Data Platform: Data Ingestion Engine for Data Lake
In this article, learn how to design and build an automated Data Ingestion Engine based on Spark and Databricks features.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
This article is a follow-up to Data Platform as a Service. In this case, I will describe how to design and build an automated Data Ingestion Engine based on Spark and Databricks features.
The most important principle to design a Data Ingestion Engine is to follow an automation paradigm. Automation provides a set of key advantages to be successful, some of them are in the following diagram:
There are several questions that we have to ask ourselves before starting:
- What is the goal?
- What does automation mean in our case?
- How much time and/or effort can we save with this automation?
- What is the value of this automation to our users and/or product?
- Are there open-source/commercial tools available to get the goal? Do we have to develop a new one?
What Is Automation in Our Case?
By definition, automation means "the use of machines and computers that can operate without needing human control." We are in a software environment; a data pipeline will be an automated computer process, therefore, in our case, "automation" means much more than that.
In this scenario, an automated process means that we don't have to develop a data pipeline for each new dataset. For example, If we need to push data from Kafka to a Data Lake or Data Warehouse as shown in the diagram:
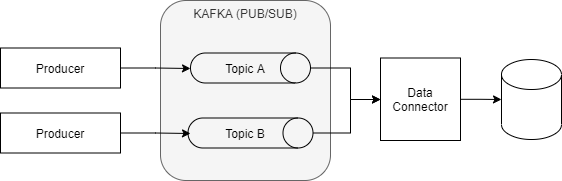
- Manually: We need to develop and deploy a new connector or java application with specific logic for each new topic.
- Automated process: By configuration (GitOps, WebService portal), we can activate the replication of any topic to the Data Lake.
It can be a simple scenario or a very complex one because each topic can have a different kind of data, features, and behaviors such as:
- Avro, JSON, Binary, etc.
- Message split.
- Encrypt/Decrypt attributes.
- Incremental data with only appends.
- Incremental data with the update and remove operations.
Traditionally, in many companies, there are ETL teams that develop custom ETL for each data set, regardless of the case complexity. We need to avoid this kind of solution and work to design automated and standard processes. ETLs have some important challenges such as:
- How to calculate the incremental load between the last data load and now. This is known as DELTA. The most complicated scenario is to detect deletions in a table. Usually, this requires action by the owner of the table such as implement logical deletes or control tables.
- It is not easy to get good performance with big tales, in terms of pipeline duration.
- They have a higher impact on the performance of the database.
How Much Time and/or Effort Can We Save With Automation?
When we design and build a Data Platform, we always need to evaluate if automation provides enough value to compensate the team effort and time. Time is the only resource that we can not scale. We can increase the team, but the relationship between people and productivity is not direct.
Sometimes when a team is very focused on the automation paradigm, people want to automate everything, even actions that only require one time or do not provide real value.
User needs evolve continuously, and new use cases are coming up. We must evaluate very carefully each one below:
- What is the probability to have more use cases like this in the future?
- What is the effort to add to the automated solution vs custom development?
- How much custom development do we have? More custom developments mean more a more complex operation of our Data Platform.
Usually, this is not an easy decision, and it has to be evaluated by all the team. In the end, it is an ROI decision. I don't like this concept very much because it often focuses on economic costs and forgets about people and teams.
Are There Open-Source/Commercial Tools Available?
Before starting any design and development, we have to analyze if there are tools available to cover our needs. As software engineers, we often want to develop our software. But, from a team or product view, we should focus our efforts on the most valuable components and features.
For example, if there is an open-source connector to ingest data from Kafka to Snowflake and if there is a connector to cover all the requirements. Most likely, developing our connector doesn't provide any value to the product and we will make an effort that we could focus on another component.
Architecture
The goal of the Data Ingestion Engine is to make it easier the data ingestion from the data source into our Data Platform providing a standard, resilient and automated ingestion layer.
A Data Engine is composed of different components. It is important to isolate the users from this complexity and provide them a common and friendly self-service platform.
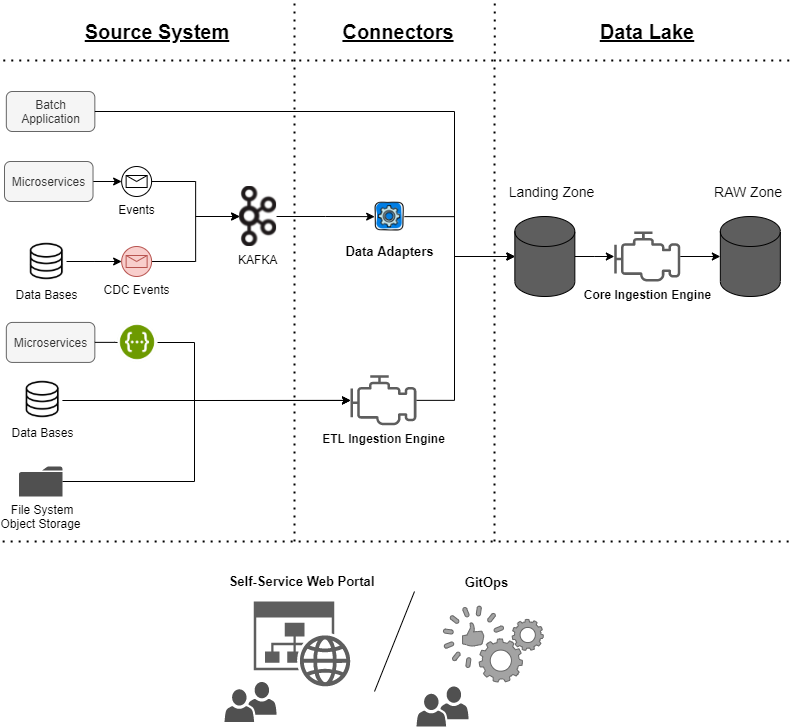
In my opinion, there are four main components in a Data Ingestion Engine:
- Core Ingestion Engine
- Data Adapters
- ETL Ingestion Engine
- Self-service Platform/GitOps
Not all of them are required in all environments; It depends on the maturity of the architecture. For example, if in our architecture all the replication cases from databases can be solved by Change Data Capture (CDC), and we can avoid developing an ETL Ingestion Engine.
Core Ingestion Engine
It is the core of the Data Platform. In this case, we describe a Core Ingestion Engine oriented to a Data Lake platform, but we can follow the same approach in other cases. We begin by analyzing what this automation provides, including the following:
- What is the goal of this engine? Automate and standardize all the data ingestions scenarios (Full copy, Append, Incremental overwrite) by using the same component.
- What does automation mean in our case? Provide a standard component that using several input parameters (metadata), to allow reuse for any dataset that we want to ingest into the Data Platform.
- How much time and/or effort can we save with this automation? We are going to reduce operation effort, failure scenarios and avoid developing a specific process for each data set. The most important thing we are going to reduce the data delivery time to the users.
- What is the value of this automation to our users and/or product? Our users will have the data sooner and with higher quality. We'll improve one of the key assets of the platform.
- Are there open-source/commercial tools available to get the goal? Not for all the requirements, but there are features and tools available to simplify the design and the development such as AutoLaoder.
The landing zone is a storage layer, which acts as a staging area for data. This zone is composed of several cloud object storage organized by data domains. The goal of this layer is to provide a delivery entry point for the different data sources. It is an open layer that allows the teams to upload their data autonomously. At the same time, it is the source of our Core Ingestion Engine.
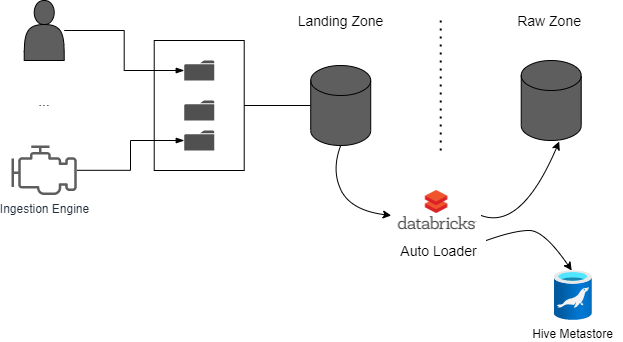
To automate the consolidation of this data in the Raw layer, we are going to build an engine based on Databricks and AutoLoader. The AutoLoader is an interesting Databricks Spark feature that provides out-of-the-box capabilities to automate the data ingestion.
In this article, we are going to use as a landing zone an Azure Data Lake Storage Gen2 (ADLS) for all the cases. But, in the case of near real-time events, we could use Kafka. ADLS allows the collection of objects/files within an account to be organized into a hierarchy of directories and nested subdirectories in the same way that the file system. Another important feature, it allows assigning ACL at the file and folder levels therefore we can share the same ADLS Storage with many users.
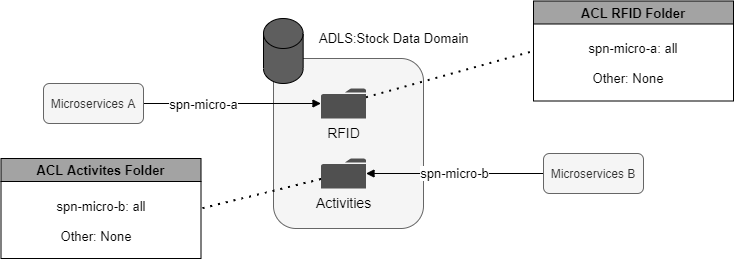
How Does It Work?
The solution and the data flow are simple. When a file is stored in blob storage, an event is triggered to a queue or topic. The autoloader job is subscribed to this queue, reads the event, gets the file, and applies the incremental process.
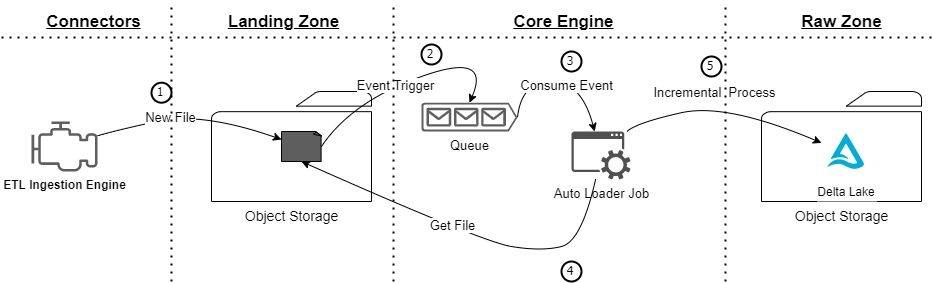
- Landing Zone [1]: Data connectors push the data using files. The core engine allows CSV, Parquet, and Avro files as input.
- Event Trigger [2]: Every time that a file is persisted into the Object Storage, an event is triggered to the Queue or Topic. This event only contains metadata about the file but it is not the file. The goal of this event is to notify the AutoLoader job that there is a new file in the landing zone.
- AutoLoader [3,4,5]: It is a structured spark streaming job that reads the event from the queue/topic, gets the file, and consolidates the information into the Raw zone.
There are several options to detect new files:
- Directory listing.
- File notification.
We've described the file notification behavior. File notification can be provided by using Azure Event Hub or Azure Queue Storage. If Azure Queue Storage is chosen, Auto Loader allows the automatic creation of the Event Grid and the queue. This feature simplifies the automation a lot but, also, the operation and monitoring are more complex because the naming of the queue or topics are not human readable. The monitoring features of Azure Queue Storage are not very good at the moment so it is something to take into account.
All the features make it easier for us to provide a managed service. We've created a generic spark process that contains several ingestions scenarios. Therefore, we can reuse the same process and code to load all the data.
For example, suppose there are two tables that we have to load incrementally in append mode:
- Stock Movements.
- Sales.
If we have a spark generic process that provides incremental functionality, we only need to launch the same spark process with two different configurations to load both tables. In the end, they will be two sparks jobs based on the same code.
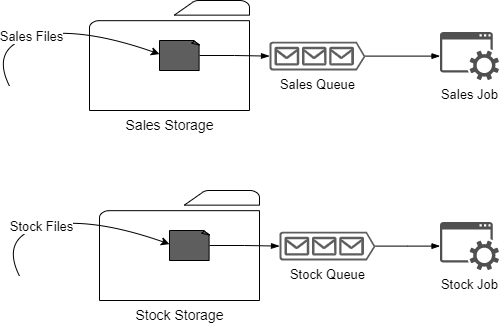
How to Create an Automated Layer
At this point, we have described the flow and capability that autoloader provides to simplify our data ingestion. To provide an automated solution "low-code," we have to add three components:
- Metadata Repository: A Database with the configuration associated with each of the data sets.
- Generic Spark: It can be a notebook that includes the logic for all the scenarios supported.
- Self-service portal: A Website (and/or GitOps) to make this process more user-friendly for all kinds of users. This website allows to persist the configuration and also schedule a new job based on a Generic Spark Process.
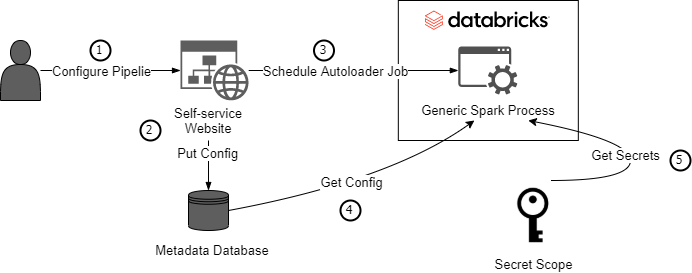
Metadata Repository
As a repository for the Core Ingestion Engine Metadata Database, we can use any RDBMS database, but in this case, we've used an Azure SQL Database. Of course, we could use NoSQL and design the data model based on Documents, but I think an RDBMS is a good option for this case.
There are three main entities that we need to configure a new data pipeline:

- Process Type: Identifies the type of data ingestion we will perform (Full copy, append, incremental, etc.).
- Data Pipeline Configuration: Provides all the configuration related to the data pipeline, such as the storage endpoint, Hive Metastore table name/database, data schema, input file type, etc.
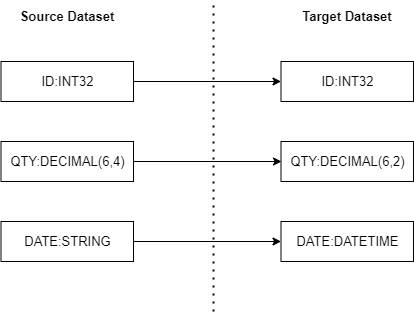
- Data Type Transformation Mapping: There is no exact type relationship between different data repository technologies or even we want to change it. For example, maybe the precision between a number in an Oracle Database is different from the target repository. In another case, sometimes month/year/day are strings, but we want to transform to DateTime type.
In this case, the following information is required for the data_pipeline_configuration table:
- Landing zone information
- DataStorageAccount: The ADLS Gen2 Endpoint.
- DataStorageContainer: The container name.
- DataDirectory: The directory name where the files are uploaded.
- DataFormat: The file type (csv, parquet, avro).
- Storage zone for the autoloader checkpoint (watermark)
- CheckpointStorageAccount
- CheckpointContainer
- CheckpointDirectory
- CheckpointStorageAccount
- Pipeline information
- PipelineId: Unique identifier of the data pipeline.
- Schedule: Databricks scheduler configuration can run on once, hourly or daily schedule.
- JsonSchemaMetadata: Schema associated with parquet input files.
- Partitions: The attributes used to partition the data. For example, a DateTime attribute.
- Header: In the case of CSV input files.
- Delimiter: In the case of CSV input files.
- Status: Pending schedule, running, disable, etc.
- Raw zone information
- DatabaseName: The name of the database in the Hive Metastore.
- TableName: The name of the table in the Hive Metastore.
- DataStorageAccount: The ADLS Gen2 Endpoint.
- DataStorageContainer: The container name.
- DataDirectory: The directory name where the files are uploaded.
- Audit information
- CreationDate
- ModificationDate
- User
In this case, the following information is required for the data_type_trasformation table:
- Source Dataset
- ColumnOrder
- SourceColumnName
- SourceDataType
- Target Dataset
- ColumnOrder
- TargetColumnName
- TargetDataType
- Precision: It is the number of digits to the right (positive) or left (negative) of the decimal point.
- Scale: It is the number of significant digits
- DataFormat
Spark Autoloader Generic Process
The goal is to design a generic code that we can reuse for all the dataset uses cases. Our generic process will have an input parameter called the pipeline id (unique identifier) that we'll use to retrieve all the relevant information to process each dataset. We have to apply the same best practices as always in our code: Clean Code, modular, minimum replication code, tests, etc.

The following code is a simple skeleton based on Databaricks Notebook scala and autoloader:
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet, Statement}
import com.databricks.dbutils_v1.DBUtilsHolder.dbutils
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.{DataType, StructField, StructType}
...
...
import io.delta.tables._
/**
* Step 6:
* Performs scenario-based data ingestion base on the pipeline attributes.
*/
def executePipeline(pipelineDF: DataFrame, pipelineId: Long, pipelineProcessType String): Unit = {
...
if (pipelineProcessType == APPEND) {
...
} else if (pipelineProcessType == "FULL_COPY") {
...
}
}
/**
* Step 1:
* Job input parameter. PipelineId is the unique identifier of the pipeline.
*/
var DataPipelineId = dbutils.widgets.get("DataPipelineId")
/**
* Step 2:
* Get secrets from secret-scope.
*/
val scope: String = "CoreIngestionEgine"
val sqlServerConnectionString: String = dbutils.secrets.get(scope, "SqlMetadataConnection")
val subscriptionId: String = dbutils.secrets.get(scope, "SubscriptionId")
val subscriptionId: String = dbutils.secrets.get(scope, "TenantId")
val connectionString: String = dbutils.secrets.get(scope, storageAccountConnectionString)
...
...
/**
* Step 3:
* Get metadata associated with this pipelineid from Metadata Repository.
*/
try {
connection = getConnectionMetadata()
val getDataPipelineConf = connection.prepareStatement("SELECT * FROM [DataEngine].[data_pipeline_configuration] WHERE [datapipelineid] = ?")
getDataTableStreaming.setString(1, DataPipelineId)
val resultPipelineConfiguration = getDataPipelineConf.executeQuery()
if (resultPipelineConfiguration.next()) {
val landingStorageAccount = resultsDataTableStreaming.getString("DataStorageAccount")
val landingContainer = resultsDataTableStreaming.getString("DataContainer")
val landingDirectory = resultsDataTableStreaming.getString("DataDirectory")
val pipelineProcessType = resultsDataTableStreaming.getString("ProcessType")
....
....
} else {
throw new CriticalException("Pipeline properties for " + database + "." + table + " not found...")
}
} finally {
if (connection != null) {
connection.close()
}
}
/**
* Step 4,5:
* Configure AutoLoader process, connect to the Storage and Queue.
* Calls the function with the processing logic "executePipeline".
*/
if (schemaSource != null && !schemaSource.isEmpty) {
val schema: StructType = DataType.fromJson(schemaSource).asInstanceOf[StructType]
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", format)
.option("cloudFiles.includeExistingFiles", "true")
.option("cloudFiles.useNotifications", "true")
.option("cloudFiles.connectionString", connectionString)
.option("cloudFiles.resourceGroup", resourceGroup)
.option("cloudFiles.subscriptionId", subscriptionId)
.option("cloudFiles.tenantId", tenantId)
.option("cloudFiles.clientId", spnId)
.option("cloudFiles.clientSecret", spnSecret))
.schema(schema)
.load(folderPath)
.writeStream
.queryName("pipeline" + "#" + database + "#" + table)
.foreachBatch({ (pipelineDF: DataFrame, pipelineId: Long, pipelineProcessType: String) =>
executePipeline(pipelineDF, pipelineId, pipelineProcessType)
})
.trigger(Trigger.ProcessingTime(processingTime))
.option("checkpointLocation", checkpointLocation)
.start
.awaitTermination
} else {
throw new CriticalException("Schema for " + database + "." + table + " not found...")
}Self-Service Portal
We have to provide an easy configuration tool to the users. There are no rules to define the best solution. As usual, we have to make the decision based on user skills. For example, in very technical environments, a GitOps approach can be perfect, but if most of the users are business people, Web Portal may be a good choice. The following mockup is a very simple example:

This portal has to be integrated with the SQL Database and also with Databrick. These integrations, in my opinion, have to be the following:
- Synchronous with SQL Database.
- Asynchronous with Databricks, Databricks provides an API Rest to manage the jobs (CRUD).
Tips
Some high-level tips that will help in the development:
- Landing zone: When we store files in the landing zone using a file stream process, the best option is to create the file in a temporal folder until is completed. After it is closed, we can move it to the final path.
- Cost/Performance: It is always a trade-off; each data set can be isolated or we can process several datasets in the same job. To optimize the bulk process and parallelize several datasets in the same job, require a very good design to avoid failures scenarios where a failure in one dataset doesn't impact the rest.
- Cost Metrics: These metrics allow us to analyze the most cost pipelines and plan the platform's growth in terms of cost and resources. In the case of Azure, it is important to set Tag that allows us to analyze the cost of each specific job.
Conclusions
This article describes a simple case to design and build a Data Engine based on Spark. Nowadays, there are a lot of open-source tools and features that help us to automate our solutions. Very often, the key to success is to select correctly on what to focus our time on and which automation generates value. We must never forget the global view and analyze the value of each feature with the team and the users.
We have not discussed Kafka and data connectors; these topics will be covered in future articles in the series.
I hope you had a good time reading!
Opinions expressed by DZone contributors are their own.
Comments