CRUDing NoSQL Data With Quarkus, Part One: MongoDB
This article demonstrates how Quarkus, the supersonic, subatomic Java stack, greatly simplifies the NoSQL data persistence.
Join the DZone community and get the full member experience.
Join For FreeMongoDB is one of the most reliable and robust document-oriented NoSQL databases. It allows developers to provide feature-rich applications and services with various modern built-in functionalities, like machine learning, streaming, full-text search, etc. While not a classical relational database, MongoDB is nevertheless used by a wide range of different business sectors and its use cases cover all kinds of architecture scenarios and data types.
Document-oriented databases are inherently different from traditional relational ones where data are stored in tables and a single entity might be spread across several such tables. In contrast, document databases store data in separate unrelated collections, which eliminates the intrinsic heaviness of the relational model. However, given that the real world's domain models are never so simplistic to consist of unrelated separate entities, document databases (including MongoDB) provide several ways to define multi-collection connections similar to the classical databases relationships, but much lighter, more economical, and more efficient.
Quarkus, the "supersonic and subatomic" Java stack, is the new kid on the block that the most trendy and influential developers are desperately grabbing and fighting over. Its modern cloud-native facilities, as well as its contrivance (compliant with the best-of-the-breed standard libraries), together with its ability to build native executables have seduced Java developers, architects, engineers, and software designers for a couple of years.
We cannot go into further details here of either MongoDB or Quarkus: the reader interested in learning more is invited to check the documentation on the official MongoDB website or Quarkus website. What we are trying to achieve here is to implement a relatively complex use case consisting of CRUDing a customer-order-product domain model using Quarkus and its MongoDB extension. In an attempt to provide a real-world inspired solution, we're trying to avoid simplistic and caricatural examples based on a zero-connections single-entity model (there are dozens nowadays).
So, here we go!
The Domain Model
The diagram below shows our customer-order-product domain model: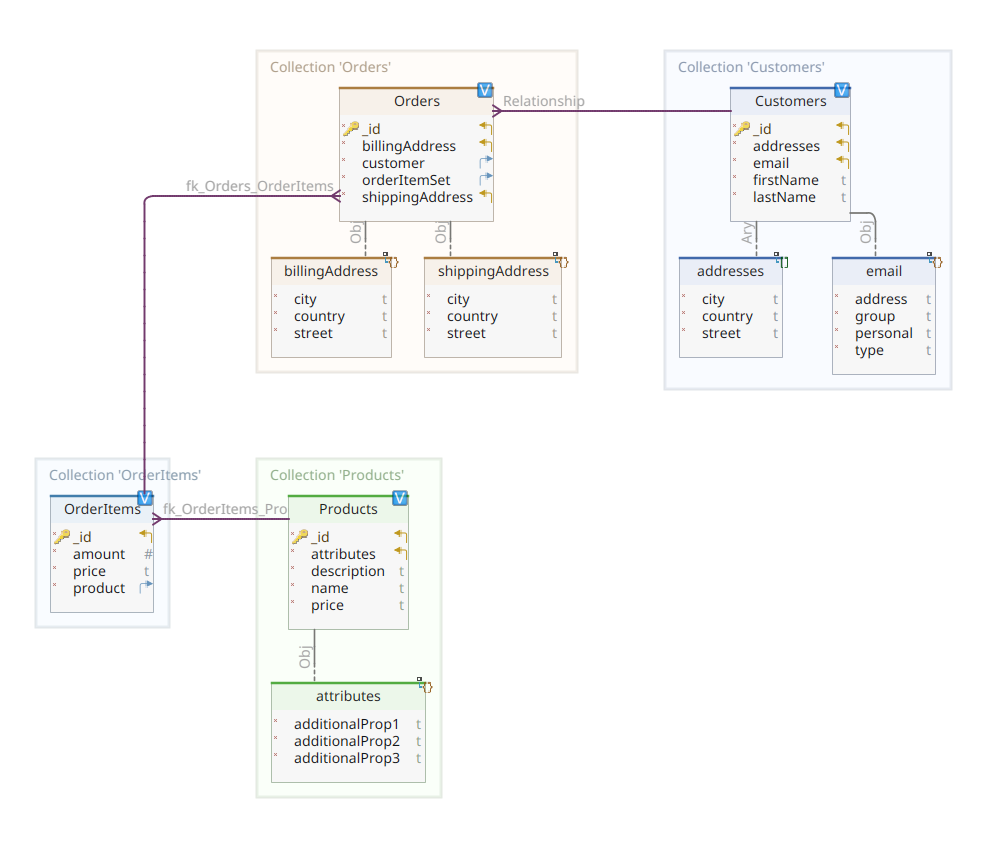
As you can see, the central document of the model is Order, stored in a dedicated collection named Orders. An Order is an aggregate of OrderItem documents, each of which points to its associated Product. An Order document also references the Customer who placed it. In Java, this is implemented as follows:
@MongoEntity(database = "mdb", collection="Customers")
public class Customer
{
@BsonId
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}The code above shows a fragment of the Customer class. This is a POJO (Plain Old Java Object) annotated with the @MongoEntity annotation, which parameters define the database name and the collection name. The @BsonId annotation is used in order to configure the document's unique identifier. While the most common use case is to implement the document's identifier as an instance of the ObjectID class, this would introduce a useless tidal coupling between the MongoDB-specific classes and our document. The other properties are the customer's first and last name, the email address, and a set of postal addresses.
