Crafting GraphQL APIs With AWS Neptune
In this article, we will explore AWS Neptune and GraphQL and build a practical knowledge graph, shedding light on their significance in modern data management.
Join the DZone community and get the full member experience.
Join For FreeIn recent years, graph databases like AWS Neptune have witnessed a surge in popularity, reflecting a growing interest in more dynamic data management solutions. Parallel to this, GraphQL has carved out its niche as a preferred query language for APIs, known for its efficiency and flexibility. This article is designed to provide a deep dive into the world of AWS Neptune and GraphQL. We will explore AWS Neptune and understand GraphQL in a practical way.
Knowledge Graph and Graph Databases
A knowledge graph represents a network of real-world entities (objects, concepts, etc.) and shows the relationships between them. Knowledge graphs are created from formal ontologies that define the entities and relationships in the graph. Ontologies are the backbone of a knowledge graph because they define the data schema of the graph. In simple words:
Knowledge Graph = Ontology + Data
Knowledge graphs are very important because they can be used to interpret the data and infer new facts. The most common examples of knowledge graphs are Google Knowledge Graph, DBpedia, Wikidata, WordNet, etc.
Knowledge graphs are usually stored in graph databases where graph data can be explored via structured queries. Graph databases are designed to treat relationships between the data as equally important to the data itself. They are optimized to answer questions about the relationships and address complex problems involving modern data that involve too many relationships with heterogeneous data. Graph databases are categorized based on their underlying graph data models:
- Resource Description Framework (RDF) Graphs: RDF is a World Wide Web Consortium (S3c) standard originally designed as a data model for metadata. RDF data model is similar to conceptual modeling approaches like ER or class diagrams. It uses subject-object-predicate expressions, known as triplets, to express information. For example: “David plays basketball” – here David is the subject, plays is a predicate, and basketball is an object. RDF is a standardized model where every element has a Uniform Resource Identifier (URI) that allows machines to uniquely identify subjects, objects, and predicates.
- Labeled Property Graphs (LPG): LPG or Property Graphs is a graph database consisting of nodes and relationships, and each node and relationship can have a set of attributes (key-value pairs). For example: “David plays basketball” – here, David and basketball are both nodes and playing is a relationship between them. Here, any nodes or relationships can have associated attributes (ex, David's associated attribute could be Height, and basketball’s associated attribute could be its model or brand). Property graphs do not have a standard representation or querying capabilities. However, openCypher is the widely adopted query language for property graphs.
While both LPG and RDF graphs provide several benefits, they also have certain limitations. So, selecting the right graph model depends on the exact requirements and use cases. For the example in this tutorial, we will use an LPG graph because of its simplicity.
GraphQL and Graph Databases
GraphQL is an open-source data query and manipulation language for APIs. With GraphQL query, the client can request only the minimum data required to satisfy current needs. It is a REST API alternative with a structured query language. GraphQL APIs consist of schema, query, and resolver functions (a functional that is responsible for populating the data for a single field in your schema)
While REST APIs could be used for knowledge graphs, GraphQL APIs provide a natural way to align ontology models with GraphQL schema. Adding GraphQL interfaces makes it easier to express underlying knowledge graph data models. Additionally, GraphQL is simple, declarative, and powerful. Therefore, GraphQL is a great option for building APIs for knowledge graphs.
Demo Project
In this guide, we'll delve into using GraphQL APIs for a sample social network knowledge graph in the AWS environment. Our model will include 'User' and 'Skill' nodes. There will be a 'Has_Skill' relationship, indicating that a user possesses a specific skill, such as Java. Additionally, we'll explore the 'Is_Friends_With' relationship, connecting two users as friends.
We will use the following GraphQL schema to represent our data model and APIs.\
type Skill {
id: ID!
name: String!
}
type User {
id: ID!
name: String!
friends: [User]
skills: [Skill]
}
type Mutation {
createSkill(name: String!): Skill
createUser(name: String!, skillName: String!): User
addFriend(userName: String!, friendName: String!): User
}
# Queries and mutations
type Query {
getUser(userName: String!): User
}In our project, we'll utilize AWS Neptune, a cloud-optimized, fully managed graph database service, to create our graph database. For constructing our GraphQL APIs, AWS AppSync and AWS Lambda will be our tools of choice. Finally, within our Lambda functions, we'll employ Gremlin to query the AWS Neptune graph.
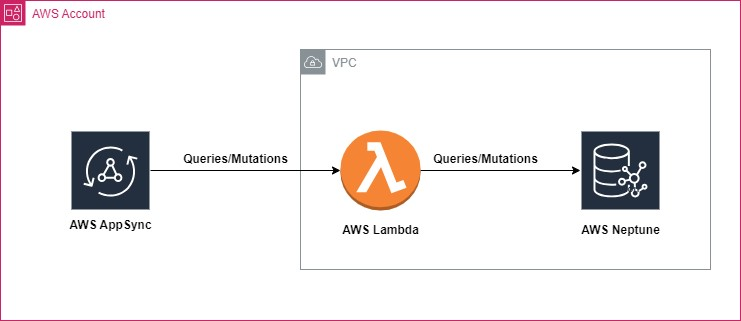
Prerequisites
- An active AWS Account.
- AWS CLI is installed and configured on your computer.
- Selecting the AWS Region — for this tutorial, we'll work with 'us-west-2'.
- Setup two IAM roles
- A Lambda Role for querying AWS Neptune.
- An AppSync Role to enable AWS Lambda invocation.
Infrastructure Setup
Let's begin by setting up an AWS Neptune Cluster with a writer instance. We'll choose the 'db.t3.medium' instance type since it's part of the AWS free tier and should suffice for our prototype.
$ aws neptune create-db-cluster --db-cluster-identifier NeptuneGraphQLCluster \
--engine neptune --engine-version 1.2.1.0 --region us-west-2Here NeptuneGraphQLCluster is the name of the cluster. Cluster creation typically takes a few minutes. Once it's ready, we'll proceed to set up a writer instance within this cluster.
$ aws neptune create-db-instance --db-instance-identifier NeptuneGraphQLClusterWriter \
--db-instance-class db.t3.medium \
--engine neptune --db-cluster-identifier NeptuneGraphQLCluster --region us-west-2Here NeptuneGraphQLClusterWriter is the instance identifier. Typically, it takes a few minutes for the writer's instance to be fully set up and operational.
Now, we will move on to AWS AppSync to build out our GraphQL APIs.
$ aws appsync create-graphql-api --name NeptuneGraphQLAPIs \
--authentication-type API_KEY --region us-west-2create-graphql-api provides api-id as part of the response. We will use that api-id for other CLI commands as part of this tutorial.
We'll save the GraphQL schema discussed previously into a temporary file, for example, '/tmp/schema.graphql'. This file will be used to establish the schema in AWS AppSync.
$ aws appsync start-schema-creation --api-id <API_ID> \
--definition file:///tmp/schema.graphql --region us-west-2Here API_ID comes from the previous create-graphql-api response.
We're now going to set up an S3 bucket to store the Lambda function's artifacts.
$ aws s3api create-bucket --bucket <BUCKET_NAME> --region us-west-2 \
--create-bucket-configuration LocationConstraint=us-west-2Next, we'll proceed with the creation of the AWS Lambda function.
$ aws lambda create-function \
--region us-west-2 \
--function-name NeptuneGraphQLAPILambda \
--timeout 900 \
--runtime python3.11 \
--handler "main.lambda_handler" \
--package-type "Zip" \
--role <Lambda_Role_ARN> \
--code S3Bucket=<BUCKET_NAME>,S3Key=<ZIP_ARTIFACT> \
--vpc-config SubnetIds=<SUBNET_IDS>,SecurityGroupIds=<SG_IDS>In the above API call, you must supply the ARN of an existing Lambda Role. This role should already have permissions for Neptune, along with the standard Lambda permissions. You'll also need to specify the S3 Bucket name and the zip artifact (the creation of which is outlined in the following section). Finally, ensure to provide the same subnet IDs and security group IDs that are associated with your Neptune Writer instance.
After creating the Lambda, we'll complete the AWS AppSync setup by linking the GraphQL APIs to the Lambda resolver. To do this, use the following API, which requires an AppSync role with permissions to invoke Lambda functions. You can configure this role as explained in this.
Additionally, in the upcoming commands, we'll employ the following request mapping template for our resolvers. This template aids in forwarding arguments to our Lambda resolver. You can find more detailed information about this request mapping template here.
