Conversational Applications With Large Language Models Understanding the Sequence of User Inputs, Prompts, and Responses
This article explains how user inputs are processed, converted into prompts, sent to LLMs, and responses are generated and presented to the user.
Join the DZone community and get the full member experience.
Join For FreeConversational Applications are emerging to be an integral part of our daily lives, from virtual assistants to chatbots and voice-based interfaces. Have you ever wondered what happens behind the scenes when you interact with these systems? In this article, we will delve into the technical aspects of how user inputs are processed, converted into prompts, sent to large language models (LLMs), and responses are generated and presented back to the user. We will explain the sequence of events in a simplified manner, making it easy for both technical and non-technical readers to understand.
User Input
It all begins with a user input, which can be a spoken command, text message, or even a button click. For example, let's say a user says, "Hey, what's the weather like today?"
Preprocessing
Once the user input is received, it goes through a series of preprocessing steps. These steps may include:
- Tokenization: Breaking down the input into individual words or tokens. In our example, "Hey" would be one token, "What's" would be another, and so on.
- Named Entity Recognition (NER): Identifying specific entities within the input, such as names, locations, organizations, etc. For instance, if the user had said, "What's the weather like in New York City?" the named entity would be "New York City."
- Part-of-speech Tagging (POS tagging): Identifying the grammatical category of each word, such as noun, verb, adjective, etc.
- Dependency Parsing: Analyzing the relationships between the tokens, such as subject-verb-object relationships.
These preprocessing steps help prepare the input data for the next stage, which is converting the user input into a prompt.
Prompt Generation
The preprocessed input is then transformed into a prompt, which is a concise representation of the user's query or request. The prompt is designed to provide the LLM with sufficient information to generate an appropriate response.
For our example, the prompt might look something like this:
{
"intent": "check_weather",
"location": "New York City"
}
Notice how the prompt contains two key pieces of information: the intent (check_weather) and the location (New York City). This information helps the LLM understand what the user wants and tailor its response accordingly.
Large Language Model (LLM) Processing
The prompt is now ready to be sent to the LLM for processing. The LLM uses natural language understanding (NLU) algorithms to comprehend the meaning of the prompt and generate a response.
Let's assume that the LLM generates the following response:
"Today's forecast for New York City shows sunny skies with a high of 75 degrees Fahrenheit and a low of 50 degrees Fahrenheit."
Post-processing
After receiving the response from the LLM, there may be additional post-processing steps to enhance the output. Some of these steps could include:
- Sentiment Analysis: Determining whether the tone of the response is positive, negative, neutral, or mixed.
- Intent Classification: Ensuring that the response aligns with the original intent of the user's input.
- Fluency Evaluation: Assessing the coherence and readability of the response.
If necessary, the response may undergo further refinement through machine learning algorithms or rule-based engines to ensure it meets certain quality standards.
Response Presentation
Finally, the response is presented back to the user through their chosen interface, such as a voice assistant, messaging platform, or web application. In our case, the response would be spoken aloud or displayed as text on a screen.
Let’s take some specific industry scenarios on how the flow works. Here I am taking the concept of “entity resolution”, an important one in the data management space, and exploring how conversational applications built on LLM may work.
The following diagram provides a view of the flow of sequence, data, and events.
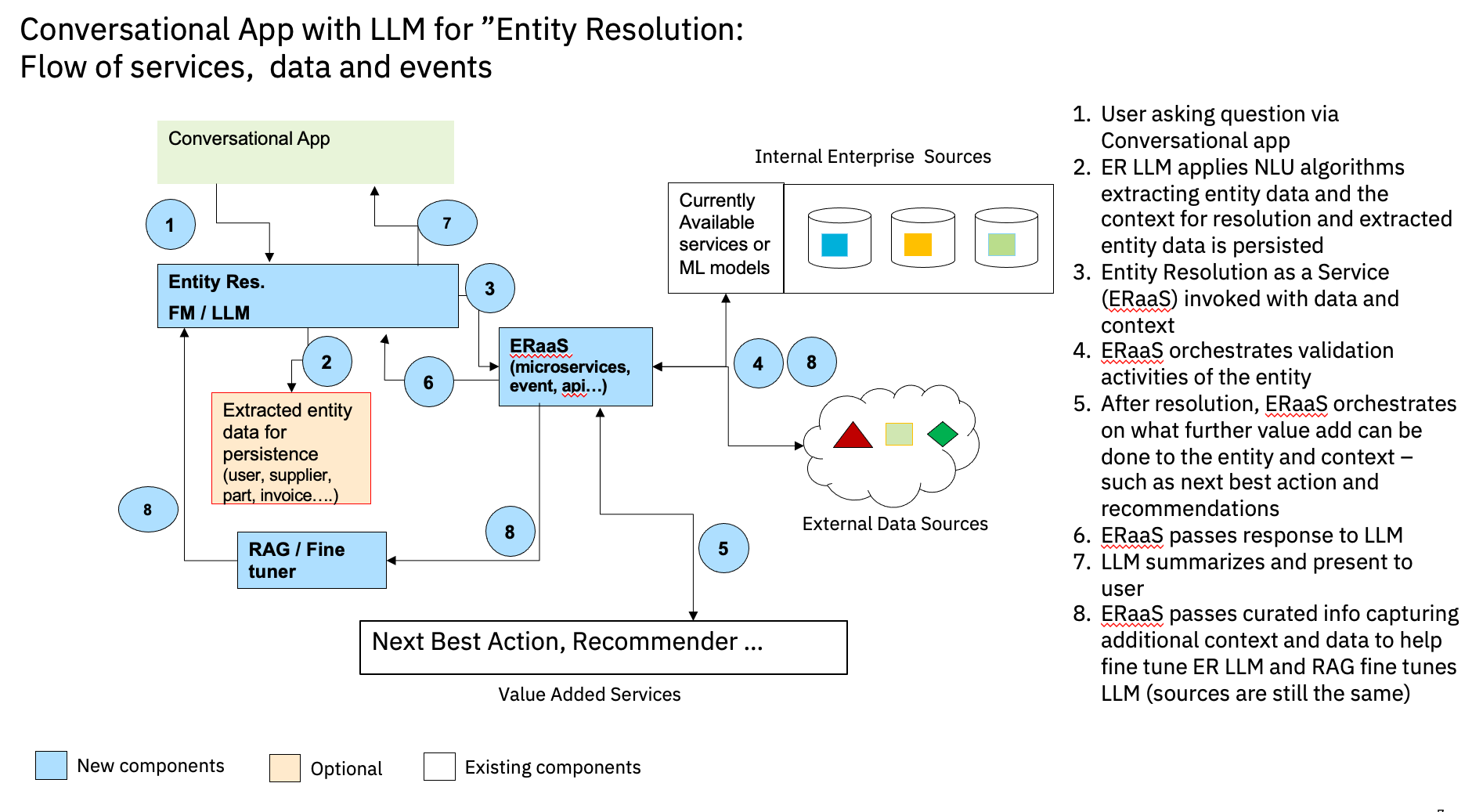
Further here, I am taking in two industry scenarios, Banking and Retail, to showcase the flow.
Example 1: Resolving "User Entity" in the Context of the Know Your Customer (KYC) Process in the Banking Services Space
User Input
"Hi, I'm a new customer, and I'd like to open a checking account."
Preprocessing
The conversational AI system starts by analyzing the user's input to identify the key entities mentioned. In this case, the user has mentioned a financial institution ("bank") and a financial product ("checking account"). The system performs entity recognition to identify the specific bank and account type that matches the user's description. Let's say the system identifies the bank as "ABC Bank" and the account type as "Personal Checking Account."
Prompt Generation
The system then creates a prompt that encodes the identified entities and the context of the user's request. The prompt might look something like this:
{
"entity1": "ABC Bank",
"entity2": "Personal Checking Account",
"context": "account opening"
}
Large Language Model (LLM) Processing
The prompt is then passed to a large language model (LLM) trained specifically for KYC processes in the banking industry. The LLM processes the prompt and generates a response based on the context and entities provided. The response might contain questions related to the user's identity, such as their name, address, and date of birth, as well as requests for documentation to verify their identity.
