Consistency Conundrum: The Challenge of Keeping Data Aligned
Maintaining consistency is crucial to ensure a unified view of the data, which is essential for the correct functioning of distributed applications.
Join the DZone community and get the full member experience.
Join For FreeA system may store and replicate its data across different nodes to fulfill its scaling, fault tolerance, load balancing, or partitioning needs. This causes data synchronization issues, read-write conflicts, causality problems, or out-of-order updates. These issues arise due to concurrent updates on copies of the same data, network latency or network partition between nodes, node or process crashes, and clock synchronization, to name a few.
Due to these issues, the application may read stale or incorrect data. Non-repeatable reads may occur, and own writes may not be read, either! The solution to these common problems of a distributed system is to maintain consistency, i.e., keep the data aligned.
Moreover, maintaining consistency is crucial for ensuring that all nodes have a unified view of the data, which is essential for the correct functioning of distributed applications.
Definition
As per Merriam-Webster, consistency is defined as "agreement or harmony of parts or features to one another or a whole." While this definition may seem intuitive, with every context, consistency has a different meaning.
- When used in the context of transactions (ACID), it refers to the database being in a perceived good state. The good state definition is application-specific.
- In CAP theorem, it refers to linearizability, i.e., even if the system maintains multiple data copies, they appear as if there is a single copy — simply strong or atomic consistency.
- While managing large clusters, consistent core refers to a centralized approach for managing cluster membership and cluster metadata.
- With a replicated system, it denotes the replica states will converge to a common state sometime in the future, thus achieving eventual consistency.