{
"version" : "2017-02-28",
"operation": "Invoke",
"payload": {
"api": $utils.toJson($context.info.fieldName),
"arguments": $utils.toJson($context.arguments)
}
}$ aws appsync create-data-source --api-id <API_ID> --name NeptuneLambdaDataSource --type AWS_LAMBDA \
--lambda-config "lambdaFunctionArn=<Lambda_ARN>" \
--service-role-arn <AppSyncRole-ARN> –-region us-west-2$ aws appsync create-resolver --api-id <API_ID> --type-name "Query" --field-name "getUser" --data-source-name NeptuneLambdaDataSource \
--request-mapping-template <REQUEST_MAPPING_FILE_PATH> –-region us-west-2$ aws appsync create-resolver --api-id <API_ID> --type-name "Mutation" --field-name "createUser" \
--data-source-name NeptuneLambdaDataSource --request-mapping-template <REQUEST_MAPPING_FILE_PATH> –-region us-west-2
$ aws appsync create-resolver --api-id <API_ID> --type-name "Mutation" --field-name "createSkill" \
--data-source-name NeptuneLambdaDataSource --request-mapping-template <REQUEST_MAPPING_FILE_PATH> –-region us-west-2
$ aws appsync create-resolver --api-id <API_ID> --type-name "Mutation" --field-name "addFriend" \
--data-source-name NeptuneLambdaDataSource --request-mapping-template <REQUEST_MAPPING_FILE_PATH> –-region us-west-2$ aws appsync create-api-key --api-id <API_ID> --region us-west-2Lambda Resolver
Next, we're going to craft the main.py file, which will encompass all our API functions, including mutations and queries. This Lambda function will utilize the gremlinpython library to execute Gremlin queries on our Neptune cluster. Remember to incorporate the Neptune Writer URL (NEPTUNE_WRITER_URL) from your Neptune cluster into the code below.
from gremlin_python import statics
from gremlin_python.structure.graph import Graph
from gremlin_python.process.graph_traversal import __
from gremlin_python.process.strategies import *
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
from gremlin_python.driver.aiohttp.transport import AiohttpTransport
from gremlin_python.process.traversal import T
import hashlib
def generate_hash(value):
h = hashlib.new('sha256')
h.update(value.encode())
return h.hexdigest()
def create_user(g, arguments):
user_id = generate_hash(arguments['name'])
skill_name = arguments['skillName']
skill_id = generate_hash(skill_name)
g.addV('User').property(T.id, user_id).property('name', arguments['name']).next()
g.addE('Has_Skill').from_(__.V(user_id)).to(__.V(skill_id)).next()
user_dict = g.V(user_id).valueMap().toList()[0]
skill_dict = g.V(skill_id).valueMap().toList()[0]
user_dict['id'] = user_id
user_dict['skills'] = [skill_dict]
return user_dict
def create_skill(g, arguments):
skill_id = generate_hash(arguments['name'])
g.addV('Skill').property(T.id, skill_id).property('name', arguments['name']).next()
skill_dict = g.V(skill_id).valueMap().toList()[0]
skill_dict['id'] = skill_id
return skill_dict
def add_friend(g, arguments):
user_id = generate_hash(arguments['userName'])
friend_id = generate_hash(arguments['friendName'])
g.addE('Is_Friends_With').from_(__.V(user_id)).to(__.V(friend_id)).next()
g.addE('Is_Friends_With').from_(__.V(friend_id)).to(__.V(user_id)).next()
user_dict = g.V(user_id).valueMap().toList()[0]
skill_list = g.V(user_id).outE('Has_Skill').inV().valueMap().toList()
friends_list = g.V(user_id).outE('Is_Friends_With').inV().valueMap().toList()
user_dict['id'] = user_id
user_dict['skills'] = skill_list
user_dict['friends'] = friends_list
return user_dict
def get_user(g, arguments):
user_id = generate_hash(arguments['userName'])
user_dict = g.V(user_id).valueMap().toList()[0]
skill_list = g.V(user_id).outE('Has_Skill').inV().valueMap().toList()
friends_list = g.V(user_id).outE('Is_Friends_With').inV().valueMap().toList()
user_dict['id'] = user_id
user_dict['skills'] = skill_list
user_dict['friends'] = friends_list
return user_dict
def lambda_handler(event, context):
g = Graph()
remote_conn = DriverRemoteConnection('wss://<NEPTUNE_WRITER_URL>:8182/gremlin', 'g', transport_factory=lambda:AiohttpTransport(call_from_event_loop=True))
g = g.traversal().withRemote(remote_conn)
print("Successfully connected to Neptune")
api_name = event['api']
if api_name == 'createUser':
return create_user(g, event['arguments'])
elif api_name == 'createSkill':
return create_skill(g, event['arguments'])
elif api_name == 'addFriend':
return add_friend(g, event['arguments'])
elif api_name == 'getUser':
return get_user(g, event['arguments'])
else:
return "{}"Important things to note here are:
- We use Gremlin to execute queries and mutations on AWS Neptune.
- Vertices and Edges are structured according to our data model discussed previously.
- In this tutorial, all APIs are consolidated in a single Lambda function. For a production environment, it may be more efficient to dedicate a separate Lambda for each API.
- This Lambda function is designed to demonstrate the optimal scenario ('happy path') for each API and does not account for edge cases.
Now, we will package the Lambda function and its dependencies by following the AWS tutorial. After the ZIP file is created, we will upload it to the S3 bucket we created earlier.
$ aws s3api put-object --bucket <BUCKET_NAME> --key deployment.zip --body my_deployment_package.zip –-region us-west-2Once the ZIP file is uploaded, we will trigger the Lambda deployment
Testing
Once the deployment is complete, you can test out the GraphQL mutations and queries in the AWS AppSync Console (under the API à Queries section). Some of the example requests and responses are below:
CreateSkill API

Request
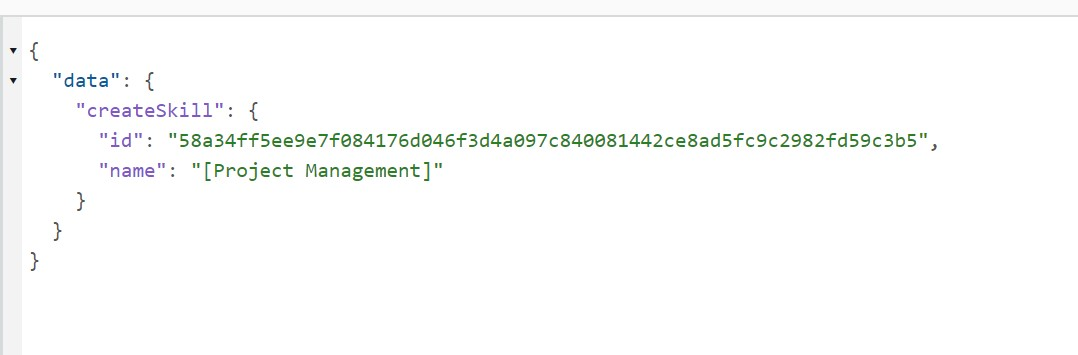
Response
Create User API

Request

Response
AddFriend API

Request

Response
GetUser API

Request 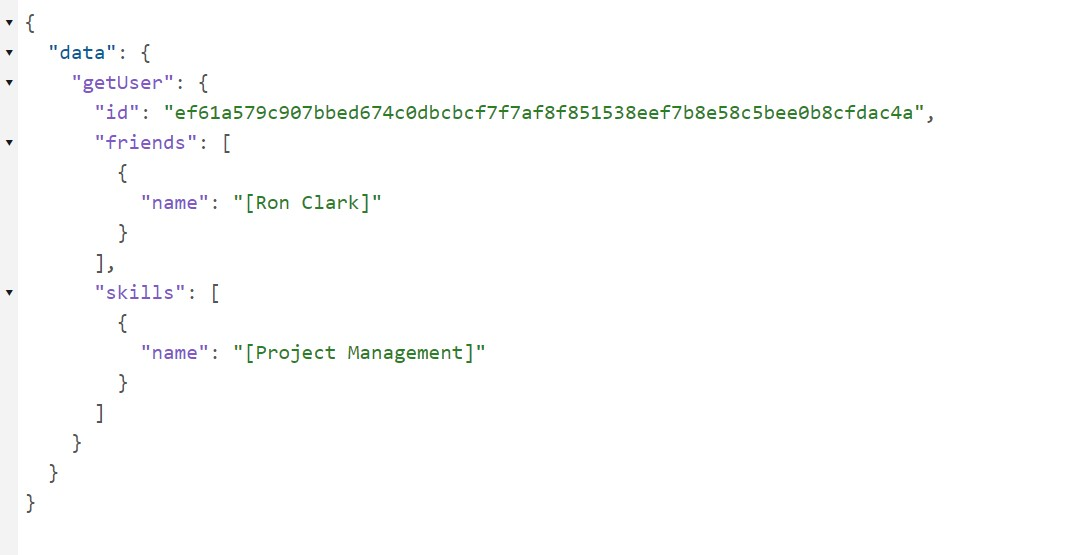
Resource Cleanup
All the resources we created can be cleaned up by running the following commands.
$ aws neptune delete-db-instance --db-instance-identifier NeptuneGraphQLClusterWriter --region us-west-2$ aws neptune delete-db-cluster --db-cluster-identifier NeptuneGraphQLCluster --skip-final-snapshot –region us-west-2$ aws lambda delete-function --function-name NeptuneGraphQLAPILambda ––region us-west-2$ aws appsync delete-graphql-api --api-id <API_ID> --region us-west-2$ aws s3 rm s3://<BUCKET_NAME> --recursive$ aws s3api delete-bucket --bucket <BUCKET_NAME> --region us-west-2Conclusion
In this tutorial, we've explored the process of constructing GraphQL APIs using AWS Neptune and demonstrated how functional APIs can be established within the AWS ecosystem. This involved setting up the necessary infrastructure and seamlessly integrating AWS AppSync, AWS Lambda, and AWS Neptune. This guide not only provides a foundational understanding of these integrations but also serves as a blueprint for developing more complex applications in the future, illustrating the scalability and flexibility of these AWS services.
Opinions expressed by DZone contributors are their own.
Comments