Post-processing
After receiving the response from the LLM, the conversational AI system performs additional processing to refine the output. This might involve:
- Entity Linking: Identifying relationships between entities in the response and linking them to external databases or systems. For example, the system might link the user's name to their credit report or government ID records.
- Risk Detection: Analyzing the user's responses and documentation to detect potential risks or compliance issues. For instance, the system might flag a user who provides inconsistent identification documents or whose personal information matches a known fraudster.
- Regulatory Compliance: Verifying that the user's information and documentation meet regulatory requirements for KYC. The system might check against federal regulations, such as the USA PATRIOT Act, or international standards, such as the Wolfsberg Principles.
Response Presentation
Finally, the system presents the response to the user in a natural language format, taking into account the user's preferences for communication channel and style. For example, the system might display a list of requested documents and instructions for uploading them securely while also providing options for speaking with a live representative or scheduling an appointment at a branch location.
In this example, the conversational AI system used KYC processes to accurately identify the bank and account type mentioned by the user and then generated appropriate questions and requests for verification and risk assessment. By leveraging large language models and sophisticated natural language processing techniques, the system was able to streamline the account opening process while ensuring regulatory compliance and mitigating risk.
Example 2: Resolving for “Product Entity” in the Context of the Supply Chain Process in the Retail Industry
User Input
"We've received duplicate shipments of the same product from different suppliers. Can you help us match the products and resolve the issue?"
Preprocessing
The conversational AI system starts by analyzing the user's input to identify the key entities mentioned. In this case, the user has mentioned a product and multiple suppliers. The system performs entity recognition to identify the specific product and suppliers that match the user's description. Let's say the system identifies the product as "Widget X" and the suppliers as "Supplier A" and "Supplier B".
Prompt Generation
The system then creates a prompt that encodes the identified entities and the context of the user's request. The prompt might look something like this:
{
"entity1": "Widget X",
"entity2": ["Supplier A," "Supplier B"],
"context": "product matching"
}
Large Language Model (LLM) Processing
The prompt is then passed to a large language model (LLM) trained specifically for product matching in the retail supply chain domain. The LLM processes the prompt and generates a response based on the context and entities provided. The response might contain questions related to the product's features, such as its size, color, and material, as well as requests for documentation or images to verify the product's authenticity.
Post-processing
After receiving the response from the LLM, the conversational AI system performs additional processing to refine the output. This might involve:
- Product Feature Analysis: Comparing the product features mentioned by the user and the suppliers to identify any discrepancies or mismatches. For example, if Supplier A describes Widget X as being blue and made of plastic, but Supplier B describes it as red and made of metal, the system might flag this as a potential issue.
- Documentation Verification: Requesting and reviewing documentation from the suppliers to confirm the product's origin and authenticity. This could include certificates of authenticity, serial numbers, or other identifying information.
- Image Recognition: Using computer vision algorithms to analyze images of the product provided by the suppliers and compare them to each other and to a database of known products. This can help identify any differences or similarities between the products.
Response Presentation
Finally, the system presents the response to the user in a natural language format, taking into account the user's preferences for communication channel and style. For example, the system might display a table comparing the product features and documentation provided by each supplier, highlighting any discrepancies or matches. Alternatively, the system might provide a recommendation for which supplier's product to use based on factors such as price, quality, and availability.
In this example, the conversational AI system used product matching techniques to accurately identify the product and suppliers mentioned by the user and then generated appropriate questions and requests for verification and authentication. By leveraging large language models and sophisticated natural language processing techniques, the system was able to efficiently and effectively match the product and resolve the issue, improving the accuracy and efficiency of the retail supply chain process.
Conclusion
Now that we have walked through the sequence of events, it should be clear how user inputs are converted into prompts, processed by LLMs, and presented back to users in a conversational application with LLMs. By breaking down the process into smaller components, we can gain a deeper appreciation for the complexities involved in creating intelligent conversational experiences leveraging LLMs. Whether you're a solution architect designing the next generation of conversational apps on LLM platforms or a business leader looking to leverage these technologies, understanding the fundamentals is essential for harnessing their full potential. I hope the article gives you a technical or business perspective.
Opinions expressed by DZone contributors are their own.
Comments