- While rebalancing, consistent hashing refers to an approach for an even distribution of workload across partitions.
An article isn’t enough to cover all these variations. Thus, the main focus of this article will be on managing the consistency in distributed systems only.
Types of Consistency
Consistency requirements vary from system to system. Thus, it is imperative to understand the various types of it, along with associated trade-offs.
Strong Consistency or Linearizability
A system that applies an update immediately to each copy of data it maintains is deemed as strongly consistent. Thus, all reads, even from different nodes, will always return the latest update.
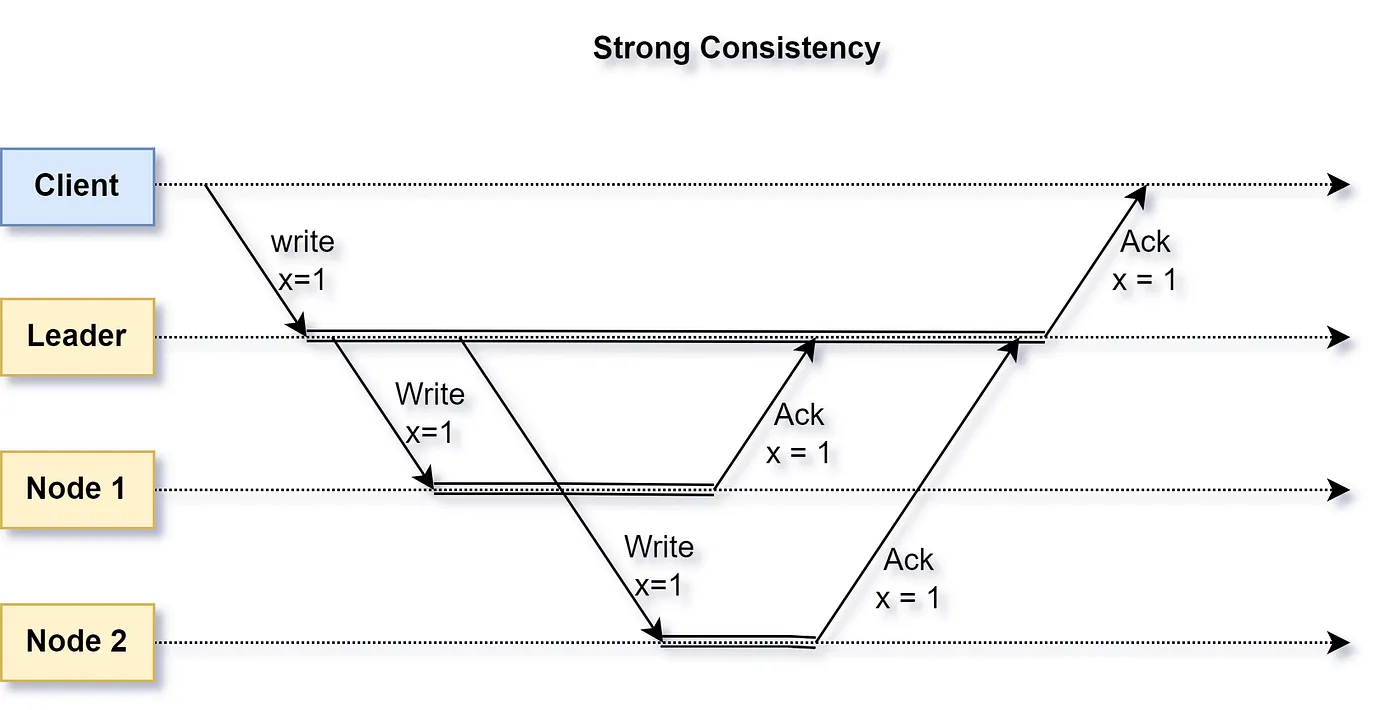
Figure 1: Strong Consistency (simplified view) where all updates are written immediately to every node
A strongly consistent system ensures total order, i.e., the sequence in which updates happen, even across different processes, is maintained.
- Usage: Strong consistency is typically employed in traditional RDBMS, banking/financial services, or whenever immediate data synchronization is required. Amazon Aurora and Microsoft Azure Cosmos DB are a few examples that provide strong consistency.
- Trade-offs: Strong consistency has low throughput and high latency since until all the copies are updated, a write isn’t acknowledged. They are resource-intensive and reduce system availability as any faults are cascaded and may block further updates until all nodes converge
- Implementation: Paxos and Two-Phase Commit (2PC) are widely used protocols for achieving strong consistency.
Sequential Consistency
Similar to a strongly consistent system, a system that applies an update immediately to each copy of data it maintains is deemed sequentially consistent when the update sequence within a process is guaranteed. Thus, all reads, even from different nodes, will always return the latest update.
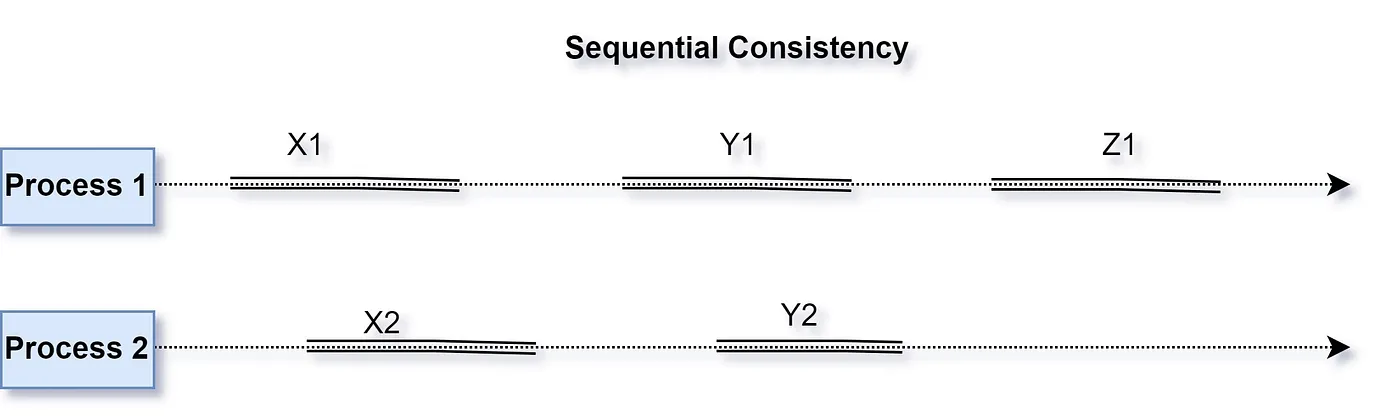
Even though X2 and Y2 were executed earlier to Z1, it may appear to be a different process that Z1 occurred before X2 or Y2 since order is maintained within a process and not across.
Since a sequential consistent system maintains the update sequence within a process only, it is weaker than a strongly consistent system. The order of updates arising from multiple processes is undefined or not maintained. Therefore, different processes may view the update order differently (Figure 2).
- Usage: Sequential consistency is typically employed in distributed file systems or consistent core, viz., coordination services to offer a sequential view of updates. Hadoop Distributed File Service (HDFS), Google Cloud Spanner, and Apache Zookeeper are a few examples that provide sequential consistency.
- Trade-offs: Sequential consistency has low throughput and high latency since concurrent updates may be blocked to maintain order. They are resource-intensive and reduce system availability as any faults are cascaded and may block further updates until all nodes converge.
- Implementation: Consensus algorithms viz. Paxos and Raft can be utilized to achieve sequential consistency.
Eventual Consistency
A system that applies an update only after an undefined finite lag to each copy of data it maintains is deemed as eventually consistent. Thus, reads from different nodes may or may not return the update immediately. However, once an update is applied across each copy, all reads will return the same updated data — provided there are no new updates to the data.
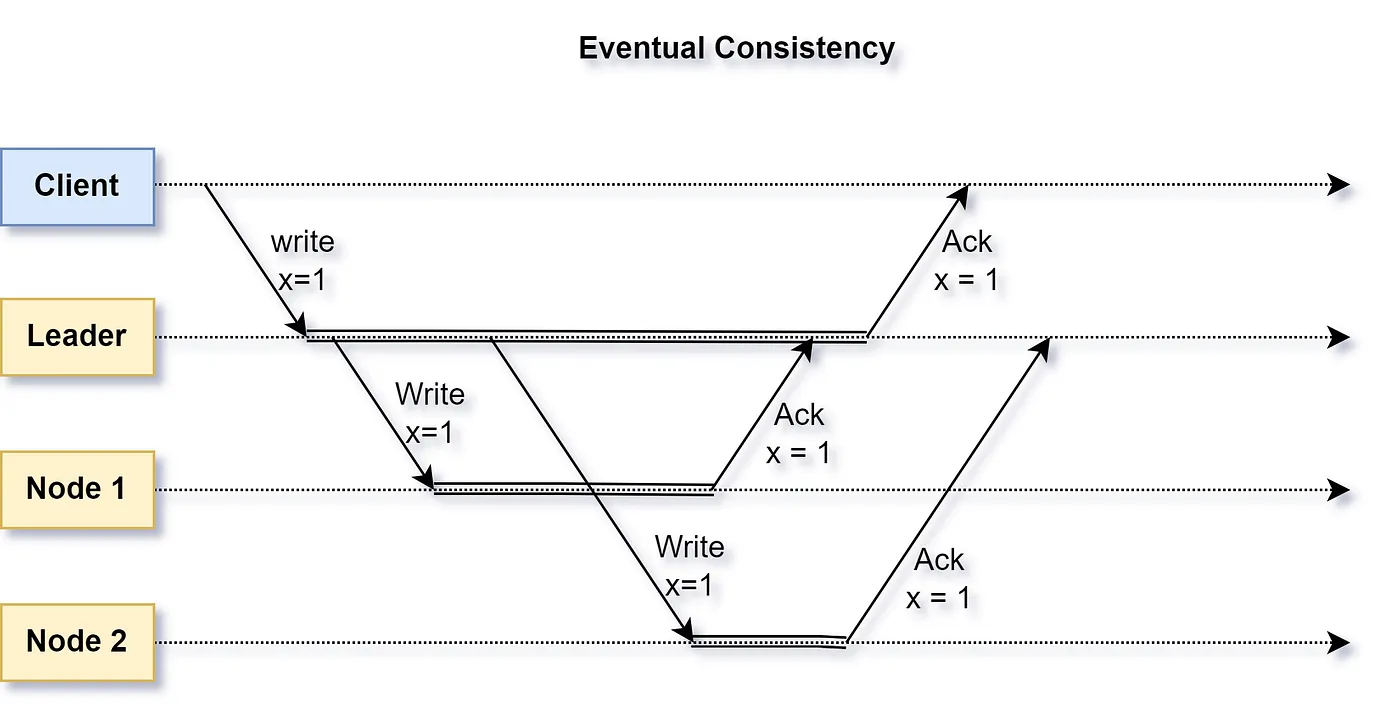
The write is deemed complete even if not all the nodes have acknowledged it. Thus, the client may see different values if the read happens from the node that has not yet acknowledged the write.
