CPU vs. GPU Intensive Applications
Learn about CPU vs. GPU intensive applications and why each is best suited for particular tasks. We explain parallelization, Amdahl’s Law, and how these concepts affect whether to use a CPU, GPU, or both for your application.
Join the DZone community and get the full member experience.
Join For FreeCPU vs. GPU Intensive Applications
Computing has become increasingly important in our daily lives and society as a whole. While the trend of transistor counts doubling every two years, known as Moore’s Law, may be coming to an end, computing continues to play a vital role. But we aren’t referring to running background applications that hog resources or playing the most visually intensive games.
We are talking about the productive applications of computing for generational discovery. Computation has become an essential tool in many professions, with specialized subfields like computational biology, artificial intelligence and machine learning, and complex computational algorithms for industries like finance, weather, and more. Some of these fields have emerged in the last decade.
There is a correlation between advancements in computational hardware and the real-world impacts of computational applications. The need for more powerful computing drives research and development for better hardware, which, in turn, makes it easier to develop more powerful applications. It's worth noting that the gaming industry played a significant role in developing specialized hardware, such as the graphics processing unit (GPU), which has become an essential component in contemporary advances in fields like machine learning.
The growing role of using GPUs for general processing in data science, machine learning, modeling, and other productive tasks has in turn motivated improved hardware catering to these applications, and better software support to boot. NVIDIA’s development of their Tensor Cores has drastically improved matrix multiplication found in training neural networks and executing AI inferencing in real-world, real-time applications and other machine learning tasks in various fields.
With all this in mind, it should be simple: buy as many GPUs as possible. However, it to harness the computational performance of GPUs, we have to consider other factors.
Not only can state-of-the-art GPUs cost many thousands of dollars, but for some applications, they might not scale well. The parallelizability of an application, software support, and the scale (as well as budget) — all influence how much weight should be put on the CPU and GPU specs for a user’s computational needs.
Parallelization Basics
CPUs are good at general-purpose computing and compute anything we program. A high-powered CPU can give us one answer quickly, and this characteristic is what’s known as latency: the time it takes to go from cause to effect.
GPUs, on the other hand, are often concisely described as trading somewhat lower latency for much higher throughput: a measure of the amount of “causes” (i.e., data) being turned into results over time.
While clock speeds aren’t everything, they do give us an idea of how quickly instructions tick through a device. Notice that the clock speeds of modern CPUs are roughly twice as high as those of the latest and greatest GPUs.
While the cores in a GPU are not as fast individually and far more specialized than the cores in a CPU, there are far more of them (16,384 CUDA cores in the NVIDIA’s high-end consumer RTX 4090), so throughput is high for operations that can be parallelized favorably for GPUs.
Modern CPUs have also embraced multicore computing (albeit at a much lesser extreme than their GPU cousins). This is in part a move motivated by reaching the flat part of the s-curve for scaling phenomena in chip manufacturing. In short, modern CPU cores can’t get much faster without running into serious thermal issues.
The basic rule of thumb for whether to prioritize GPUs or CPUs for an application is that GPUs are much better for parallel work. But, as discussed before, CPUs have a small degree of parallelism, and not all types of parallelization in workloads are created equal.
Matrix operations and evolutionary algorithm are both, in a sense, embarrassingly parallel; while matrix operations are well-suited for GPU speedups, the latter best suited to be executed on multiple CPU cores. Ultimately, many real-world applications have parts that rely heavily on both CPU and GPU-intensive. Balancing and optimizing the two cleverly can provide additional gains in speed and computational accessibility, as we’ll see in the example of the deep neuroevolution strategy developed at the now disbanded Uber AI labs.
Types of Parallelization
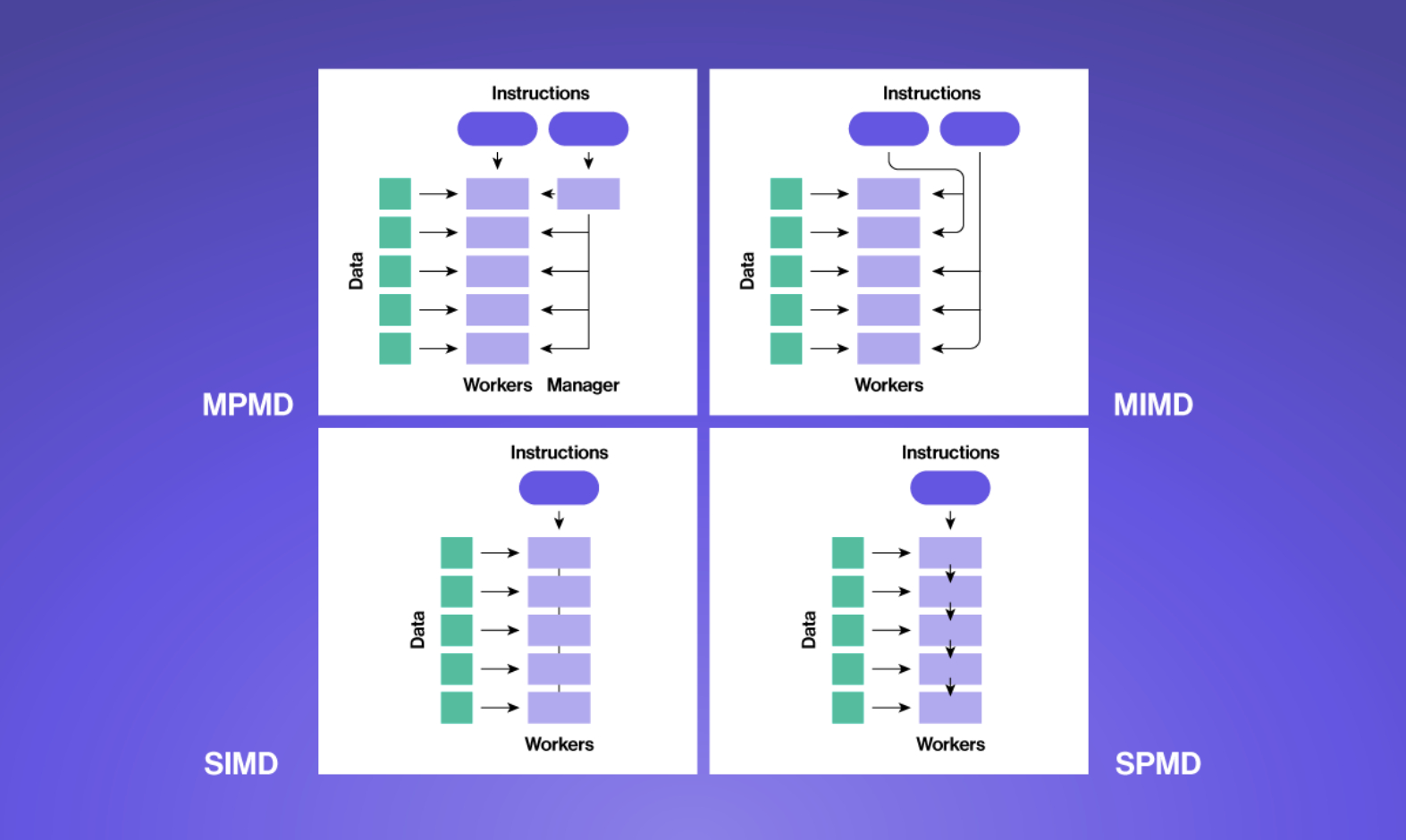
In general, tasks can more easily be made parallel when they can be broken down into independent components that don’t rely on each others’ outputs. Depending on the intrinsic characteristics of the problem, parallelization comes in a few different flavors. We can use Flynn's taxonomy for computer architectures as a scaffolding.
Multiple Program Multiple Data
In MPMD, multiple programs are run in parallel on different data sets. Each program operates independently of the others, and they can run on different processors or nodes in a cluster. This type of parallelization is commonly used in high-performance computing applications, where multiple programs need to be executed simultaneously to achieve the desired performance.
Multiple Instruction Multiple Data
MIMD is similar, but can be distinguished by the absence of a central control process. Multiple processors execute different instructions on different data sets simultaneously. Each processor is independent and can execute its own program or instruction sequence. This type of parallelization is commonly used in distributed computing, where different processors work on different parts of a problem.
Single Instruction Multiple Data
In SIMD, multiple processors execute the same instruction on different data sets simultaneously. This type of parallelization is often used in applications that require processing large amounts of data in parallel, such as graphics processing and scientific computing. For example, in image processing, the same operation can be applied to all pixels in an image using SIMD.
Single Program Multiple Data
In SPMD, multiple processors execute the same program on different data sets simultaneously. Each processor may operate independently on its own data, but they all execute the same code. This type of parallelization is often used in cluster computing, where a single program is executed on multiple nodes in a cluster, with each node processing a different part of the input data. It is similar to MIMD, but with all processors executing the same program.
Amdahl’s Law: Parallelization’s Limit
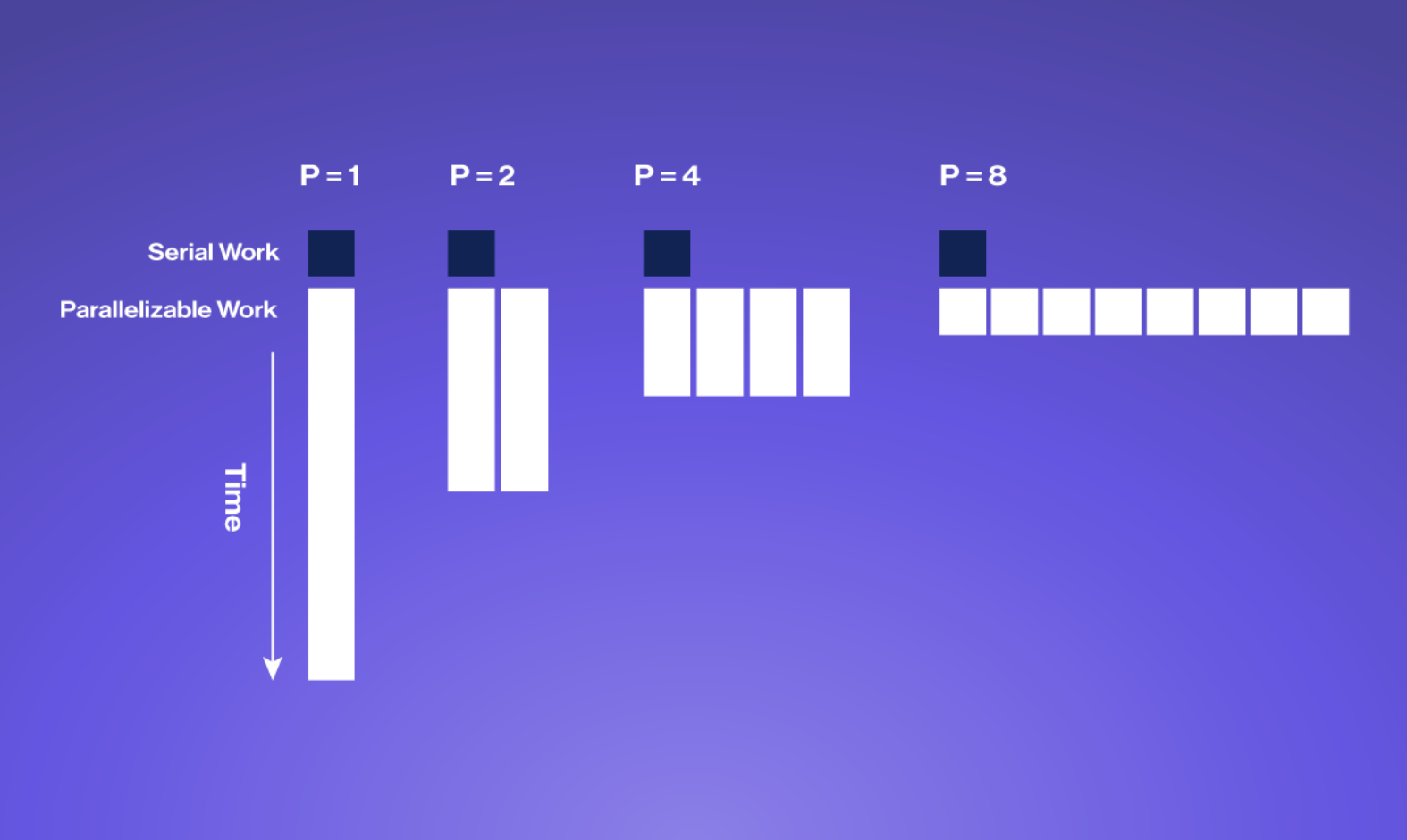
Parallelization can yield substantial speed-ups and energy savings for intensive algorithms, but there are limits to how much can be gained determined by the part of an algorithm that cannot be parallelized called Amdahl’s Law.
Amdahl's Law is a formula that describes the maximum speedup that can be achieved when a program is run in parallel on multiple processors. It takes into account the percentage of the program that can be parallelized and the percentage that must be run sequentially.
The formula states that the maximum speedup that can be achieved is limited by the sequential portion of the program. In other words, if a program has 80% of its code that can be run in parallel and 20% that must be run sequentially, the maximum speedup that can be achieved is 5x, even if an infinite number of processors are used. This is because the 20% sequential portion will always take the same amount of time to execute, no matter how many processors are used.
To achieve the maximum speedup possible, it is important to identify which parts of a program can be parallelized and optimize them accordingly. Additionally, the hardware being used should be designed to minimize the impact of the sequential portion of the program.
Overall, Amdahl's Law is an important concept to understand when working with parallel computing, as it helps to set realistic expectations for the potential speedup that can be achieved and guides optimization efforts.
![Amdahl’s Law: Parallelization’s Limit]() Examples of When to Use CPU vs. GPU: Best Use Cases
Examples of When to Use CPU vs. GPU: Best Use Cases
 Examples of When to Use CPU vs. GPU: Best Use Cases
Examples of When to Use CPU vs. GPU: Best Use CasesThe checklist for whether to emphasize GPU or CPU in planning compute hardware for a given use case is, in an ideal world, very short: “Is there an efficient GPU implementation available for this use case?”
Some GPU implementations are better than others, and forcing an algorithm that has a significant number of non-parallelizable components to run on GPU can in some cases do more harm than good, especially if there is a significant overhead for moving data between GPU VRAM memory and system RAM.
Compiling Source Code: CPU (and Memory) Focus
Compiling source code is one area where GPUs generally do not come into play. When planning a system primarily for building large codebases, CPU performance is more important and it’s particularly important to have enough memory (RAM).
When building a large code base with significant overhead dedicated to reading/writing to disk, don’t forget to invest in a fast storage technology like NVMe storage.
The best Intel CPUs often have slightly better single-thread performance than AMD’s line, but this only sometimes equates to better build times. Check openbenchmarking.org for CPU compilation benchmarks for a variety of languages. Keep in mind that more cores does not always mean more better; finding the optimal CPU at the best budgetted price point can not only save time and money, but also reduce energy usage and TCO.
Deep Learning: GPU Dominant
Modern machine learning is characterized by deep learning, models with multiple layers of non-linear transformations, mostly implemented as matrix operations like dot products and convolutions. These operations are inherently vectorizable: we can batch many such operations together and execute them all in one forward pass. In other words, the building blocks of modern neural networks are largely SIMD parallelizable.
