Data Analysis for Live Streaming: What Happens in Real Time Is Analyzed in Real Time?
This post is about how a live streaming service provider with 800 million end users found the right database to support its analytic solution.
Join the DZone community and get the full member experience.
Join For FreeAs live streaming emerges as a way of doing business, the need for data analysis follows up.
What's Different About Data Analytics in Live Streaming?
Live streaming is one typical use case for real-time data analysis because it stresses speed. Livestream organizers need to keep abreast of the latest data to see what is happening and maximize effectiveness. To realize that requires high efficiency in every step of data processing:
- Data writing: A live event churns out huge amounts of data every second, so the database should be able to ingest such high throughput stably.
- Data update: As life itself, live streaming entails a lot of data changes, so there should be a quick and reliable data updating mechanism to absorb the changes.
- Data queries: Data should be ready and accessible as soon as analysts want it. Mostly, that means real-time visibility.
- Maintenance: What's special about live streaming is that the data stream has prominent highs and lows. The analytic system should be able to ensure stability during peak times and allow scaling down in off-peak times in order to improve resource utilization. If possible, it should also provide disaster recovery services to guarantee system availability since the worst case in live streaming is interruption.
The rest of this post is about how a live-streaming service provider with 800 million end users found the right database to support its analytic solution.
Simplify the Components
In this case, the live streaming data analytic platform adopts the Lambda architecture, which consists of a batch processing pipeline and a streaming pipeline, the former for user profile information and the latter for real-time generated data, including metrics like real-time subscription, visitor count, comments, and responses.
- Batching processing: The user's basic information stored in HDFS is written into HBase to form a table.
- Streaming: Real-time generated data from MySQL, collected via Flink CDC, goes into Apache Kafka. Flink works as the computation engine, and then the data is stored in Redis.

The real-time metrics will be combined with the user profile information to form a flat table, and Elasticsearch will work as the query engine.
As their business burgeons, the expanding data size becomes unbearable for this platform, with problems like:
- Delayed data writing: The multiple components result in multiple steps in data writing and inevitably lead to prolonged data writing, especially during peak times.
- Complicated updating mechanism: Every time there is a data change, such as that in user subscription information, it must be updated into the main tables and dimensional tables, and then the tables are correlated to generate a new flat table. And don't forget that this long process has to be executed across multiple components. So, just imagine the complexity.
- Slow queries: As the query engine, Elasticsearch struggles with concurrent query requests and data accesses. It is also not flexible enough to deal with the join queries.
- Time-consuming maintenance: All engineers developing or maintaining this platform need to master all the components. That's a lot of training. And adding new metrics to the data pool is labor-intensive.
So, to sum up, the main problem for this architecture is its complexity. To reduce the components means to find a database that is not only capable of most workloads but also performant in data writing and queries. After six months of testing, they finally upgraded their live-streaming analytic platform with Apache Doris.
They converge the streaming and batch-processing pipelines at Apache Doris. It can undertake analytic workloads and also provides a storage layer so data doesn't have to shuffle back to Elasticsearch and HBase as it did in the old architecture.
With Apache Doris as the data warehouse, the platform architecture becomes neater.
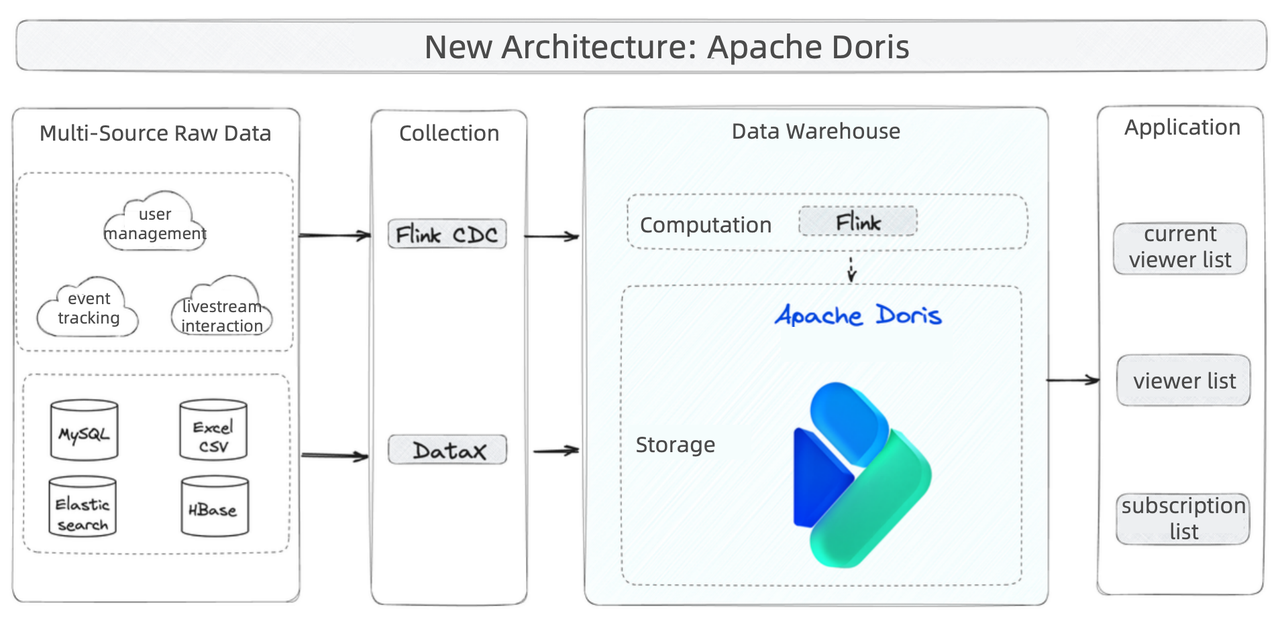
- Smooth data writing: Raw data is processed by Flink and written into Apache Doris in real-time. The Doris community provides a Flink-Doris-Connector with a built-in Flink CDC.
- Flexible data update: For data changes, Apache Doris implements Merge-on-Write. This is especially useful in small-batch real-time writing because you don't have to renew the entire flat table. It also supports partial update of columns, which is another way to make data updates more lightweight. In this case, Apache Doris is able to finish Upsert or Insert Overwrite operations for 200,000 rows per second, and these are all done in large tables, with the biggest ones reaching billions of rows.
- Faster queries: For join queries, Apache Doris can easily join multiple large tables (10 billion rows). It can respond to a rich variety of queries within seconds or even milliseconds, including tag retrievals, fuzzy queries, ranking, and paginated queries.
- Easier maintenance: As for Apache Doris itself, the frontend and backend nodes are both flexibly scalable. It is compatible with MySQL protocol. What took the developers a month now can be finished within a week, which allows for more agile iteration of metrics.
The above shows how Apache Doris speeds up the entire data processing pipeline with its all-in-one capabilities. Beyond that, it has some delightful features that can increase query efficiency and ensure service reliability in the case of live streaming.
Disaster Recovery
The last thing you want in live streaming is service breakdown, so disaster recovery is necessary.
Before the live streaming platform had Apache Doris in place, they only backed up their data to object storage. It took an hour from when a failure was reported to when it was fixed. That one-hour window is fatal for live commerce because viewers will leave immediately. Thus, disaster recovery must be quick.
Now, with Apache Doris, they have a dual-cluster solution: a primary cluster and a backup cluster. This is for hot backup. Besides that, they have a cold backup plan, which is the same as what they did: backing up their everyday data to object storage via Backup and Freeze policies.
This is how they do the hot backup before Apache Doris 2.0:
- Data dual-write: Write data to both the primary cluster and backup cluster.
- Load balancing: In case there is something wrong with one cluster, query requests can be directed to the other cluster via reverse proxy.
- Monitoring: Regularly check the data consistency between the two clusters.
Apache Doris 2.0 supports Cross Cluster Replication (CCR), which can automate the above processes to reduce maintenance costs and inconsistency risks due to human factors.
Data Visualization
In addition to reporting, dashboarding, and ad-hoc queries, the platform also allows analysts to configure various data sources to produce their own visualized data lists.
Apache Doris is compatible with most BI tools on the market, so the platform developers can tap on that and provide a broader set of functionalities for live streamers.
Also, built on the real-time capabilities and quick computation of Apache Doris, live streams can view data and see what happens in real time instead of waiting for a day for data analysis.
Bitmap Index to Accelerate Tag Queries
A big part of data analysis in live streaming is viewer profiling. Viewers are divided into groups based on their online footprint. They are given tags like "watched for over one minute" and "visited during the last minute". As the show goes on, viewers are constantly tagged and untagged. In the data warehouse, it means frequent data insertion and deletion. Plus, one viewer is given multiple tags. To gain an overall understanding of users entails joining queries, which is why the join performance of the data warehouse is important.
The following snippets give you a general idea of how to tag users and conduct tag queries in Apache Doris.
Create a Tag Table
A tag table lists all the tags that are given to the viewers and maps the tags to the corresponding viewer ID.
create table db.tags (
u_id string,
version string,
tags string
) with (
'connector' = 'doris',
'fenodes' = '',
'table.identifier' = 'tags',
'username' = '',
'password' = '',
'sink.properties.format' = 'json',
'sink.properties.strip_outer_array' = 'true',
'sink.properties.fuzzy_parse' = 'true',
'sink.properties.columns' = 'id,u_id,version,a_tags,m_tags,a_tags=bitmap_from_string(a_tags),m_tags=bitmap_from_string(m_tags)',
'sink.batch.interval' = '10s',
'sink.batch.size' = '100000'
);Create a Tag Version Table
The tag table is constantly changing, so there are different versions of it as time goes by.
create table db.tags_version (
id string,
u_id string,
version string
) with (
'connector' = 'doris',
'fenodes' = '',
'table.identifier' = 'db.tags_version',
'username' = '',
'password' = '',
'sink.properties.format' = 'json',
'sink.properties.strip_outer_array' = 'true',
'sink.properties.fuzzy_parse' = 'true',
'sink.properties.columns' = 'id,u_id,version',
'sink.batch.interval' = '10s',
'sink.batch.size' = '100000'
);Write Data Into Tag Table and Tag Version Table
insert into db.tags
select
u_id,
last_timestamp as version,
tags
from db.source;
insert into rtime_db.tags_version
select
u_id,
last_timestamp as version
from db.source;Tag Queries Accelerated by Bitmap Index
For example, analysts need to find out the latest tags related to a certain viewer with the last name Thomas. Apache Doris will run the LIKE operator in the user information table to find all "Thomas." Then, it creates bitmap indexes for the tags. Lastly, it relates all user information tables, tag tables, and tag version tables to return the result.
Of almost a billion viewers, and each of them has over a thousand tags, the bitmap index can help reduce the query response time to less than one second.
with t_user as (
select
u_id,
name
from db.user
where partition_id = 1
and name like '%Thomas%'
),
t_tags as (
select
u_id,
version
from db.tags
where (
bitmap_and_count(a_tags, bitmap_from_string("123,124,125,126,333")) > 0
)
),
t_tag_version as (
select id, u_id, version
from db.tags_version
)
select
t1.u_id
t1.name
from t_user t1
join t_tags t2 on t1.u_id = t2.u_id
join t_tag_version t3 on t2.u_id = t3.u_id and t2.version = t3.version
order by t1.u_id desc
limit 1,10;Conclusion
Data analysis in live streaming is challenging for the underlying database, but it is also where the key competitiveness of Apache Doris comes into play. First of all, Apache Doris can handle most data processing workloads, so platform builders don't have to worry about putting many components together and consequential maintenance issues. Secondly, it has a lot of query-accelerating features, including but not limited to indexes. After tackling the speed issues, the Apache Doris developer community has been exploring its boundaries, such as introducing a more efficient cost-based query optimizer in version 2.0 and an inverted index for text searches, fuzzy queries, and range queries. These features are embraced by the live streaming service provider as they are actively testing them and planning to transfer their log analytic workloads to Apache Doris, too.
Published at DZone with permission of Shirley H.. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments