Dagster: A New Data Orchestrator To Bring Data Closer to Business Value
In this article, learn about a new generation of data orchestrators that has come to evolve the world of data and bring it closer to the operational level.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we are going to analyze a new data orchestrator: Dagster. In our opinion, this is the first generation of data orchestrators that bring data pipelines closer to critical business processes that would really be business data processes for mission-critical solutions. To describe Dagster's capabilities and use cases, we are going to provide some context about patterns and some historical information that is necessary to understand what business value it brings.
In the last decade, many trends have been around orchestration and choreography patterns. We are going to provide a simple description of these patterns:
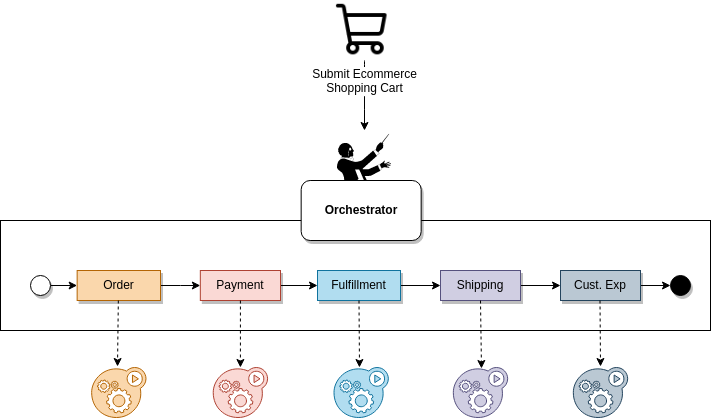
- Orchestration: It is a well-defined workflow orchestrated and centralized by an orchestration system. An orchestration system is like a musical orchestra where there is a conductor that provides direction to musicians to set the tempo and ensure correct entries. There are three main characteristics of orchestration:
- Provide a centralized workflow that allows visualizing easily the business or data process.
- The workflow is managed by a single layer which is the most critical component. If the orchestration system is down there is no business service, without a conductor there is no choral concert.
- They are very flexible to be integrated into different architecture patterns such as APIs, event-driven, RPC, or data processes.
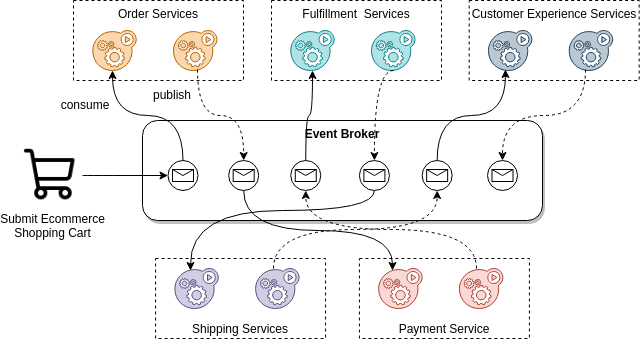
- Choreography: It is based on event-drivenor streaming architecture, the goal is that every component in the architecture works uncouple, and has its own responsibility to make decisions about the actions it has to take. There are three main characteristics of choreography:
- It has to be based on an event-driven or streaming pattern.
- There is no single and centralized layer so there is no single point of failure unless you have a single message broker.
- Provide more scalability, flexibility, and also more complexity to understand the process.
Orchestrators and business process management software have always been close to the business layer, which increased their popularity in the company's strategic tech roadmap. The first generation of BPMs started around the year 2000 and were technologies for software engineers.
A few years later between 2014 and 2018, event-driven and choreography patterns started to increase in popularity, first with Netflix, and then with the appearance of streaming platforms such as Apache Kafka.
The data world always remains a bit late compared to the software world. Although in my opinion, we are moving towards a scenario where the operational and analytical worlds will not be isolated. Architectures and team topologies where the analytical and operational layer work as two different minds are not working when companies need to apply a data-driven approach where data is part of the core of the decision-making process.
What Happened to the World of Data
When the concept of big data started to become popular, the first data orchestrators appeared, such as Apache Ozzie (2010 by Yahoo), based on DAG XML configurations, a scheduled workflow, and very focused on the Hadoop ecosystem. A little later, Apache Airflow (2015 by Airbnb) appeared based on Python. It provided more capabilities such as moving from DAG XML configuration to programmatic configuration, and more integrations outside Hadoop ecosystems, but is also a scheduled workflows system. In the middle of both appeared Luigi (2012 by Spotify): based on Python, but pipeline-oriented instead of DAG, but including interesting software best practices such as A/B testing.
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.1">
...
<decision name="mydecision">
<switch>
<case to="reconsolidatejob">
${fs:fileSize(secondjobOutputDir) gt 10 * GB}
</case> <case to="rexpandjob">
${fs:fileSize(secondjobOutputDir) lt 100 * MB}
</case>
<case to="recomputejob">
${ hadoop:counters('secondjob')[RECORDS][REDUCE_OUT] lt 1000000 }
</case>
<default to="end"/>
</switch>
</decision>
...
</workflow-app>Apache Airflow was the first real evolution in the data orchestrator, but in our opinion has some points of improvement that make it a product very focused on the traditional world of data and not on the new reality in which data is becoming the center of decision-making in companies.
- It has a poor UI interface, totally oriented toward data engineers.
- It is mainly oriented to executing tasks, without knowing what those tasks do.
- Everything is a task, increasing the complexity in terms of maintainability and comprehension.
- At the end of 2021 introduced the concept of sensors which are a special type of operator designed to wait for an external event such as a Kafka event, JMS message, or time-based.
import requests
from airflow.decorators import dag, task
@dag(
dag_id="example_complex",
schedule_interval="0 0 * * *",
start_date=pendulum.datetime(2022, 1, 1, tz="UTC"),
catchup=False,
dagrun_timeout=datetime.timedelta(minutes=60),
)
def ExampleComplex():
...
@task
def get_data():
...
@task
def merge_data():
...
dag = ProcessEmployees()All these developments in orchestration solutions have something in common: the challenges faced by these companies (Yahoo, Airbnb, or Spotify) to manage the complexity in their data pipelines.
Data-Driven: The New Era of Data
This first release of the orchestrator tools was very focused on data engineers' experience and based on traditional analytical and operational platforms architecture such as data lakes, data hubs, or experiments data science workspaces.
David and I (Miguel) began our journey into the world of data around the year 2017. Before that, we had been working on operational mission-critical solutions close to business processes and based on event-driven solutions. At that moment we found out about some of the tools such as Oozie or Airflow that were ETLs tools focused on scheduled tasks/workflow with no cloud solution offering, enterprise complex implementation and maintenance, poor scalability, and poor user experience.
Our first thought at that moment was these are the tools that we would have to be content with right now but that we would not use in the next years. Nowadays the data-driven approach has changed everything, every day the border between analytical and operational workloads is more diffuse than ever. There are many business-critical processes based on analytical and operational workloads. Probably many of these critical processes would be very similar to the non-critical data pipeline a few years ago. In 2020, Zhamak Dehghani published an article about the principles of data mesh, some of them quite well-known. She wrote one sentence particularly significant for us regarding operational and analytical planes: "I do believe that at some point in the future, our technologies will evolve to bring these two planes even closer together, but for now, I suggest we keep their concerns separate."
Our opinion is that these planes are closer than we think and in terms of business value, they are more achievable on a small scale than the logical architecture of data mesh itself. For instance, consider the fashion retail sector and critical processes such as allocation, e-commerce, or logistic solutions. All these processes that years ago were operational and many of them used traditional applications like SAP or Oracle, today, they need sophisticated data processes that include big data ingestion, transformation, analytics, and machine learning model to provide real-time recommendations and demand forecasts to allow data-driven decision-making.
Of course, traditional data pipelines/workflows are needed and traditional solutions based on isolated operational and analytics platforms will continue to provide value for some reports, batch analytical processes, experiments, and other analytical innovations. But today there are other kinds of data processes; business data processes that have different needs and provide more business value. We need data solutions that provide the following capabilities:
- Better software development experience and management of data as code applying all the best practices such as isolated environments, unit testing, A/B, data contracts, etc.
- Friendly and rich integration ecosystem not only with the big data world but with the data world in general.
- Cloud-based solutions that provide easy scalability, low maintenance, and easy integration with IAM solutions.
- Much better user experience not only for developers but also for data scientists, data analysts, business analysts, and operational teams
Introducing Dagster
Dagster is a platform for data flow orchestration that goes beyond what we understand as a data traditional orchestrator. The project was started in 2018 by Nick Shrock and was conceived as a result of a need identified by him while working at Facebook. One of the goals of Dagster has been to provide a tool that removes the barrier between pipeline development and pipeline operation, but during this journey, he came to link the world of data processing with business processes.
Dagster provides significant improvements over previous solutions.
- Oriented to data engineers, developers, and data/business operations engineers: Its versatility and abstraction allow us to design pipelines in a more developer-oriented way, applying software best practices and managing data, and data pipelines as code.
- Complies with the First-principles approach to data engineering, the full development lifecycle: development, deployment, monitoring, and observability
- It includes a new and differential concept, which is a software-defined asset. An asset is a data object or machine learning modeled in Dagster and persisted in a data repository.
- Dagit UI is a web-based interface for viewing and interacting with Dagster objects. A very intuitive, and user-friendly interface that allows a very simple operation.
- It is an open-source solution that at the same time offers a SaaS cloud solution that accelerates the implementation of the solution.
- A really fast learning curve that enables development teams to deliver value very early on
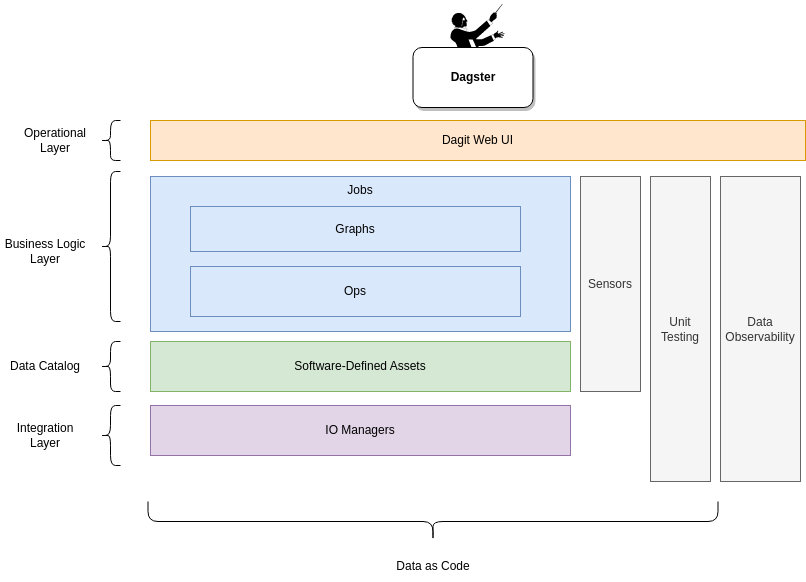
Let’s Talk a Little About the Dagster Concepts
We will explain basic concepts giving simple definitions, and examples that allow us to build a simple business data pipeline in the next article of this series.
Common Components of an Orchestrator
At a high level, these are the basic components of any orchestrator:
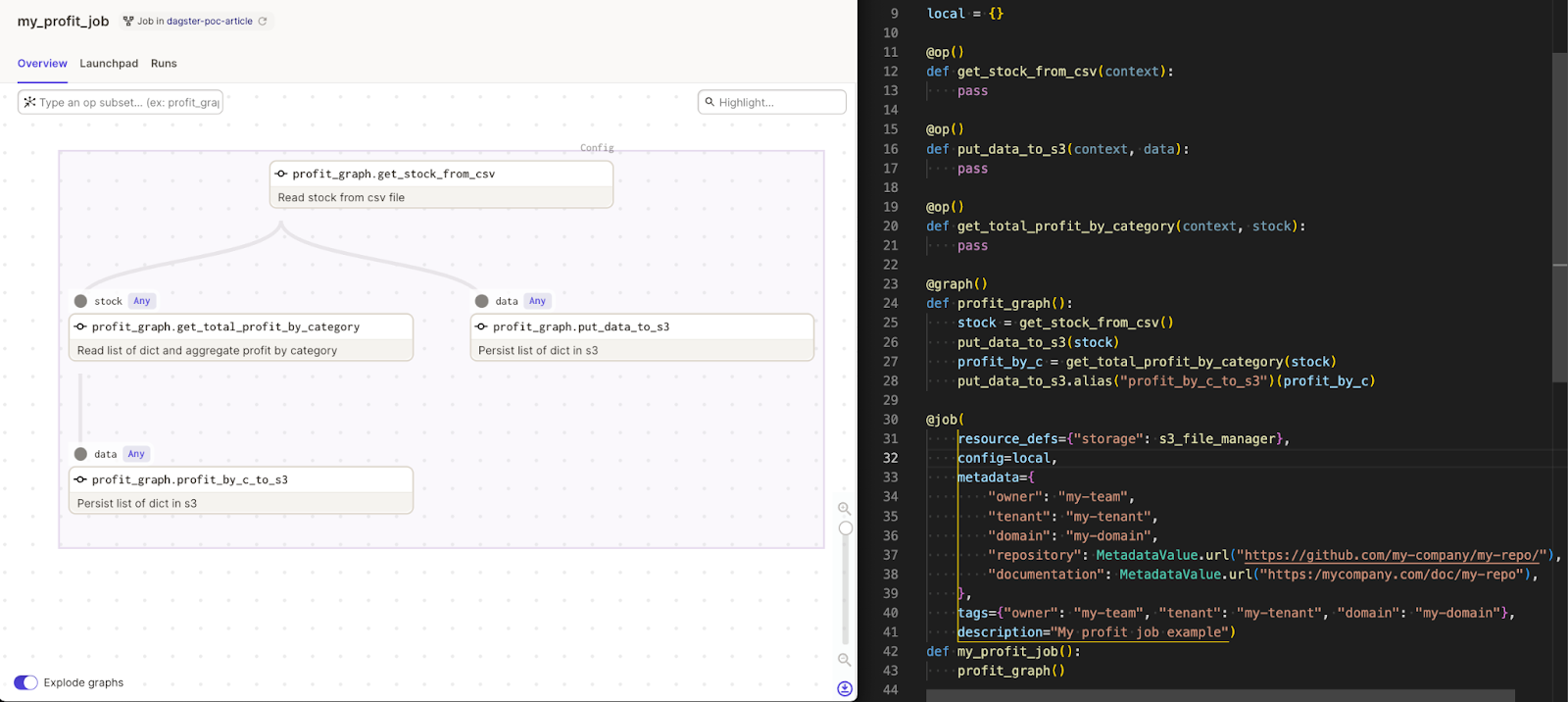
- Job: Main unit of execution and monitoring; instantiation of a Graph with configurations and parameters
- Ops: Basically, they are the tasks we want to execute, they contain the operations and should perform simple tasks such as executing a database query (to ingest or retrieve data), initiating a remote job (Spark, Python, etc.), or sending an event.
- Graph: Set of interconnected ops of sub-graphs, ops can be assembled into a graph to accomplish complex tasks
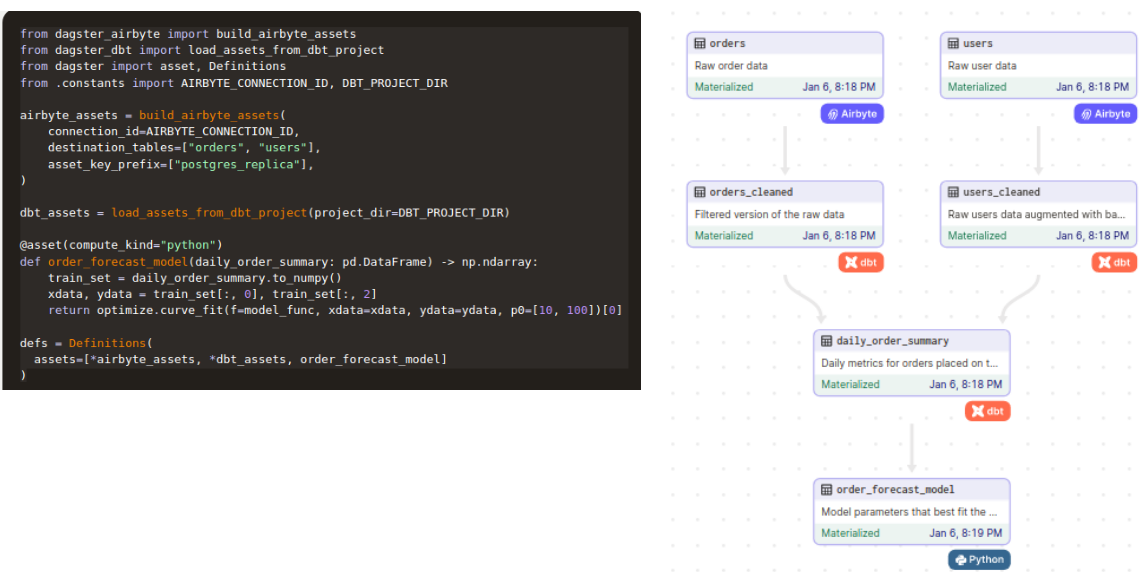
Software-Defined Assets
An asset is an object in persistent storage, such as a table, file, or persisted machine learning model. A software-defined asset is a Dagster object that couples an asset to the function and upstream assets used to produce its contents.
This is a declarative data definition, in Python, that allows us to:
- Define data contracts as code and how those will be used in our pipelines.
- Define the composition of our entity, regardless of its physical structure through a projection of the data.
- Decouple the business logic to compute assets from the I/O logic to read to and write from the persistent storage.
- Apply testing best practices including the ability to use mocks when we are writing a unit test.
- The ability to define partitions opens up a world of possibilities for running our processes and also at the time of re-launching. Sometimes we only have to reprocess a partition that for some reason has been processed incorrectly or incompletely.
An amazing capability is being able to use external tools such as DBT, Snowflake, Airbyte, Fivetran, and many others tools to define our assets. It is amazing because it allows us to be integrated into our global platform and not only in the big data ecosystem.
Options for Launching Jobs
In this case, the great differential is the capabilities that these sensors provide us with for:
- Schedules: It is used to execute a job at a fixed interval.
- Sensors: Allow us to run based on some external event such as Kafka event, new files in S3, specific asset materialization, or a data partition update.
- Partitions: Allow us to run based on changes in a subset of the data of an asset, for example, records in a data set that fall within a particular time window.
- Backfills: It provides the ability to re-execute the data pipeline on only the set of partitions we are interested in. For example, relaunch the pipeline that calculates the aggregation of store sales per country but only for the partition with the data of the USA stores.
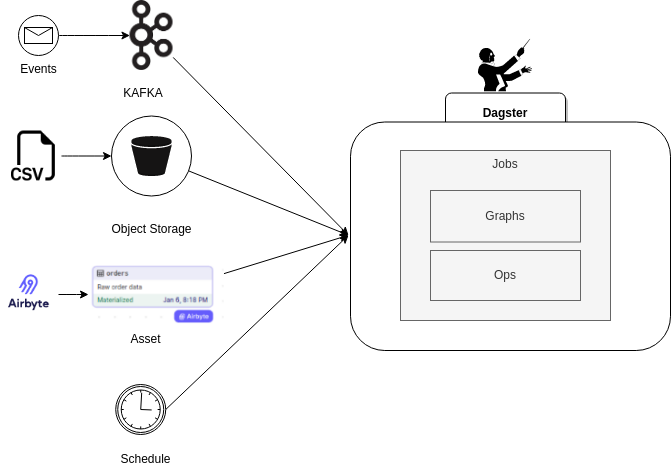
The combination of the capabilities offered by sensors, partitions, backfills, IO managers, and assets represents a very significant paradigm shift in the world of data pipeline orchestration.
IO Managers
It provides integration components with the persistent repositories that allow us to persist and load assets and Op outputs to/from S3, Snowflake, or other data repositories.
These components contain all the integration logic with each of the external channels we use in our architecture. We can use existing integrations, extend them to include specific logic, or develop new ones.
Lineage
The use of assets provides a base layer of lineage, data observability, and data quality monitoring. In our opinion, data lineage is a very complex and key aspect that nowadays goes beyond traditional tables and includes APIs, topics, and other data sources. This is why we believe that although Dagster provides great capabilities, it should be one more source in the overall lineage of our platform and not the source of truth.
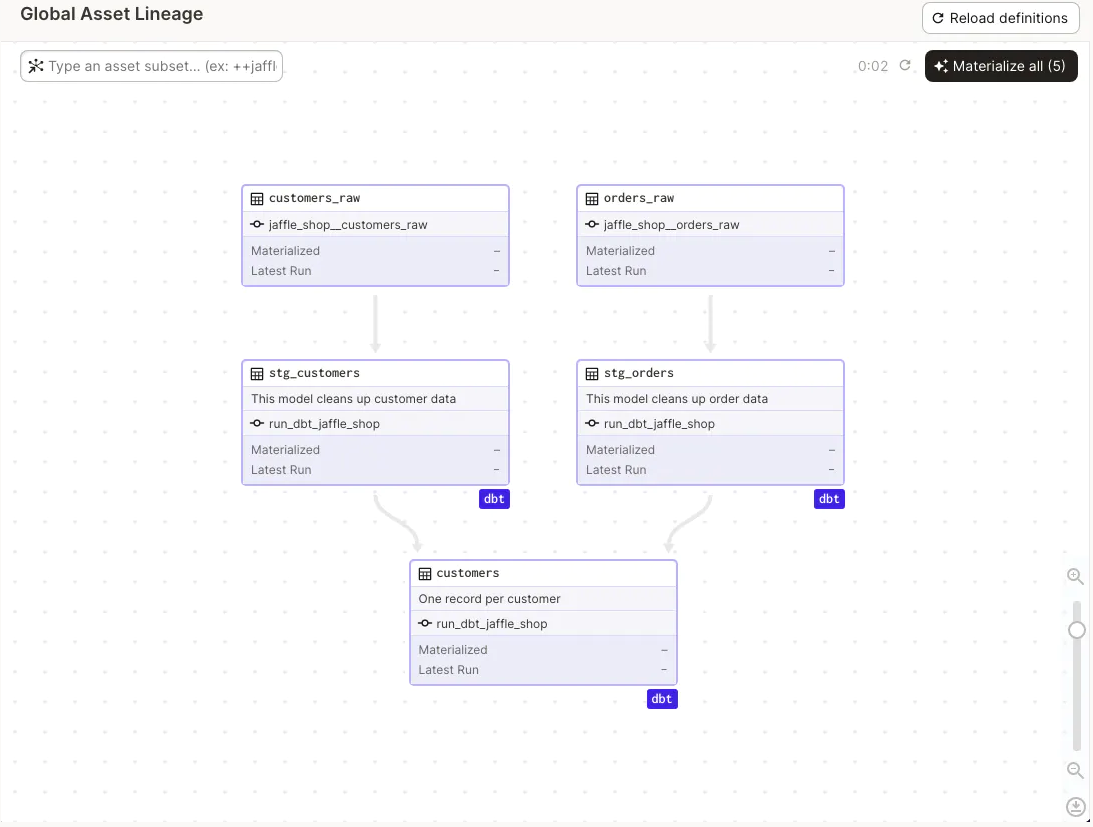
Debugging and Observability
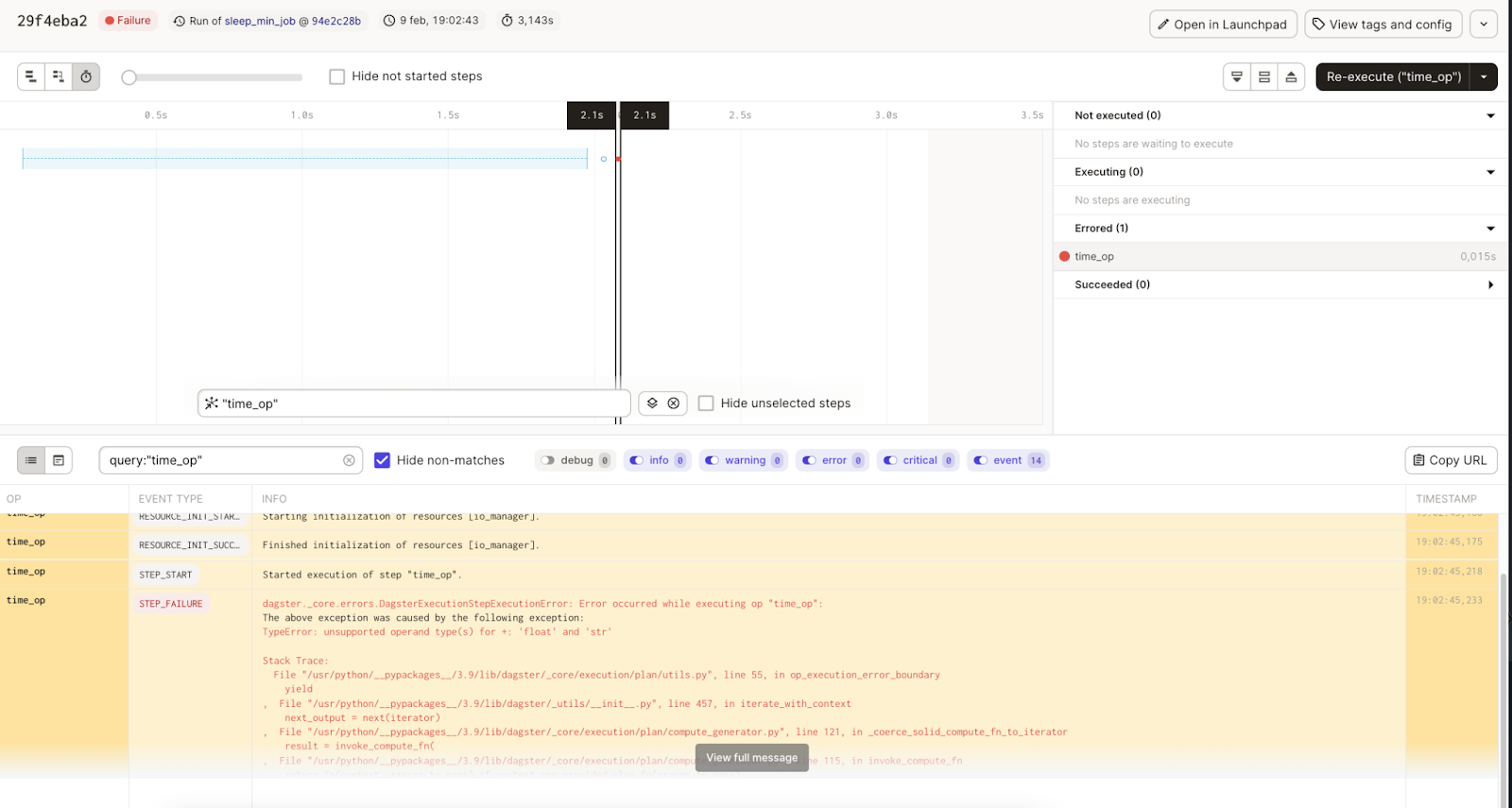
Another differentiating capability of Dagster is that it provides data observability when we are using software-definition assets. Data operators or data engineers have several features to analyze a data pipeline:
- Pipeline status, ops status, and timing
- Logs with error and info traces
- Assets can include metadata that displays information with the link to access the data materialization. It even provides us with the capability to send relevant information to different channels such as slack, events, or persistence in a report in S3.
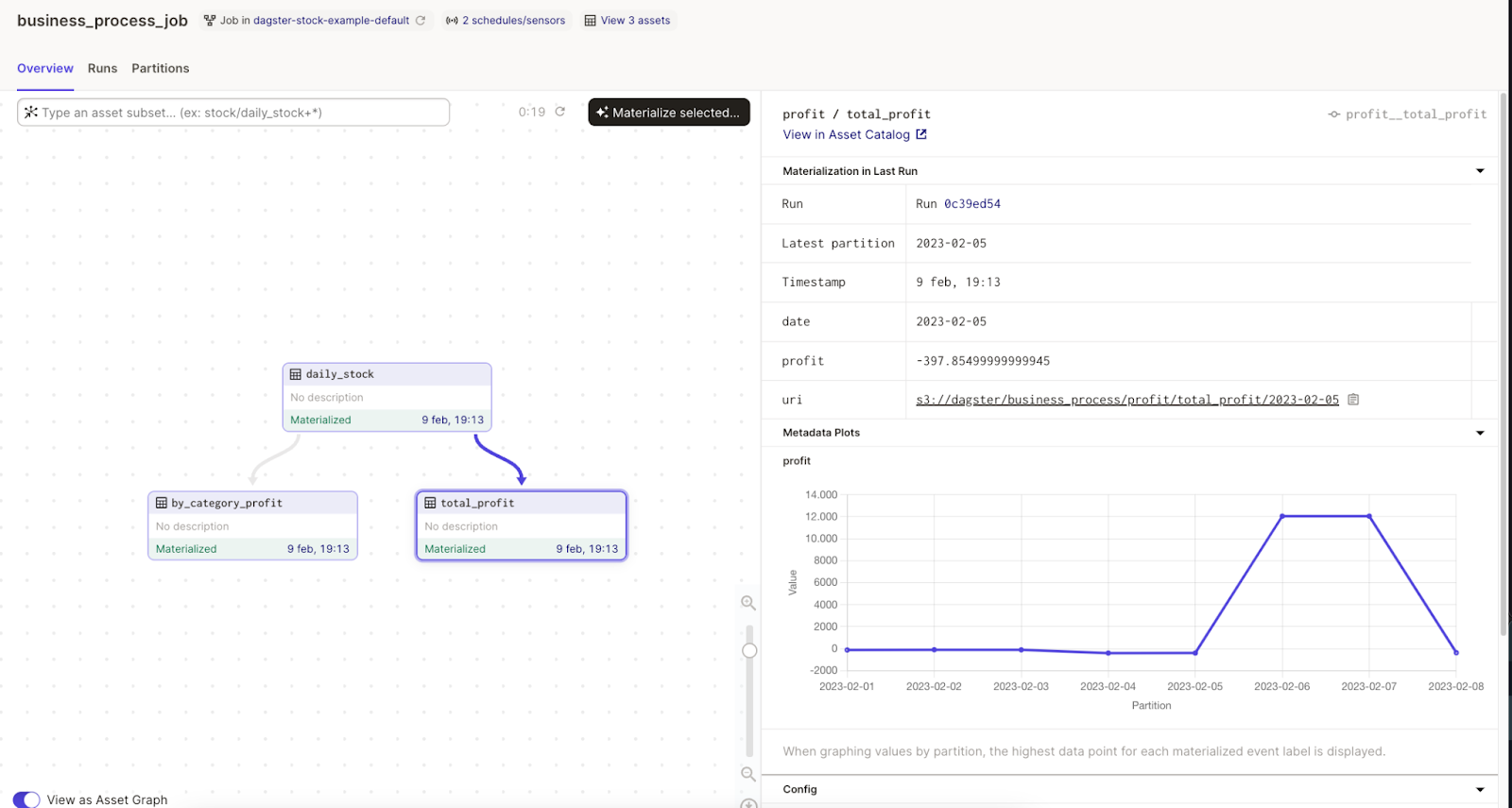
These capabilities allow engineers to have self-autonomy and not feel the orchestrator as a black box.
Metadata
Dagster allows meta-information to be added practically at all levels and most importantly it is very accessible by data ops or any other operational user. Having metadata is very important but it must also be usable and that is where Dagster makes a difference.
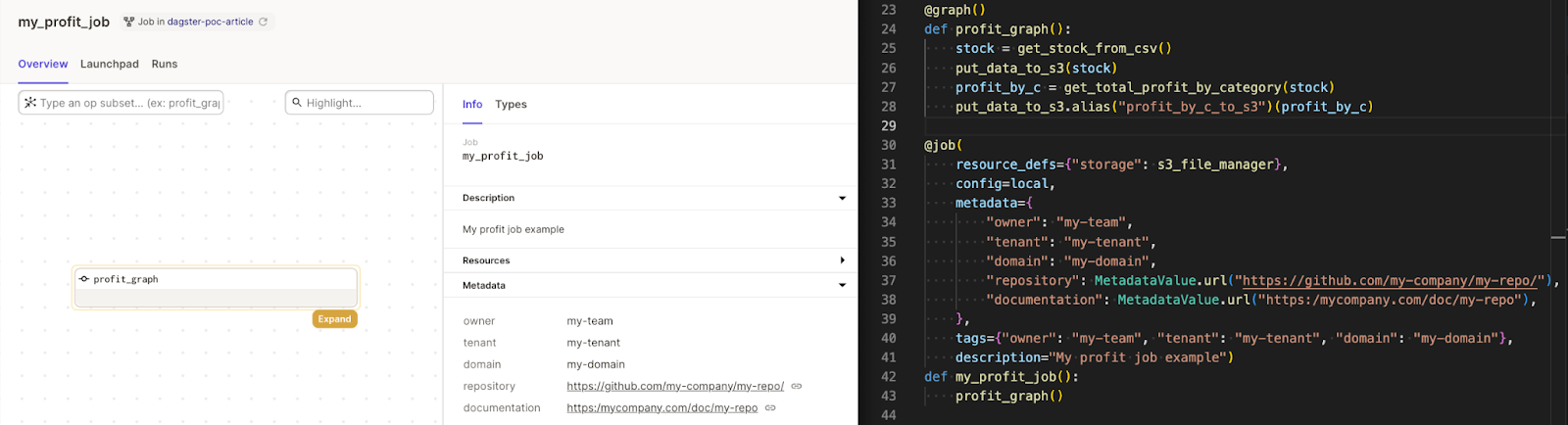
Operation teams have less process context and more cognitive changes because they do not participate in developments but at the same time manage multiple production flows. As soon as our data workflow becomes part of the business critical mission providing this meta-information is a must.
Dagster for Critical Business Process
Dagster allows us to have a data processing-oriented tool that we can integrate into our business processes in the critical path to provide the greatest business value. Let's think about stock replenishment retail processes from warehouses to the stores or other channels such as partners, or e-commerce. This is the process of replenishment of items from the distribution warehouses to the stores, the goal is that the right products are available in an optimal quantity and in the right place to meet the demand from customers.
- Improves the customer experience by ensuring that products are available across all channels and avoiding “out of stock."
- Increase profitability by avoiding replenishment of products with low sales probability.
- It is a business process where analytics and machine learning models have a lot of impacts. We can define this as a data-driven business process.
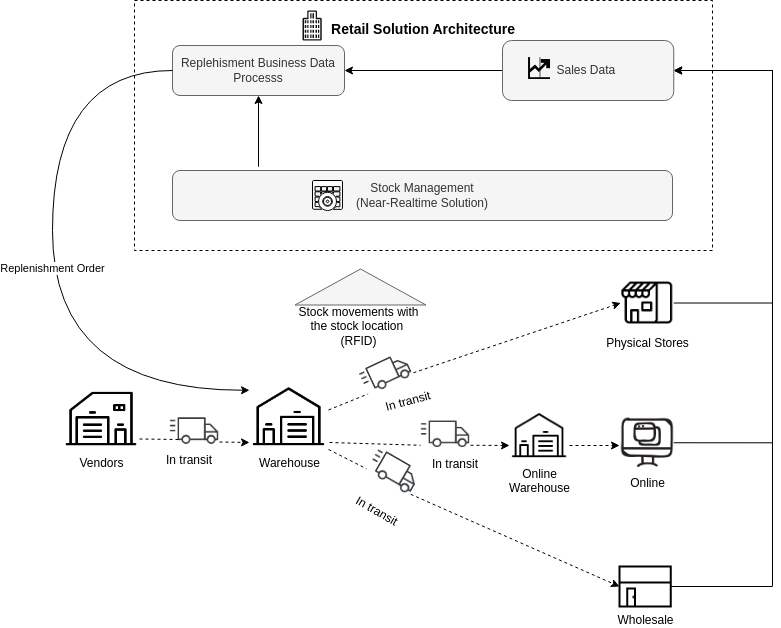
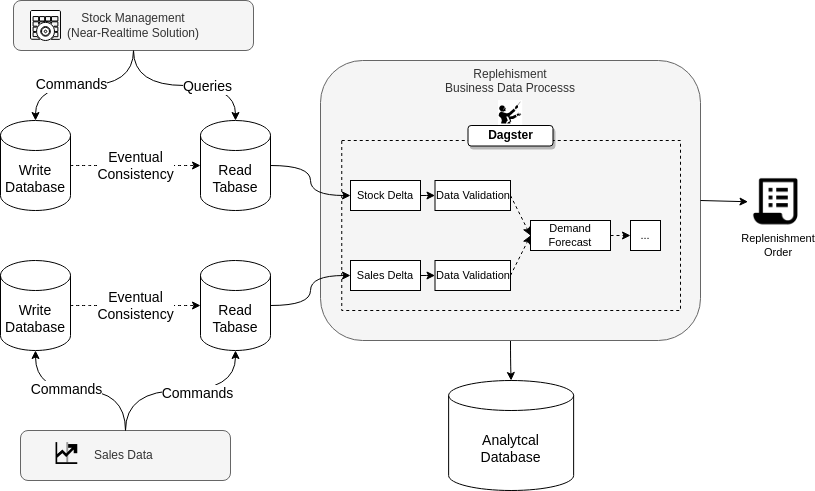
Stock replenishment is a complex operational business-critical process that has demand forecasting and stock inventory as its main pillars:
- Demand forecast requires an advanced machine-learning process based on historical data to project future demand.
- The stock inventory provides the quantity of stock available at each location such as stores, warehouses, distributors, etc.
- Sales provide information on how demand for the products is behaving based on indicators such as pricing, markdowns, etc.
- These processes can be launched weekly, daily, or several times a day depending on whether the replenishment is done from a central warehouse or, for example, a warehouse close to the physical stores.
This process requires some information updated in near real-time, but it is a data process that runs in batch or micro-batch mode. Dagster is the first data orchestrator that truly enables delivering business value from a purely operational point of view at the operational layer.
Dagster Common Use Cases
There are other more traditional use cases in Dagster such as:
- Data pipelines with different sources and as destinations for analytical systems such as Data Warehouses or Data Lakes
- Machine learning training model
- Analytical processes that integrate machine learning models
Of course, Dagster represents an evolution for this type of process for the same criteria as mentioned above.
Conclusions
As the next few years are expected to be really exciting in the world of data, we are evolving especially in the construction of tools that allow us to generate a more real and closer impact on the business. Dagster is another step in that direction.
The challenges are not new data architectures or complex analytical systems; the challenges are in providing real business value as soon as possible. The risks are to think that tools like Dagster and architectures like data mesh will bring value by themselves. These tools provide us with capabilities that we did not have years ago and allow us to design features that meet the needs of our customers.
We need to learn from the mistakes we have made, applying continuous improvement and a critical thinking approach to be better. Though there is no "one ring to rule them all," Dagster is a fantastic tool and great innovation, like other tools such as Dbt, Apache Kafka, DataHub Data Catalog, and many more, but if we believe that one tool can solve all our needs, we will build a new generation of monoliths.
Dagster, although a great product, is just another piece that complements our solutions to add value.
Opinions expressed by DZone contributors are their own.
Comments