GPUs have deservedly become the gold standard and common practice for deep learning pipelines, especially training. NVIDIA GPUs, have over a decade of research and development emphasizing deep learning. The suitability of GPU hardware for neural networks has sparked the epitome of a virtuous cycle, as it incentivizes even better support in the development of features such as improved linear algebra primitives, specialized low-precision data types, and tensor cores.
Training full scale AI Models require expertise in distributed computing, substantial finances, and supercomputer access. Fine-tuning smaller or mid-sized LLMs can be accessible with high-end consumer or professional GPUs that have significant onboard VRAM.
Evolutionary Algorithms: Multicore CPU Emphasis
While deep learning and back-propagation may be the most well-known types of machine learning today, there are still situations where evolutionary algorithms can be more effective.
Evolutionary algorithms involve calculating the "fitness" of many different variations, which are called individuals. Evolutionary algorithms have been shown to be just as good as traditional reinforcement learning methods for this type of problem.
Calculating the fitness for each individual in a population can often be done in parallel, without needing to wait for other individuals to finish. SPMD and MPMD algorithms, which don't require a manager or central controller, are often used for these types of calculations. CPUs, like AMD's EPYC or Ryzen Threadripper, are particularly good for running these types of algorithms and can communicate with each other using the Message Passing Interface (MPI) standard.
Finding a Balance: Optimizing GPU and CPU Use for Deep Neuroevolution
While deep neural networks are well-suited to vector processing on powerful GPUs and evolutionary algorithms are conducive to parallel implementation on multi-core CPUs, sometimes we need both. Optimizing the use of GPU and CPU resources is crucial for improving the performance of deep neuroevolution, which involves evolutionary algorithms used to optimize deep neural networks.
We leverage SPMD/MPMD paradigms of evolutionary algorithms on the CPU and the SIMD mathematical primitives of neural networks simultaneously on the GPU. Utilizing both CPU and GPU capabilities ensure that these optimal performance and efficiency.
Aside from optimizing GPU and CPU use, selecting the right hyperparameters of the optimization algorithm is also important. Hyperparameters such as population size, mutation rate, and crossover rate can significantly impact the performance of the optimization process. Careful tuning is often required to achieve optimal results.
What Applications Are GPU Intensive and Which Are CPU Intensive?
In addition to the suitability of GPUs for neural networks, many problems of interest in HPC are based on physics, such as computational fluid dynamics or particle simulations. Physics has the convenient property of locality, i.e., objects are only influenced by other objects in their neighborhood.
The computational consequences of this are that many aspects of physical interactions can be modeled in parallel, such as computing the forces on a cloud of particles before updating their states. This means that substantial parts of many physics-based applications can be implemented effectively on GPUs.
For physics-based problems, the existence of a GPU implementation is often the only consideration needed to decide whether a given application can benefit from a system that emphasizes GPU hardware. Most major molecular dynamics packages now come with good GPU support, including AMBER, GROMACS, and more.
As AlphaFold and other deep learning breakthroughs have shown, neural networks can readily complement computational biology.
On the other had, CPU intensive applications stem from database management and virtual machines. CPUs are extremely important for code compiling such as running our Operating Systems, a large network of code that enable our systems to run at all, much less instruct what tasks will go to our GPUs. The CPU acts as a delegator and foreman for your computer.
While not all GPU implementations are equal, many HPC applications now benefit from parallelization. With good GPU support, speeding up significant portions of algorithms in most fields owes a lot to hardware dedicated to displaying millions of pixels on a screen. The advancement in general-purpose computing with GPUs was further accelerated with the progress in deep learning.
With powerful GPU-enhanced simulations for other fields becoming common practice, we can expect the hardware specialization and algorithmic improvements, even in the face of the breakdown of Moore’s law and Dennard scaling. With more advanced instruction sets and highly efficient architectures developed, the shift in computing will be a combination between CPUs and GPUs.
Published at DZone with permission of Kevin Vu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments