Consistency in Databases
How will you know if a database is strong or eventual consistent?
Join the DZone community and get the full member experience.
Join For FreeHow will you know if a database is strong or eventual consistent?
The Rules
R + W > N
Ensures strong consistency. Read will always reflect the most recent write.
R=W= [Local_] QUORUM — Strong Consistency.
W + R <= N — Eventual Consistency.
W=1 — Good for fire-and-forget writes: logs, traces, metrics, page views, etc.
Definitions:
N= Replication Factor (number of replicas)
R= Number of Replicas read from (before the response is returned)
W= Number of replicas written to (before the write is considered a success)
QUORUM = (N/2 + 1) replicas read from before the response is a Return, and the same number of replicas written to before the write is considered a Success.
E.g. Suppose N = 2
Write one Read one = Weak
Write one Read All = Strong
Write All Read one = Strong
Write Quorum Read Quorum = Strong
E.g. Consistency Level in Cassandra
| Consistency Level | Write | Read | Consistency |
| Any | 1 replica (including HH) | - | Weak |
| ONE | 1 replica | 1 replica | Strong if N < 2, Else Weak as per R + W > N rule |
| TWO | 2 replica | 2 replica | Strong if N < 4, Else Weak as per R + W > N rule |
| THREE | 3 replica | 3 replica | Strong if N < 6, Else Weak as per R + W > N rule |
| QUORUM | N/2 + 1 | N/2 + 1 | Strong |
| LOCAL_QUORUM (to avoid latency issues |
(dc_replicas)/2 + 1 (local Datacentre) | (dc_replicas)/2 + 1 (local Datacentre) | Strong |
| EACH_QUORUM (useful in backup scenarios) |
(dc_replicas)/2 + 1 (each Datacentre) | (dc_replicas)/2 + 1 (each Datacentre) | Strong |
| ALL | N | N | Strong |
Consistency in MongoDB:
Below are write and read concerns in MongoDB.
| Write Concern levels | Description |
| 0 | Requests no acknowledgement of the write operation |
| 1 | Requests acknowledgement from the standalone mongod or the primary in a replica set. |
| number >1 | valid only for replica sets to request acknowledgement from specified number of members, including the primary. |
| majority | Requests acknowledgement from the majority of voting nodes, including the primary. |
| Read Concern Levels | Description |
| local | reads against primary reads against secondaries if the reads are associated with causally consistent sessions. |
| available | reads against secondaries if the reads are not associated with causally consistent sessions. unavailable for use with causally consistent sessions. |
| majority | returns data that has been acknowledged by a majority of the replica set members |
| linearizable |
returns data that reflects all successful majority-acknowledged writes that completed prior to the start of the read operation linearizable is unavailable for use with causally consistent sessions. |
Causal Consistency Session
Causal relationship means that an operation logically depends on a preceding operation. MongoDB executes causal operations in an order that respects their causal relationships, and clients observe results that are consistent with the causal relationships.
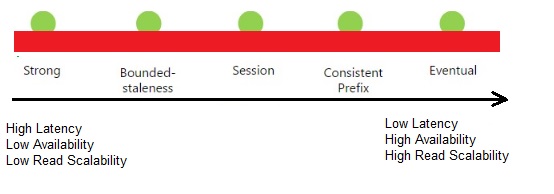
Consistency Levels and Guarantees
| Consistency Level | Guarantees |
|---|---|
| Strong | Reads are guaranteed to return the most recent write |
| Bounded Staleness | Consistent Prefix. Reads lag behind writes by at most k prefixes or t interval |
| Session | Consistent Prefix. Monotonic reads, monotonic writes, read-your-writes, write-follows-reads |
| Consistent Prefix | Updates returned are some prefix of all the updates, with no gaps |
| Eventual | Out of order reads |
| Causal Consistency Guarantees | Description |
| Read your writes | Read operations reflect the results of write operations that precede them. |
| Monotonic reads | Read operation do not return results that corresponds to an earlier state of the data than a preceding read operation. |
| Monotonic writes | Write operations that must precede other writes are executed before those other writes. |
| Writes follow reads | Write operations that must occur after read operations are executed after those read operations. |
If we see the consistency in MongoDB implementation, it will be something like below:
| Consideration | Write Concern | Read Concern | Consistency |
| Real Time Order | majority | linearizable | Strong |
| Read Your Own Writes | causally consistent session | causally consistent session | Weak |
| Read Your Own Writes | majority | majority / linearizable | Strong |
CAP Theorem
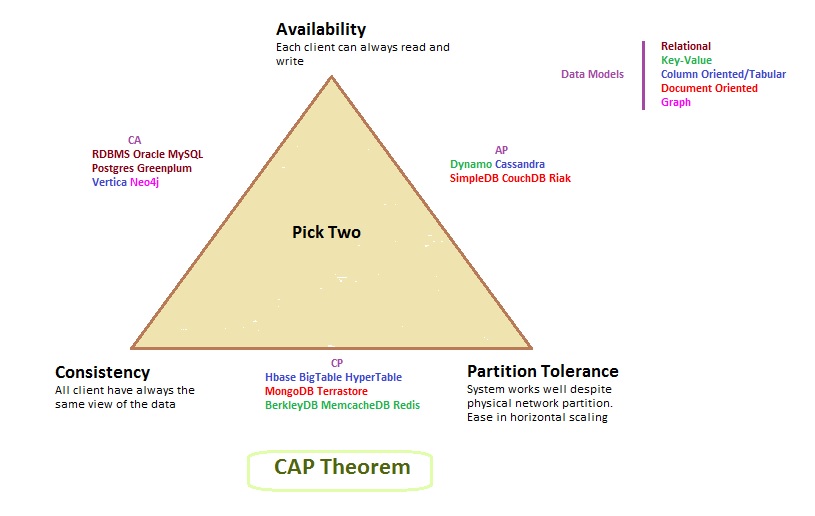
PACELC Theorem
If there is Partition:
Then system trade-offs between Availability and Consistency
Else system trade-offs between Latency and Consistency
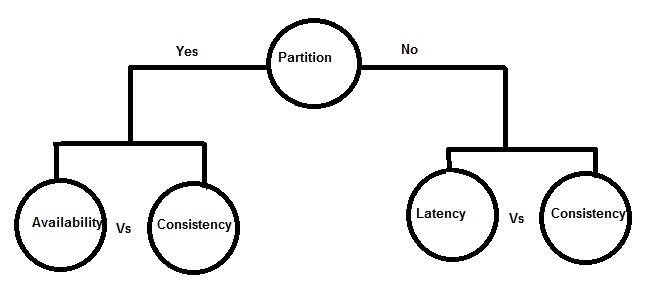
Database can be configured in one of below way as mentioned as per PACELC theorem :
| DDBS ( one of these --> ) | P+A | P+C | E+L | E+C |
| DynamoDB | Yes | Yes | ||
| Cassandra | Yes | Yes | ||
| Cosmos DB | Yes | Yes | ||
| Riak | Yes | Yes | ||
| VoltDB/H-Store | Yes | Yes | ||
| Megastore | Yes | Yes | ||
| BigTable/HBase | Yes | Yes | ||
| MongoDB | Yes | Yes | ||
| PNUTS | Yes | Yes | ||
| Hazelcast IMDG | Yes | Yes | Yes |
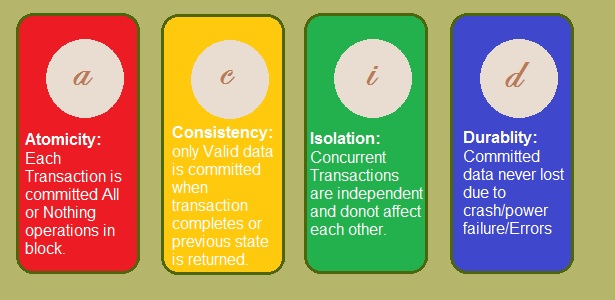
ACID
Atomic: Atomic means “all or nothing;” that is, when a statement is executed, every update within the transaction must succeed in order to be called successful. There is no partial failure where one update was successful and another related update failed. The common example here is with monetary transfers at an ATM: the transfer requires subtracting money from one account and adding it to another account. This operation cannot be subdivided; they must both succeed.
Consistent:
Consistent means that data moves from one correct state to another correct state, with no possibility that readers could view different values that don’t make sense together. For example, if a transaction attempts to delete a Customer and her Order history, it cannot leave Order rows that reference the deleted customer’s primary key; this is an inconsistent state that would cause errors if someone tried to read those Order records.
Isolated:
Isolated means that transactions executing concurrently will not become entangled with each other; they each execute in their own space. That is, if two different transactions attempt to modify the same data at the same time, then one of them will have to wait for the other to complete.
Durable:
Once a transaction has succeeded, the changes will not be lost. This doesn’t imply another transaction won’t later modify the same data; it just means that writers can be confident that the changes are available for the next transaction to work with as necessary.
BASE
How do the vast data systems of the world such as Google’s BigTable and Amazon’s Dynamo and Facebook’s Cassandra deal with a loss of consistency and still maintain system reliability? The answer is BASE (Basically Available, Soft state, Eventual consistency). The BASE system gives up on the consistency of a distributed system.

Tunable Consistency is a term used in Cassandra for tuning the consistency levels.
Based on System requirement, it should be tuned accordingly for consistency.
Next Steps :
You may further explore on it, here are some related links :
https://www.mongodb.com/mongodb-architecture
http://cassandra.apache.org/doc/latest/architecture/dynamo.html#tunable-consistency
https://hbase.apache.org/acid-semantics.html
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/filesystem/introduction.html#Consistency
Opinions expressed by DZone contributors are their own.
Comments