Deploying AI With an Event-Driven Platform
Explore advantages of an event-driven platform for model deployment of your platform and create greater accessibility to your model classifications results.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Enterprise AI Trend Report.
For more:
Read the Report
Today, many large organizations are deploying artificial intelligence (AI) models with an event-driven platform in order to solve two common challenges of leveraging enterprise AI. First, to meet their data needs, enterprises often require a variety of model types that are built on different machine learning (ML), deep learning, and AI languages, frameworks, tools, and systems. These models are tied to various ways of deployment, using tools such as PyTorch, scikit-learn, XGBoost, DJL.AI, spaCy, TensorFlow, ONNX, PMML, Apache MXNet, and H2O. As a result, developers and data engineers need to deploy their models in diverse deployment environments with varying characteristics and restrictions, which makes accessing and managing the models complicated.
Deploying AI with an event-driven platform is a great method for integrating model access within streaming applications. Organizations can deploy and utilize all available libraries, frameworks, and models as part of an event-driven AI platform with open-source model servers and streaming platforms. This simplifies operations, increases flexibility, enables data durability, adds unlimited storage, improves resiliency, and enables near-limitless scalability.
Second, an event-driven AI platform democratizes access to enterprise AI, as the barrier to adopting a single AI platform is lower than adopting multiple platforms. Both technical and non-technical users now have real-time access to model classification results that are enhanced by streaming analytics. This offers numerous benefits to organizations — many use cases not only require AI applications but also need them to be accessible to various types of users within the organization and beyond. Below are the most common use cases that I have seen within different types of organizations all over the world in recent years:
- Visual question and answer
- NLP (natural language processing)
- Sentiment analysis
- Text classification
- Named entity recognition
- Content-based recommendations
- Predictive maintenance
- Fault and fraud detection
- Time-series predictions
- Naive bayes
Democratizing Access to Model Classification Results in Real-Time
In this section, we look at what you need in an event-driven AI platform, along with the details for how to build one. We will also cover advanced features, demonstrate their benefits, and finally, uncover why democratizing access to your AI classifications is important, who those can serve, and how.
Designing Your Event-Driven AI Platform
There are a number of crucial features required in an event-driven AI platform to provide real-time access to models for all users. The platform needs to offer self-service analytics to non-developers and citizen data scientists. These users must be able to access all models and any data required for training, context, or lookup. The platform also needs to support as many different tools, technologies, notebooks, and systems as possible because users need to access everything by as many channels and options as possible.
Further, almost all end users will require access to other types of data (e.g., customer addresses, sales data, email addresses) to augment the results of these AI model executions. Therefore, the platform should be able to join our model classification data with live streams from different event-oriented data sources, such as Twitter and Weather Feeds. This is why my first choice for building an AI platform is to utilize a streaming platform such as Apache Pulsar.
Pulsar is an open-source distributed streaming and publish/subscribe messaging platform that allows your machine learning applications to interact with a multitude of application types, which enables countless users to consume your ML application results. Apache Pulsar is also a general platform capable of handling all possible messaging applications and use cases, as it supports the major messaging protocols and clients in most languages and systems. You will be able to exchange messages with Spark streaming applications, producing and/or consuming messages.
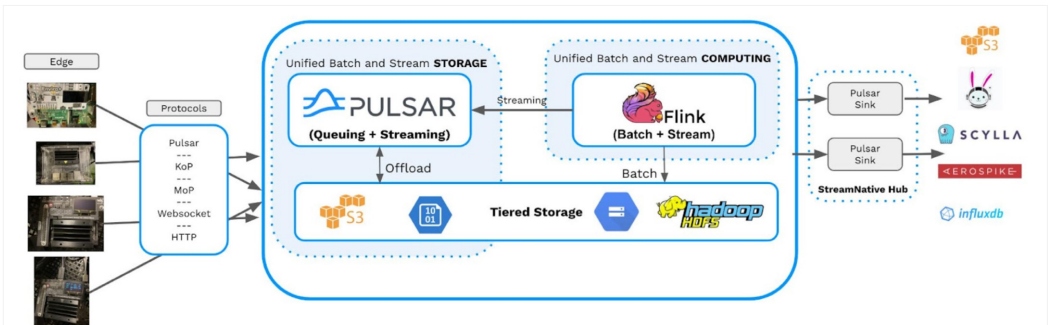
Use Case: Apache Pulsar for ML Applications
For example, with Pulsar SQL, you can run queries against all outputs of your ML applications via SQL, and with Pulsar's tiered storage capability, the output can amount to petabytes worth of data. Citizen data scientists can run these queries from any JDBC-compliant tool, which includes most spreadsheets, query tools, notebooks, web tools, and more. Supporting standard ANSI SQL opens the door to a huge set of tools, making the query results much more accessible to the non-developer world.
Everyone in your organization will also be able to access your AI data or send events to your AI models through the existing protocols. Apache Pulsar supports a large number of protocols, including MQTT, AMQP, WebSockets, REST, and Kafka. So your legacy applications can now add ML functionality without additional development, recompile, rebuild, redeployment, upgrade, rework, or new libraries.
Since Pulsar supports multiple consumers and producers, you are not tied to any one mechanism for triggering your ML models. By deploying your models as stateless functions in Pulsar, you open up a whole new world of possibilities.
In Figure 2, you will see how our ML function can accept messages from three topics or streams of data. Logging, which is a concern of late, is handled as asynchronous topics without concern for external libraries. Machine learning results are then published to log topics that all users can subscribe to.
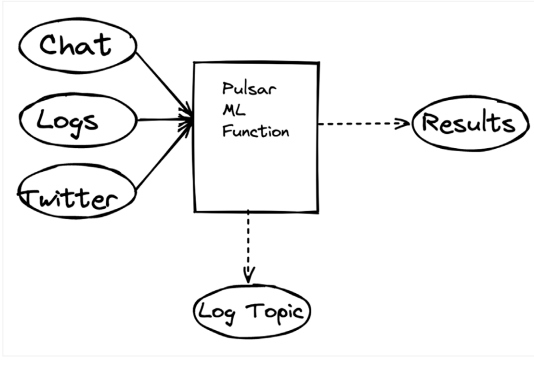
Subscribing To Real-Time Classification Results
Another important requirement when deploying ML models is providing access to the results of classifications and the ability to make calls to your model from anywhere, by anyone you choose, and at any time. Democratizing access to model classifications results must be done in real-time. We need many applications, developers, and systems to receive the results of classifications as they happen. Some users will need the ability to use SQL queries to get these results continuously, while other users need this data as aggregates on an ad hoc basis. There will be applications that run continuous processes that need event-by-event access to these results or may need to join them with other live data sources.
A platform built on Apache Pulsar will also enable any citizen data scientist, nontechnical user, data engineer, front-end developer, SQL developer, data scientist, and analyst to call your models and return results in the format that they need. They can do this in real-time with no coding. The results of model classifications are accessible in universally available messaging topics, which can be read by any number of clients, including WebSockets, REST, and many more tools.
These topics can be accessed via all major messaging protocols for many existing legacy applications. An event-driven AI platform enables as many simultaneous accesses to these results as you need without worrying about scaling, latency, performance, or contention. All-access is decoupled and scaled anywhere via geo-replication when needed. Results can be queried in real-time with applications such Apache Spark and Apache Flink. For low-code development, you can easily connect to Pulsar topics from Apache NiFi and quickly create visual pipelines of your data.
Conclusion
Any enterprise can design and deploy an event-driven AI platform utilizing available open-source projects, frameworks, and tools. The time to start deploying these is now. A platform that developers, engineers, data scientists, data engineers, citizen data scientists, and non-technical users can collaborate on and share without complexity or difficulty is necessary.
When you are ready to build your own event-driven AI platform, make sure your system has all the features you need. The table below summarizes a few of the required capabilities and the nice-to-haves.
| System Requirements |
Bonus Features |
|---|---|
| Open source |
Geo-replication |
| Support for necessary ML and deep learning libraries |
Support for multiple clusters |
| Support for existing pre-built models and your own models |
Unit testing |
| Serverless code execution |
Integrated logging |
| Choice of hosting environment — from on-prem to multi-cloud |
Local run mode |
| Support for asynchronous communication, multi-tenancy, and multiple programming languages |
Support for multiple protocols (e.g., MQTT, AMQP, Kafka, WebSockets) |
| Decoupling of models from users and model execution from model results access; concurrent access to results |
|
| Accessibility from web apps and for citizen data scientists and non-technical users |
|
| Classification subscriptions |
Once you have the needed features, it is easy to trial an initial proof of concept with a simple Docker container running Pulsar, a simple Python machine learning model, and command-line tools to produce input data and consume the final model results.
We have reviewed many advantages of an event-driven platform for model deployment — ranging from the ease of model deployment and the ability to rapidly develop applications to the solutions for enterprise needs like scalability and low latency. With the flexibility to run thousands of models — whether on-prem, in Kubernetes, any cloud environment, or geo-replicated globally — you are ready to deploy your event-driven AI platform and create greater accessibility to your model classifications results. The time is now.
This is an article from DZone's 2022 Enterprise AI Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments