Stream Processing in the Serverless World
Learn how real-time data processing enables businesses to gain actionable insights without the overhead of managing infrastructure.
Join the DZone community and get the full member experience.
Join For FreeIt’s a very dynamic world today. Information moves fast. Businesses generate data constantly. Real-time analysis is now essential. Stream processing in the serverless cloud solves this. Gartner predicts that by 2025, over 75% of enterprise data will be processed outside traditional data centers. Confluent states that stream processing lets companies act on data as it's created. This gives them an edge.
Real-time processing reduces delays. It scales easily and adapts to changing needs. With a serverless cloud, businesses can focus on data insights without worrying about managing infrastructure.
In today’s post, we’ll answer the question of stream processing and how it is done and describe how to design a highly available and horizontally scalable dependable stream processing system on AWS. Here, we will briefly discuss the market area of this technology and its future.
What Is Stream Processing?
Stream processing analyzes data in real-time as it flows through a system. Unlike batch processing, which processes data after it's stored, stream processing handles continuous data from sources like IoT devices, transactions, or social media.
Today, industry tools like Apache Kafka and Apache Flink manage data ingestion and processing. These systems must meet low latency, scalability, and fault tolerance standards, ensuring quick, reliable data handling. They often aim for exactly one processing to avoid errors. Stream processing is vital in industries requiring immediate data-driven decisions, such as finance, telecommunications, and online services.
Key Concepts in Stream Processing
Event-driven architecture relies on events to trigger and communicate between services, promoting responsiveness and scalability. Stream processing enables real-time data handling by processing events as they occur, ensuring timely insights and actions. This approach fits well where systems must react quickly to changing conditions, such as in financial trading or IoT applications.
Data Streams
A data stream is a continuous flow of data records. These records are often time-stamped and can come from various sources like IoT devices, social media feeds, or transactional databases.
Stream Processing Engine
Imagine a stock trading platform where prices fluctuate rapidly. An event-driven architecture captures each price change as an event.
The stream processing engine filters relevant price changes, aggregates trends, and transforms the data to provide real-time analytics and automated trading decisions. This ensures that the platform can react instantly to market conditions, executing trades at the optimal moments.
Event Time
This is when an event (a data record) occurred. It is essential in stream processing to ensure accurate analysis, especially when dealing with out-of-order events.
Windowing
In stream processing, windowing is a technique to group data records within a certain timeframe. For example, calculate the average temperature reported by sensors every minute.
Stateful vs. Stateless Processing
Stateful processing keeps track of past data records to provide context for the current data, while stateless processing handles each data record independently.
Visualizing Stream Processing
To help you better understand stream processing, let's visualize the concepts:
- Data streams:
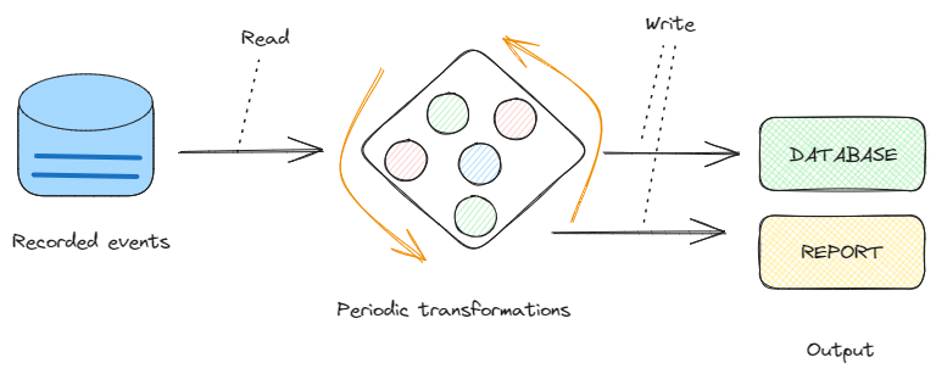
- Stream processing engine:
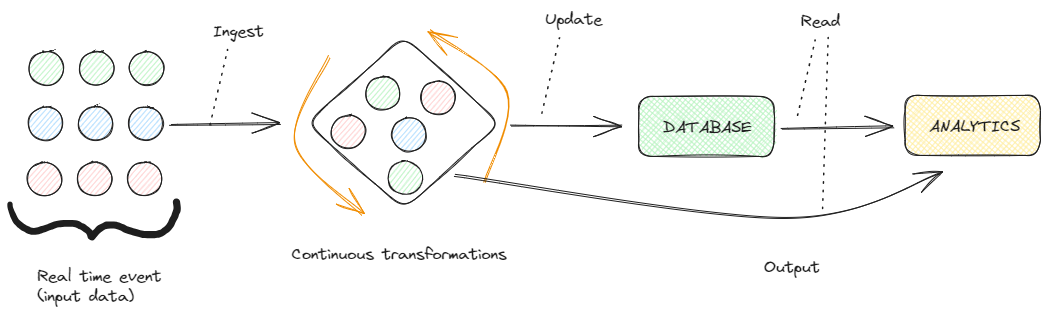
- Windowing:
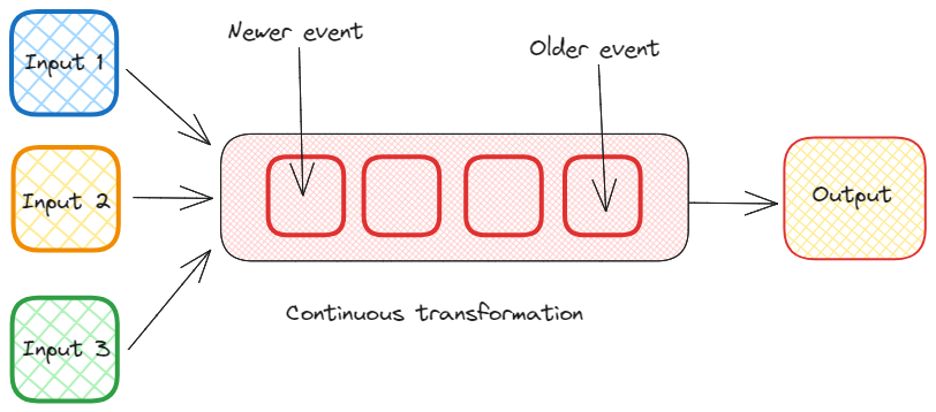
Why Stream Processing Matters in the Modern World
Since organizations depend more and more on near-real-time information to identify the optimal decisions, stream processing emerged as the key solution. For instance, in the financial sector, identifying fraudulent transactions in the process of occurrence can save a lot of money. In e-commerce, real-time recommendations can improve overall customer enjoyment and loyalty as well as increase sales.
Market Segment and Growth
The market for stream processing has been developing even more actively in recent years. From the industry outputs, the stream processing market was estimated to be at around $ 7 billion on the world stage. The number of IoT devices employed, demands for fast analytical results, and growth of cloud services play a role in this case.
In the global market, the major contenders are Amazon Web Services, Microsoft Azure, Google Cloud Platform, and IBM. Kinesis and Lambda services of AWS are most commonly used for extending serverless stream processing applications.
Building a Stream Processing Application With Lambda and Kinesis
Let's follow the steps to set up a basic stream processing application using AWS Lambda and Kinesis.
Step 1: Setting Up a Kinesis Data Stream
- Create a stream: Go to the AWS Management Console, navigate to Kinesis, and create a new Data Stream. Name your stream and specify the number of shards (each can handle up to 1 MB of data per second).
- Configure producers: Set up data producers to send data to your Kinesis stream. This application could log user activity or send sensor data to IoT devices.
- Monitor stream: Use the Kinesis dashboard to monitor the data flow into your stream. Ensure your stream is healthy and capable of handling the incoming data.
Step 2: Creating a Lambda Function to Process the Stream
- Create a Lambda Function: In the AWS Management Console, navigate to Lambda and create a new function. Choose a runtime (e.g., Python, Node.js), and configure the function's execution role to allow access to the Kinesis stream.
- Add Kinesis as a trigger: Add your Kinesis stream as a trigger in the function's configuration. This setup will invoke the Lambda function whenever new data arrives in the stream.
- Write the processing code: Implement the logic to process each record. For example, if you analyse user activity, your code might filter out irrelevant data and push meaningful insights to a database.
import json
def lambda_handler(event, context):
for record in event['Records']:
# Kinesis data is base64 encoded, so decode here
payload = json.loads(record['kinesis']['data'])
# Process the payload
print(f"Processed record: {payload}")4. Test and Deploy: Test the function with sample data to ensure it works as expected. Once satisfied, deploy the function, automatically processing incoming stream data.
Step 3: Scaling and Optimization
Event source mapping in AWS Lambda offers critical features for scaling and optimizing event processing. The Parallelization Factor controls the number of concurrent batches from each shard, boosting throughput.
Lambda Concurrency includes Reserved Concurrency to guarantee available instances and Provisioned Concurrency to reduce cold start latency. For error handling, Retries automatically reattempt failed executions, while Bisect Batch on Function Error splits failed batches for more granular retries.
In scaling, Lambda adjusts automatically to data volume, but Reserved Concurrency ensures consistent performance by keeping a minimum number of instances ready to handle incoming events without throttling.
Conclusion
Stream processing in the serverless cloud is a powerful way to handle real-time data. You can build scalable applications without managing servers with AWS Lambda and Kinesis. This approach is ideal for scenarios requiring immediate insights.
References
Opinions expressed by DZone contributors are their own.
Comments