Let's look now at the Order document.
@MongoEntity(database = "mdb", collection="Orders")
public class Order
{
@BsonId
private Long id;
private DBRef customer;
private Address shippingAddress;
private Address billingAddress;
private Set<DBRef> orderItemSet = new HashSet<>()
...
}Here we need to create an association between an order and the customer who placed it. We could have embedded the associated Customer document in our Order document, but this would have been a poor design because it would have redundantly defined the same object twice. We need to use a reference to the associated Customer document, and we do this using the DBRef class. The same thing happens for the set of the associated order items where, instead of embedding the documents, we use a set of references.
The rest of our domain model is quite similar and based on the same normalization ideas; for example, the OrderItem document:
@MongoEntity(database = "mdb", collection="OrderItems")
public class OrderItem
{
@BsonId
private Long id;
private DBRef product;
private BigDecimal price;
private int amount;
...
}We need to associate the product which makes the object of the current order item. Last but not least, we have the Product document:
@MongoEntity(database = "mdb", collection="Products")
public class Product
{
@BsonId
private Long id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}That's pretty much all as far as our domain model is concerned. There are, however, some additional packages that we need to look at: serializers and codecs.
In order to be able to be exchanged on the wire, all our objects, be they business or purely technical ones, have to be serialized and deserialized. These operations are the responsibility of specially designated components called serializers/deserializers. As we have seen, we're using the DBRef type in order to define the association between different collections. Like any other object, a DBRef instance should be able to be serialized/deserialized.
The MongoDB driver provides serializers/deserializers for the majority of the data types supposed to be used in the most common cases. However, for some reason, it doesn't provide serializers/deserializers for the DBRef type. Hence, we need to implement our own one, and this is what the serializers package does. Let's look at these classes:
public class DBRefSerializer extends StdSerializer<DBRef>
{
public DBRefSerializer()
{
this(null);
}
protected DBRefSerializer(Class<DBRef> dbrefClass)
{
super(dbrefClass);
}
@Override
public void serialize(DBRef dbRef, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException
{
if (dbRef != null)
{
jsonGenerator.writeStartObject();
jsonGenerator.writeStringField("id", (String)dbRef.getId());
jsonGenerator.writeStringField("collectionName", dbRef.getCollectionName());
jsonGenerator.writeStringField("databaseName", dbRef.getDatabaseName());
jsonGenerator.writeEndObject();
}
}
}This is our DBRef serializer and, as you can see, it's a Jackson serializer. This is because the quarkus-mongodb-panache extension that we're using here relies on Jackson. Perhaps, in a future release, JSON-B will be used but, for now, we're stuck with Jackson. It extends the StdSerializer class as usual and serializes its associated DBRef object by using the JSON generator, passed as an input argument, to write on the output stream the DBRef components; i.e., the object ID, the collection name, and the database name. For more information concerning the DBRef structure, please see the MongoDB documentation.
The deserializer is performing the complementary operation, as shown below:
public class DBRefDeserializer extends StdDeserializer<DBRef>
{
public DBRefDeserializer()
{
this(null);
}
public DBRefDeserializer(Class<DBRef> dbrefClass)
{
super(dbrefClass);
}
@Override
public DBRef deserialize(JsonParser jsonParser, DeserializationContext deserializationContext) throws IOException, JacksonException
{
JsonNode node = jsonParser.getCodec().readTree(jsonParser);
return new DBRef(node.findValue("databaseName").asText(), node.findValue("collectionName").asText(), node.findValue("id").asText());
}
}This is pretty much all that may be said as far as the serializers/deserializers are concerned. Let's move further to see what the codecs package brings to us.
Java objects are stored in a MongoDB database using the BSON (Binary JSON) format. In order to store information, the MongoDB driver needs the ability to map Java objects to their associated BSON representation. It does that on behalf of the Codec interface, which contains the required abstract methods for the mapping of the Java objects to BSON and the other way around. Implementing this interface, one can define the conversion logic between Java and BSON, and conversely. The MongoDB driver includes the required Codec implementation for the most common types but again, for some reason, when it comes to DBRef, this implementation is only a dummy one, which raises UnsupportedOperationException. Having contacted the MongoDB driver implementers, I didn't succeed in finding any other solution than implementing my own Codec mapper, as shown by the class DocstoreDBRefCodec. For brevity reasons, we won't reproduce this class' source code here.
Once our dedicated Codec is implemented, we need to register it with the MongoDB driver, such that it uses it when it comes to mapping DBRef types to Java objects and conversely. In order to do that, we need to implement the interface CoderProvider which, as shown by the class DocstoreDBRefCodecProvider, returns via its abstract get() method, the concrete class responsible for performing the mapping; i.e., in our case, DocstoreDBRefCodec. And that's all we need to do here as Quarkus will automatically discover and use our CodecProvider customized implementation. Please have a look at these classes to see and understand how things are done.
The Data Repositories
Quarkus Panache greatly simplifies the data persistence process by supporting both the active record and the repository design patterns. Here, we'll be using the second one.
As opposed to similar persistence stacks, Panache relies on the compile-time bytecode enhancements of the entities. It includes an annotation processor that automatically performs these enhancements. All that this annotation processor needs in order to perform its enhancements job is an interface like the one below:
@ApplicationScoped
public class CustomerRepository implements PanacheMongoRepositoryBase<Customer, Long>{}The code above is all that you need in order to define a complete service able to persist Customer document instances. Your interface needs to extend the PanacheMongoRepositoryBase one and parameter it with your object ID type, in our case a Long. The Panache annotation processor will generate all the required endpoints required to perform the most common CRUD operations, including but not limited to saving, updating, deleting, querying, paging, sorting, transaction handling, etc. All these details are fully explained here. Another possibility is to extend PanacheMongoRepository instead of PanacheMongoRepositoryBase and to use the provided ObjectID keys instead of customizing them as Long, as we did in our example. Whether you chose the 1st or the 2nd alternative, this is only a preference matter.
The REST API
In order for our Panache-generated persistence service to become effective, we need to expose it through a REST API. In the most common case, we have to manually craft this API, together with its implementation, consisting of the full set of the required REST endpoints. This fastidious and repetitive operation might be avoided by using the quarkus-mongodb-rest-data-panache extension, which annotation processor is able to automatically generate the required REST endpoints, out of interfaces having the following pattern:
public interface CustomerResource
extends PanacheMongoRepositoryResource<CustomerRepository, Customer, Long> {}Believe it if you want: this is all you need to generate a full REST API implementation with all the endpoints required to invoke the persistence service generated previously by the mongodb-panache extension annotation processor. Now we are ready to build our REST API as a Quarkus microservice. We chose to build this microservice as a Docker image, on behalf of the quarkus-container-image-jib extension. By simply including the following Maven dependency:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-container-image-jib</artifactId>
</dependency>The quarkus-maven-plugin will create a local Docker image to run our microservice. The parameters of this Docker image are defined by the application.properties file, as follows:
quarkus.container-image.build=true
quarkus.container-image.group=quarkus-nosql-tests
quarkus.container-image.name=docstore-mongodb
quarkus.mongodb.connection-string = mongodb://admin:admin@mongo:27017
quarkus.mongodb.database = mdb
quarkus.swagger-ui.always-include=true
quarkus.jib.jvm-entrypoint=/opt/jboss/container/java/run/run-java.shHere we define the name of the newly created Docker image as being quarkus-nosql-tests/docstore-mongodb. This is the concatenation of the parameters quarkus.container-image.group and quarkus.container-image.name separated by a "/". The property quarkus.container-image.build having the value true instructs the Quarkus plugin to bind the build operation to the package phase of maven. This way, simply executing a mvn package command, we generate a Docker image able to run our microservice. This may be tested by running the docker images command. The property named quarkus.jib.jvm-entrypoint defines the command to be run by the newly generated Docker image. quarkus-run.jar is the Quarkus microservice standard startup file used when the base image is ubi8/openjdk-17-runtime, as in our case. Other properties are quarkus.mongodb.connection-string and quarkus.mongodb.database = mdb which define the MongoDB database connection string and the name of the database. Last but not least, the property quarkus.swagger-ui.always-include includes the Swagger UI interface in our microservice space such that it allows us to test it easily.
Let's see now how to run and test the whole thing.
Running and Testing Our Microservices
Now that we looked at the details of our implementation, let's see how to run and test it. We chose to do it on behalf of the docker-compose utility. Here is the associated docker-compose.yml file:
version: "3.7"
services:
mongo:
image: mongo
environment:
MONGO_INITDB_ROOT_USERNAME: admin
MONGO_INITDB_ROOT_PASSWORD: admin
MONGO_INITDB_DATABASE: mdb
hostname: mongo
container_name: mongo
ports:
- "27017:27017"
volumes:
- ./mongo-init/:/docker-entrypoint-initdb.d/:ro
mongo-express:
image: mongo-express
depends_on:
- mongo
hostname: mongo-express
container_name: mongo-express
links:
- mongo:mongo
ports:
- 8081:8081
environment:
ME_CONFIG_MONGODB_ADMINUSERNAME: admin
ME_CONFIG_MONGODB_ADMINPASSWORD: admin
ME_CONFIG_MONGODB_URL: mongodb://admin:admin@mongo:27017/
docstore:
image: quarkus-nosql-tests/docstore-mongodb:1.0-SNAPSHOT
depends_on:
- mongo
- mongo-express
hostname: docstore
container_name: docstore
links:
- mongo:mongo
- mongo-express:mongo-express
ports:
- "8080:8080"
- "5005:5005"
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jarThis file instructs the docker-compose utility to run three services:
- A service named
mongorunning the Mongo DB 7 database - A service named
mongo-expressrunning the MongoDB administrative UI - A service named
docstorerunning our Quarkus microservice
We should note that the mongo service uses an initialization script mounted on the docker-entrypoint-initdb.d directory of the container. This initialization script creates the MongoDB database named mdb such that it could be used by the microservices.
db = db.getSiblingDB(process.env.MONGO_INITDB_ROOT_USERNAME);
db.auth(
process.env.MONGO_INITDB_ROOT_USERNAME,
process.env.MONGO_INITDB_ROOT_PASSWORD,
);
db = db.getSiblingDB(process.env.MONGO_INITDB_DATABASE);
db.createUser(
{
user: "nicolas",
pwd: "password1",
roles: [
{
role: "dbOwner",
db: "mdb"
}]
});
db.createCollection("Customers");
db.createCollection("Products");
db.createCollection("Orders");
db.createCollection("OrderItems");This is an initialization JavaScript that creates a user named nicolas and a new database named mdb. The user has administrative privileges on the database. Four new collections, respectively named Customers, Products, Orders and OrderItems, are created as well.
In order to test the microservices, proceed as follows:
- Clone the associated GitHub repository:
$ git clone https://github.com/nicolasduminil/docstore.git
- Go to the project:
$ cd docstore
- Build the project:
$ mvn clean install
- Check that all the required Docker containers are running:
$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7882102d404d quarkus-nosql-tests/docstore-mongodb:1.0-SNAPSHOT "/opt/jboss/containe…" 8 seconds ago Up 6 seconds 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore 786fa4fd39d6 mongo-express "/sbin/tini -- /dock…" 8 seconds ago Up 7 seconds 0.0.0.0:8081->8081/tcp, :::8081->8081/tcp mongo-express 2e850e3233dd mongo "docker-entrypoint.s…" 9 seconds ago Up 7 seconds 0.0.0.0:27017->27017/tcp, :::27017->27017/tcp mongo
- Run the integration tests:
$ mvn -DskipTests=false failsafe:integration-test
This last command will run all the integration tests which should succeed. These integration tests are implemented using the RESTassured library. The listing below shows one of these integration tests located in the docstore-domain project:
@QuarkusIntegrationTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
public class CustomerResourceIT
{
private static Customer customer;
@BeforeAll
public static void beforeAll() throws AddressException
{
customer = new Customer("John", "Doe", new InternetAddress("john.doe@gmail.com"));
customer.addAddress(new Address("Gebhard-Gerber-Allee 8", "Kornwestheim", "Germany"));
customer.setId(10L);
}
@Test
@Order(10)
public void testCreateCustomerShouldSucceed()
{
given()
.header("Content-type", "application/json")
.and().body(customer)
.when().post("/customer")
.then()
.statusCode(HttpStatus.SC_CREATED);
}
@Test
@Order(20)
public void testGetCustomerShouldSucceed()
{
assertThat (given()
.header("Content-type", "application/json")
.when().get("/customer")
.then()
.statusCode(HttpStatus.SC_OK)
.extract().body().jsonPath().getString("firstName[0]")).isEqualTo("John");
}
@Test
@Order(30)
public void testUpdateCustomerShouldSucceed()
{
customer.setFirstName("Jane");
given()
.header("Content-type", "application/json")
.and().body(customer)
.when().pathParam("id", customer.getId()).put("/customer/{id}")
.then()
.statusCode(HttpStatus.SC_NO_CONTENT);
}
@Test
@Order(40)
public void testGetSingleCustomerShouldSucceed()
{
assertThat (given()
.header("Content-type", "application/json")
.when().pathParam("id", customer.getId()).get("/customer/{id}")
.then()
.statusCode(HttpStatus.SC_OK)
.extract().body().jsonPath().getString("firstName")).isEqualTo("Jane");
}
@Test
@Order(50)
public void testDeleteCustomerShouldSucceed()
{
given()
.header("Content-type", "application/json")
.when().pathParam("id", customer.getId()).delete("/customer/{id}")
.then()
.statusCode(HttpStatus.SC_NO_CONTENT);
}
@Test
@Order(60)
public void testGetSingleCustomerShouldFail()
{
given()
.header("Content-type", "application/json")
.when().pathParam("id", customer.getId()).get("/customer/{id}")
.then()
.statusCode(HttpStatus.SC_NOT_FOUND);
}
}You can also use the Swagger UI interface for testing purposes by firing your preferred browser at http://localhost:8080/q:swagger-ui. Then, in order to test endpoints, you can use the payloads in the JSON files located in the src/resources/data directory of the docstore-api project.
You also can use the MongoDB UI administrative interface by going to http://localhost:8081 and authenticating yourself with the default credentials (admin/pass).
You can find the project source code in my GitHub repository.
Enjoy!
Opinions expressed by DZone contributors are their own.
Comments