transfer Based on Arrow Flight SQL
As a column-oriented data warehouse, Apache Doris arranges its query results in the form of data Blocks in a columnar format. Before version 2.1, the Blocks must be serialized into bytes in row-oriented formats before they can be transferred to a target client via a MySQL client or JDBC/ODBC driver. Moreover, if the target client is a columnar database or a column-oriented data science component like Pandas, the data should then be de-serialized. The serialization-deserialization process is a speed bump for data transmission.
Apache Doris 2.1 has a data transmission channel built on Arrow Flight SQL. (Apache Arrow is a software development platform designed for high data movement efficiency across systems and languages, and the Arrow format aims for high-performance, lossless data exchange.) It allows high-speed, large-scale data reading from Doris via SQL in various mainstream programming languages. For target clients that also support the Arrow format, the whole process will be free of serialization/deserialization, thus no performance loss. Another upside is, that Arrow Flight can make full use of multi-node and multi-core architecture and implement parallel data transfer, which is another enabler of high data throughput.
For example, if a Python client reads data from Apache Doris, Doris will first convert the column-oriented Blocks to Arrow RecordBatch. Then in the Python client, Arrow RecordBatch will be converted to Pandas DataFrame. Both conversions are fast because the Doris Blocks, Arrow RecordBatch, and Pandas DataFrame are all column-oriented.
![]()
In addition, Arrow Flight SQL provides a general JDBC driver to facilitate seamless communication between databases that support the Arrow Flight SQL protocol. This unlocks the potential of Doris to be connected to a wider ecosystem and to be used in more cases.
Performance Test
The "tens-fold speedups" conclusion is based on our benchmark tests. We tried reading data from Doris using PyMySQL, Pandas, and Arrow Flight SQL, and jotted down the durations, respectively. The test data is the ClickBench dataset.

Results on various data types are as follows:
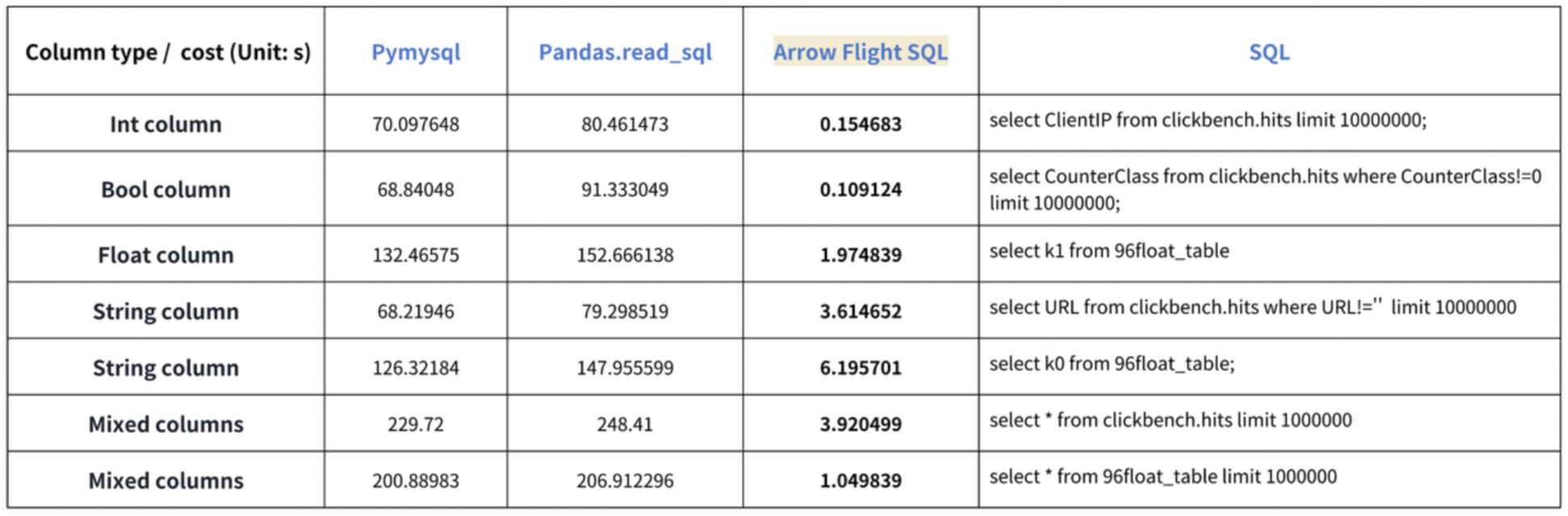
As shown, Arrow Flight SQL outperforms PyMySQL and Pandas in all data types by a factor ranging from 20 to several hundred.
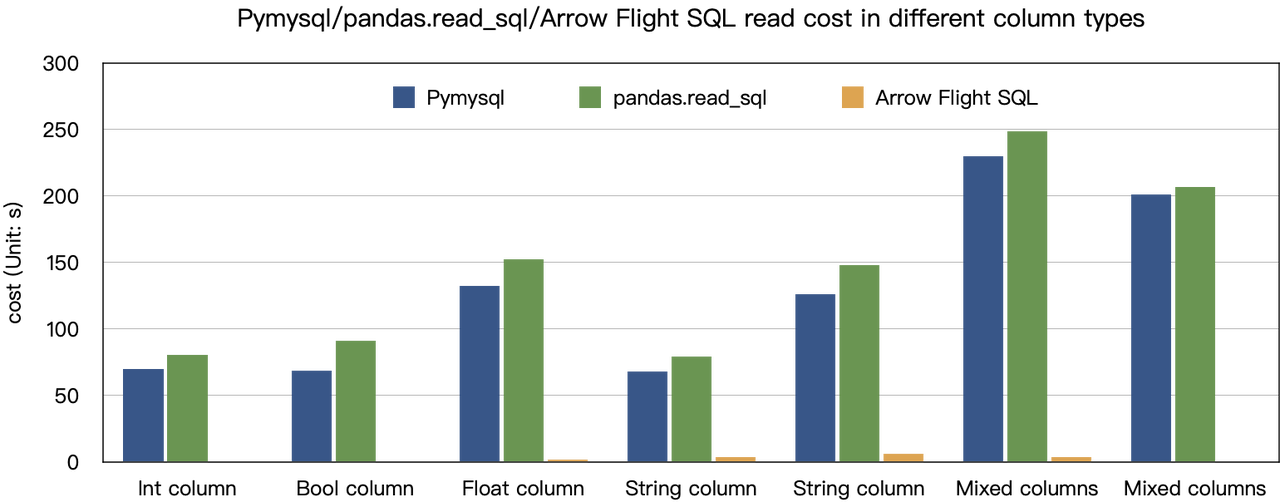
Usage
With support for Arrow Flight SQL, Apache Doris can leverage the Python ADBC Driver for fast data reading. I will showcase a few frequently executed database operations using the Python ADBC Driver (version 3.9 or later), including DDL, DML, session variable setting, and show statements.
1. Install Library
The relevant library is already published on PyPI. It can be installed simply as follows:
pip install adbc_driver_manager
pip install adbc_driver_flightsqlImport the following module/library to interact with the installed library:
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql2. Connect to Doris
Create a client for interacting with the Doris Arrow Flight SQL service. Prerequisites include Doris frontend (FE) host, Arrow Flight port, and login username/password.
Configure parameters for Doris frontend (FE) and backend (BE):
- In
fe/conf/fe.conf, setarrow_flight_sql_portto an available port, such as 9090. - In
be/conf/be.conf, setarrow_flight_portto an available port, such as 9091.
Suppose that the Arrow Flight SQL services for the Doris instance will run on ports 9090 and 9091 for FE and BE respectively, and the Doris username/password is "user" and "pass", the connection process would be:
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()3. Create a Table and Retrieve Metadata
Pass the query to thecursor.execute() function, which creates tables and retrieves metadata.
cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())StatusResult is 0, which means the query is executed successfully. (Such design is to ensure compatibility with JDBC.)
StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
4. Ingest Data
Execute an INSERT INTO statement to load test data into the table created:cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas()) StatusResult
0 05. Execute Queries
Perform queries on the above table, such as aggregation, sorting, and session variable setting.cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas()) k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]6. Complete Code
# Doris Arrow Flight SQL Test
# step 1, library is released on PyPI and can be easily installed.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# step 2, create a client that interacts with the Doris Arrow Flight SQL service.
# Modify arrow_flight_sql_port in fe/conf/fe.conf to an available port, such as 9090.
# Modify arrow_flight_port in be/conf/be.conf to an available port, such as 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# interacting with Doris via SQL using Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# step3, execute DDL statements, create database/table, show stmt.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# step4, insert into
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# step5, execute queries, aggregation, sort, set session variable
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# step6, close cursor
cursor.close()Examples of Data Transmission at Scale
1. Python
In Python, after connecting to Doris using the ADBC Driver, you can use various ADBC APIs to load the Clickbench dataset from Doris into Python. Here's how:#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# PEP 249 (DB-API 2.0) API wrapper for the ADBC Driver Manager.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC reads data into pandas dataframe, which is faster than fetchallarrow first and then to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# Can read multiple partitions in parallel.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -12. JDBC
Usage of this driver is similar to using that for the MySQL protocol. You just need to replace jdbc:mysql in the connection URL with jdbc:arrow-flight-sql. The returned result will be in the JDBC ResultSet data structure.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();3. JAVA
Similar to that with Python, you can directly create an ADBC client with JAVA to read data from Doris. Firstly, you need to obtain the FlightInfo. Then, you connect to each endpoint to pull the data.// method one
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, two steps:
// 1. Execute Query and get returned FlightInfo;
// 2. Create FlightInfoReader to sequentially traverse each Endpoint;
QueryResult queryResult = stmt.executeQuery()
// method two
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// Execute Query and parse each Endpoint in FlightInfo, and use the Location and Ticket to construct a PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
//Create ArrowReader for each PartitionDescriptor to read data
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))4. Spark
For Spark users, apart from connecting to Flight SQL Server using JDBC and JAVA, you can apply the Spark-Flight-Connector, which enables Spark to act as a client for reading and writing data from/to a Flight SQL Server. This is made possible by the fast data conversion between the Arrow format and the Block in Apache Doris, which is 10 times faster than the conversion between CSV and Block. Moreover, the Arrow data format provides more comprehensive and robust support for complex data types such as Map and Array.Hop on the Trend Train
A number of enterprise users of Doris have tried loading data from Doris to Python, Spark, and Flink using Arrow Flight SQL and enjoyed much faster data reading speed. In the future, we plan to include support for Arrow Flight SQL in data writing, too. By then, most systems built with mainstream programming languages will be able to read and write data from/to Apache Doris by an ADBC client. That's high-speed data interaction which opens up numerous possibilities. On our to-do list, we also envision leveraging Arrow Flight to implement parallel data reading by multiple backends and facilitate federated queries across Doris and Spark. Download Apache Doris 2.1 and get a taste of 100 times faster data transfer powered by Arrow Flight SQL. If you need assistance, come find us in the Apache Doris developer and user community.Published at DZone with permission of Shirley H.. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments