Data Pipeline vs. ETL Pipeline
Understand the key differences, use cases, and best practices for real-time data processing and batch data integration.
Join the DZone community and get the full member experience.
Join For FreeIn today's world, data is a key success factor for many information systems. To exploit data, it needs to be moved and collected from many different locations, using many different technologies and tools.
It is important to understand the difference between a data pipeline and an ETL pipeline. While both are designed to move data from one place to another, they serve different purposes and are optimized for different tasks. The comparison table below highlights the key differences:
| Data PIPELINE VS. ETL Pipeline: Comparison | ||
|---|---|---|
|
Feature |
Data Pipeline |
ETL Pipeline |
|
Processing Mode |
Real-time or near-real-time processing |
Batch processing at scheduled intervals |
|
Flexibility |
Highly flexible with various data formats |
Less flexible, designed for specific data sources |
|
Complexity |
Complex during transformation but easier in batch mode |
Complex during transformation but easier in batch mode |
|
Scalability |
Easily scalable for streaming data |
Scalable but resource-intensive for large batch tasks |
|
Use Cases |
Real-time analytics, event-driven applications |
Data warehousing, historical data analysis |
What Is a Data Pipeline?
A data pipeline is a systematic process for transferring data from one system to another, often in real time or near real time. It enables the continuous flow and processing of data between systems. The process involves collecting data from multiple sources, processing it as it moves through the pipeline, and delivering it to target systems.
Data pipelines are designed to handle the seamless integration and flow of data across different platforms and applications. They play a crucial role in modern data architectures by enabling real-time analytics, data synchronization, and event-driven processing. By automating the data movement and transformation processes, data pipelines help organizations maintain data consistency and reliability, reduce latency, and ensure that data is always available for critical business operations and decision-making.
Start Your Data Journey: Free Course "The Path to Insights: Data Models & Pipelines"
*Affiliate link. See Terms of Use.
Data pipelines manage data from a variety of sources, including:
- Databases
- APIs
- Files
- IoT devices
Processing
Data pipelines can process data in real time or near real time. This involves cleaning, enriching, and structuring the data as it flows through the pipeline. For example, streaming data from IoT devices may require real-time aggregation and filtering before it is ready for analysis or storage.
Delivery
The final stage of a data pipeline is to deliver the processed data to its target systems, such as databases, data lakes, or real-time analytics platforms. This step ensures that the data is immediately accessible to multiple applications and provides instant insights that enable rapid decision making.
Use Cases
Data pipelines are essential for scenarios requiring real-time or continuous data processing.
Common use cases include:
- Real-time analytics: Data pipelines enable real-time data analysis for immediate insights and decision making.
- Data synchronization: Ensures data consistency across different systems in real time.
- Event-driven applications: Facilitate the processing of events in real time, such as user interactions or system logs.
- Stream processing: Handles continuous data streams from sources like IoT devices, social media feeds, or transaction logs.
Data pipelines are often used with architectural patterns such as CDC (Change Data Capture) (1), Outbox pattern (2), or CQRS (Command Query Responsibility Segregation) (3).
Pros and Cons
Data pipelines offer several benefits that make them suitable for various real-time data processing scenarios, but they also come with their own set of challenges.
Pros
The most prominent data pipeline advantages include:
- Real-time processing: Provides immediate data availability and insights.
- Scalability: Easily scales to handle large volumes of streaming data.
- Flexibility: Adapts to various data sources and formats in real time.
- Low latency: Minimizes delays in data processing and availability.
Cons
The most common challenges related to data pipelines include:
- Complex setup: Requires intricate setup and maintenance.
- Resource intensive: Continuous processing can demand significant computational resources.
- Potential for data inconsistency: Real-time processing can introduce challenges in ensuring data consistency.
- Monitoring Needs: Requires robust monitoring and error handling to maintain reliability.
What Is an ETL Pipeline?
ETL, which stands for "Extract, Transform, and Load", is a process used to extract data from different sources, transform it into a suitable format, and load it into a target system (4).
Extract
An ETL program can collect data from a variety of sources, including databases, APIs, files, and more. The extraction phase is separated from the other phases to make the transformation and loading phases agnostic to changes in the data sources, so only the extraction phase needs to be adapted.
Transform
Once the data extraction phase is complete, the transformation phase begins. In this step, the data is reworked to ensure that it is structured appropriately for its intended use. Because data can come from many different sources and formats, it often needs to be cleaned, enriched, or normalized in order to be useful. For example, data intended for visualization may require a different structure to data collected from web forms (5). The transformation process ensures that the data is suitable for its next stage — whether that is analysis, reporting, or other applications.
Load
The final phase of the ETL process is loading the transformed data into the target system, such as a database or data warehouse. During this phase, the data is written to the target optimized for query performance and retrieval. This ensures that the data is accessible and ready for applications (e.g., business intelligence, analytics, reporting, etc.). The efficiency of the loading process is critical because it affects the availability of data to end users. Techniques such as indexing and partitioning can be used to improve performance and manageability in the target system.
Use Cases
ETL processes are essential in various scenarios where data needs to be consolidated and transformed for meaningful analysis.
Common use cases include:
- Data warehousing: ETL aggregates data from multiple sources into a central repository, enabling comprehensive reporting and analysis.
- Business intelligence: ETL processes extract and transform transactional data to provide actionable insights and support informed decision making.
- Data migration projects: ETL facilitates the seamless transition of data from legacy systems to modern platforms, ensuring consistency and maintaining data quality.
- Reporting and compliance: ETL processes transform and load data into secure, auditable storage systems, simplifying the generation of accurate reports and maintaining data integrity for compliance and auditing purposes.
Pros and Cons
Evaluating the strengths and limitations of ETL pipelines helps in determining their effectiveness for various data integration and transformation tasks.
Pros
The most prominent ETL pipeline advantages include:
- Efficient data integration: Streamlines data from diverse sources.
- Robust transformations: Handles complex data cleaning and structuring.
- Batch processing: Ideal for large data volumes during off-peak hours.
- Improved data quality: Enhances data usability through thorough transformations.
Cons
The most common challenges related to ETL pipelines include:
- High latency: Delays in data availability due to batch processing.
- Resource intensive: Requires significant computational resources and storage.
- Complex development: Difficult to maintain with diverse, changing data sources.
- No real-time processing: Limited suitability for immediate data insights.
Data Pipeline vs. ETL Pipeline: Key Differences
Understanding the key differences between data pipelines and ETL pipelines is essential for choosing the right solution for your data processing needs. Here are the main distinctions:
Processing Mode
Data pipelines operate in real time or near real time, continuously processing data as it arrives, which is ideal for applications that require immediate data insights. In contrast, ETL pipelines process data in batches at scheduled intervals, resulting in delays between data extraction and availability.
Flexibility
Data pipelines are highly flexible, handling multiple data formats and sources while adapting to changing data streams in real time. ETL pipelines, on the other hand, are less flexible, designed for specific data sources and formats, and require significant adjustments when changes occur.
Complexity
Data pipelines are complex to set up and maintain due to the need for real-time processing and continuous monitoring. ETL pipelines are also complex, especially during data transformation, but their batch nature makes them somewhat easier to manage.
Scalability
Data pipelines scale easily to handle large volumes of streaming data and adapt to changing loads in real time. ETL pipelines can scale for large batch tasks, but they often require significant resources and infrastructure, making them more resource intensive.
Common Examples of ETL Pipelines and Data Pipelines
To better understand the practical applications of ETL pipelines and data pipelines, let's explore some common examples that highlight their use in real-world scenarios.
Example of ETL Pipeline
An example of an ETL pipeline is a data warehouse for sales data. In this scenario, the input sources include multiple databases that store sales transactions, CRM systems, and flat files containing historical sales data. The ETL process involves extracting data from all sources, transforming it to ensure consistency and accuracy, and loading it into a centralized data warehouse. The target system, in this case, is a data warehouse optimized for business intelligence and reporting.
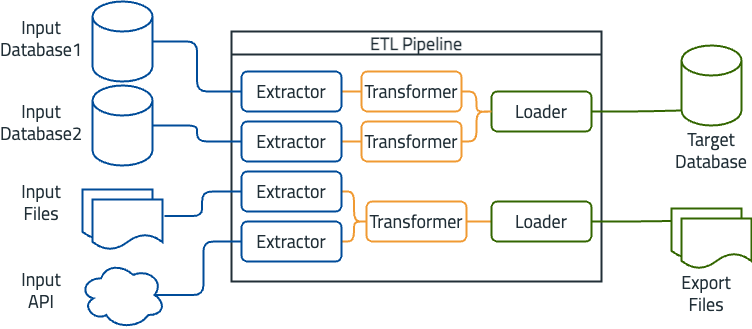
Figure 1: Building a data warehouse around sales data
Example of Data Pipeline
A common example of a data pipeline is real-time sensor data processing — sensors collect data that often needs to be aggregated with standard database data. With that, the input sources include sensors that produce continuous data streams and an input database. The data pipeline consists of a listener that collects data from sensors and the database, processes it in real time, and forwards it to the target database. The target system is a real-time analytics platform that monitors sensor data and triggers alerts.
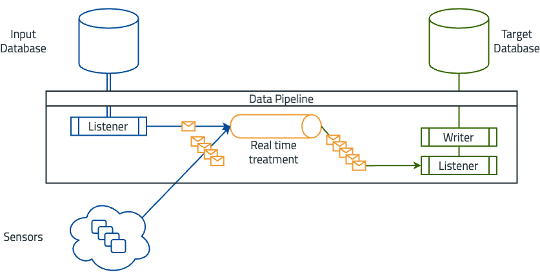
Figure 2: Real-time sensor data processing
How to Determine Which Is Best for Your Organization
Whether an ETL vs data pipeline is best for your organization depends on several factors. The characteristics of the data are critical to this decision. Data pipelines are ideal for real-time, continuous data streams that require immediate processing and insight. ETL pipelines, on the other hand, are suitable for structured data that can be processed in batches where latency is acceptable.
Business requirements also play an important role. Data pipelines are ideal for use cases that require real-time data analysis, such as monitoring, fraud detection, or dynamic reporting. In contrast, ETL pipelines are best suited to scenarios that require extensive data consolidation and historical analysis, like data warehousing and business intelligence.
Scalability requirements must also be considered. Data pipelines offer high scalability for real-time data processing and can efficiently handle fluctuating data volumes. ETL pipelines are scalable for large batch processing tasks but may ultimately require more infrastructure and resources.
Bottom Line: Data Pipeline vs. ETL Pipeline
The choice between a data pipeline and an ETL pipeline depends on your specific data needs and business objectives. Data pipelines excel in scenarios that require real-time data processing and immediate insights, making them ideal for dynamic, fast-paced environments. ETL pipelines, on the contrary, are designed for batch processing, making them ideal for structured data integration, historical analysis, and comprehensive reporting. Understanding these differences will help you choose the right approach to optimize your data strategy and meet your business objectives.
To learn more about ETL and data pipelines, check out these additional courses:
Opinions expressed by DZone contributors are their own.
Comments