Data Versioning 101
Data versioning makes it easy for data consumers to repeat a process or research, compare outputs as a result of using different data versions.
Join the DZone community and get the full member experience.
Join For Free
Data versioning is storing data as new copies after making changes to them so that it is possible to have different versions of such data and retrieve specific versions later. Each version of the data represents a change in the structure, contents, or condition of the data. A new version of a dataset may be created when an existing dataset has been reprocessed, corrected, or updated with more data. In short, data versioning is a means to track changes associated with data.
For example, let’s say a dataset that contained a list of all the countries of the world was stored in a database up to 1990. Starting from the collapse of the Soviet Union in 1991, it might be necessary to update or reprocess the dataset and any conclusions that resulted from it. After all, several countries have been created since 1990.
Many countries were created in 1995 and 1996, up to when South Sudan peacefully seceded from Sudan. Therefore, the dataset that contained the list updated in 1990 is one version. Another version is the updated version created after the countries created between 1990 and 1995 were added to the list. Another version could be the one made after adding the countries formed between 1996 and 2011. Thus, we have three versions of the same data.
How to Version Data
There is no standard for data versioning among data providers. Data is versioned based on specific requirements, guidelines, and choices that may not apply to other disciplines. Some data providers prefer to keep the latest version of their dataset only. Some retain data that supports certain policies and guidelines, while others retain a history of changes to datasets.
There are several ways to version a dataset. Some of them are described below:
- Creating a data version that contains a version number, e.g "v1", "v2", or "v2.1".
- Creating a data version that contains information about the status of the data, e.g., "incomplete" or "unfiltered", etc.
- Creating a data version that includes information about what changes were made, e.g., "normalized", "cropped", or “adjusted”.
Though the above version styles are common, they are not generally accepted by data providers. Some even regard versioning using version numbers as a bad habit. In short, there is no generally accepted way to version data.
Why Is Data Versioning So Important?
Data versioning can be very useful for data reproducibility, trustworthiness, compilation, and auditing. Data versions uniquely identify revisions of a dataset, and the uniqueness helps consumers of such a dataset know whether and how the dataset has changed over a given period. They are able to identify specifically which version of the dataset is being used.
Data versioning makes it easy for data consumers to repeat a process or research, compare outputs as a result of using different data versions. It prevents confusion because consumers are aware of the changes in the dataset. Thus, the output of such a process or research is more trustworthy.
Let’s say a research student is using data collection to confirm a research hypothesis and has published the results of their research. The researcher has to cite the exact version of the data collection used so that other researchers can verify the result of the research for criticism, further study, and consumption.
Also, data versioning can aid compliance and auditing. Some regulatory bodies may want to know how things change over time. For instance, privacy regulations, such as the GDPR, mandate organizations to keep a track record of the available data sources. Data versioning makes it easy for companies to comply with such regulations. Keeping a trackable record of data makes it easier to audit data for compliance with regulations too.
Data Versioning Tools
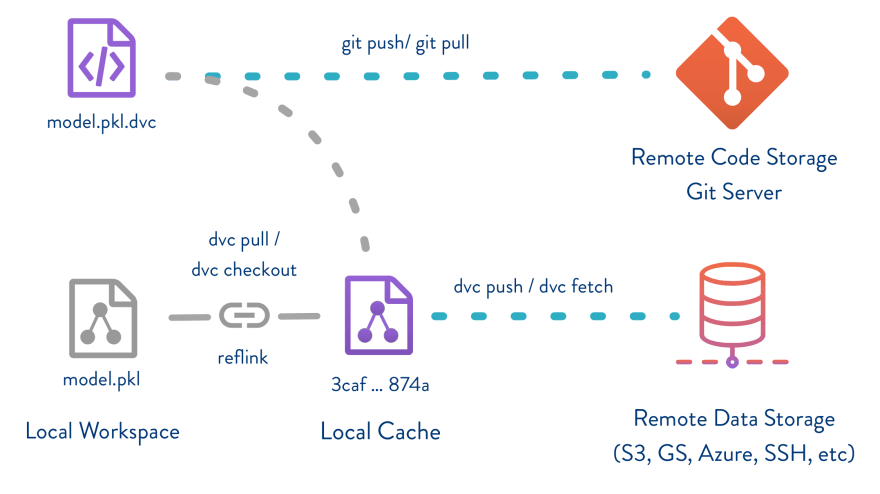
(source)
There are a lot of tools specifically designed for data versioning. Some of them are Data Version Control (DVC), Delta Lake, and Git LFS. Let's look into each one of them below:
DVC - Data Version Control: It is an open-source tool that simplifies data versioning, data science, and machine learning projects. The tool provides a simple command-line that is similar to Git. DVC does more than just data versioning—it also supports pipeline management for machine learning.
Delta Lake: It is also an open-source storage layer that improves data lakes. It makes provision for ACID transactions, managing data versions, and metadata management.
Git LFS: It is an open-source Git extension developed by many Git contributors. As Git is not efficient at dealing with large files, the software aims to use pointers to replace large files (e.g., photos and datasets) that may be added into repositories. The pointers, which are lighter in weight, point to the LFS store to make sure data doesn't occupy too much space.
The tools listed above are some common data versioning tools available for researchers and consumers of data. They are especially useful for data science and machine learning.
Conclusion
Data versioning is the need of the hour as big and dynamic data is on the rise. Many big companies have to handle the dynamic data they receive from clients and customers. Data science and machine learning also require vast amounts of dynamic data. So data versioning makes it easy to manage big and dynamic data and keep a track record.
Opinions expressed by DZone contributors are their own.
Comments