In eventually consistent systems, conflict resolution mechanisms such as last-write-wins, vector clocks, or user-defined conflict resolution policies are used to ensure data consistency.
- Usage: Eventual consistency is typically employed for social media posts and engagement, e-mails, search engine indexing, etc., or whenever a finite delay to data update is acceptable. Apache Cassandra, Riak, and Amazon Dynamo DB are a few examples that provide eventual consistency.
- Trade-offs: Although eventually, consistent systems provide low latency, high throughput, and high availability, it potentially leads to data conflicts, data inconsistency, data loss, and the inability to guarantee read-your-own-writes.
- Implementation: Eventual consistent system often employs Gossip protocols or Conflict-free Replicated Data type (CRDT).
Weak Consistency
A system that applies an update after an indefinite lag to each copy of data it maintains is deemed weakly consistent. Thus, all reads from different nodes may or may not return the update immediately.
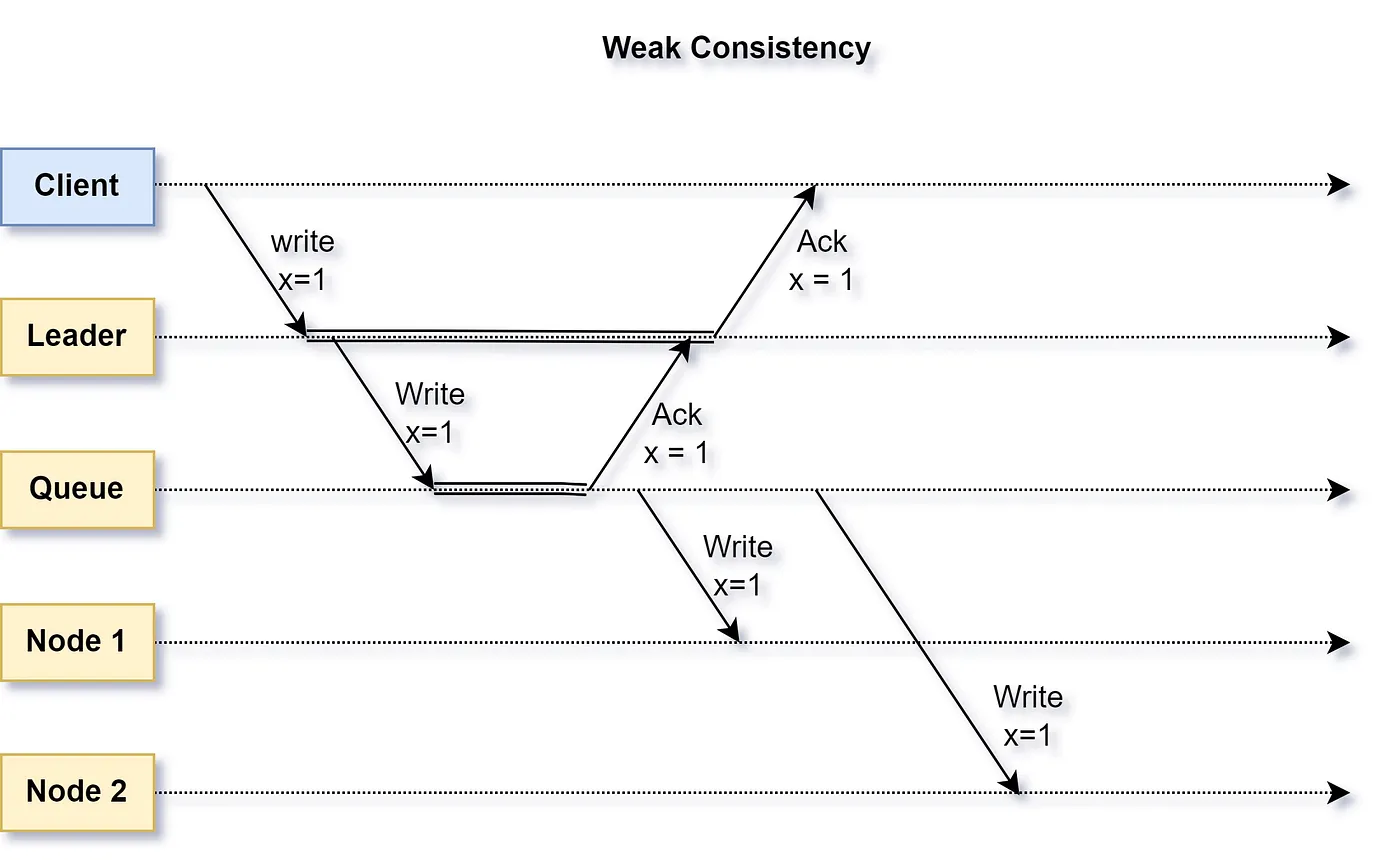
The subtle difference between eventual and weak consistency is that updates will be applied at some time in the future for eventual consistency, unlike updates that could be lost in the case of weak consistency.
- Usage: Weak consistency is typically employed in cache servers, live audio/video streaming, data backups, etc., or whenever potential data loss is acceptable, or there is no time duration requirement for the system to converge into a uniform state. Redis, Memcache, and CouchBase (via durability settings) offer weak consistency, too.
- Trade-offs: Although weakly consistent systems provide low latency, high throughput, and high availability, it has a high rate of data loss, data conflicts, and data inconsistencies.
- Implementation: Any system employing a write-back cache is weakly consistent by definition.
Causal Consistency
A system that applies updates ensuring the order in which they occurred to each copy of data it maintains is deemed as causally consistent. Although all reads from different nodes may or may not return the update immediately, the data is guaranteed to return in its causal order.
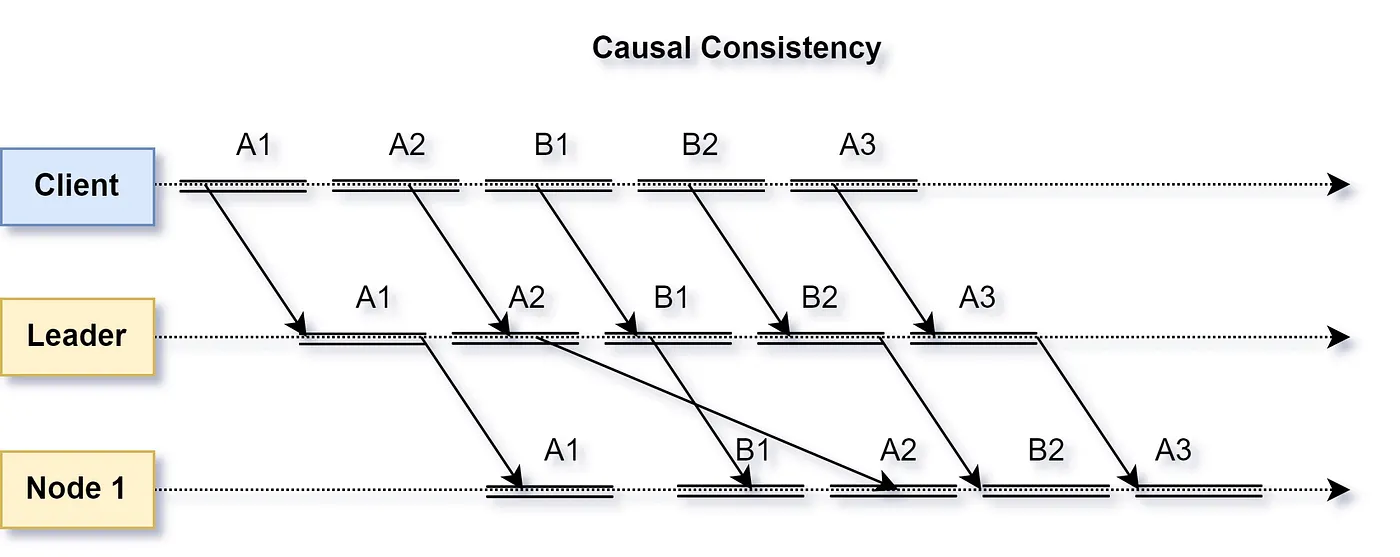
Considering causal order A1 -> A2 -> A3 and incomparable B1 -> B2, although the overall update sequence is not maintained while copying, the causal order of Ax and By is maintained across nodes.
Do note that a causally consistent system does not maintain a total order. Concurrent incomparable updates may still happen to be applied out of order. However, updates that are causally related will have their order maintained. Thus, a causal consistent system can be considered as partially ordered which guarantees only the happens-before relationship.
Causal consistency lies somewhere in between strong and eventual consistency.
- Usage: Causal consistency is particularly useful in collaborative applications, like shared document editors (e.g., Google Docs) and version control systems (e.g., Git) where the order of operations matters. Causal consistency is also employed in social media response, viz. replies on replies, real-time chat providers, etc. MongoDB, Neo4J, and Apache Kafka are a few examples that utilize causal consistency.
- Trade-offs: Although a causal consistent system provides low latency and high throughput (due to reduced overhead of synchronization), it still could have data loss and be unable to guarantee read-your-own-writes.
- Implementations: Utilizing logical clock viz. Lamport or Vector clock causal consistency can be achieved.
References and Further Reading
Consistency is a vast and diverse topic. Below are a few references used for this article and recommended reads to grasp more understanding of it.
- Consistency Models
- Designing Data-Intensive Applications by Martin Kleppmann
- Multiprocess program execution by Leslie Lamport
- Patterns of Distributed Systems by Unmesh Joshi
- Google Spanner — External Consistency
Future Trends
Here are a few speculative trends in consistency model evolution, which will likely be shaped by the evolving needs of distributed systems and advances in technology.
Hybrid Consistency
Systems may choose to employ a hybrid approach that allows flexibility to combine various models within a system. E.g. strong consistency for critical operations while using eventual consistency for non-critical operations.
For e.g., a banking system might use strong consistency for financial transactions to ensure accuracy and eventual consistency for logging and analytics data where immediate synchronization is not critical.
Context or Situation-Aware Consistency
Consistency models may become more context-aware, adapting to the specific needs of different applications, users, or scenarios.
Machine learning algorithms can analyze patterns in data access and update behavior to dynamically adjust consistency levels, thereby optimizing performance and minimizing conflicts.
Blockchain and Distributed Ledger
Blockchain technology may inspire new consistency models that leverage distributed ledger concepts.
These models can offer enhanced security, transparency, and tamper resistance, making them suitable for applications requiring high levels of trust and integrity.
Edge, Serverless, and Quantum Computing
To cater to the unique and specific needs of edge, serverless, and quantum computing, new consistency models may emerge. As these computing paradigms continue to grow, consistency models will need to adapt to the decentralized nature of edge computing, the stateless nature of serverless architectures, and the probabilistic nature of quantum computing.
Autonomous System
Autonomous systems, such as self-driving cars or drones, may require new consistency models that can handle rapid data synchronization across multiple sensors and decision-making units, ensuring that all components have a coherent view of the system state in real time.
Published at DZone with permission of Ammar Husain. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments