Cell-Based Architecture: Comprehensive Guide
Dive into cell-based architecture and explore foundational principles, real-world uses, benefits, challenges, and strategies for effective implementation.
Join the DZone community and get the full member experience.
Join For FreeOrigin of Cell-Based Architecture
In the rapidly evolving domain of digital services, the need for scalable and resilient architectures (the ability of the system to recover from a failure quickly) has peaked. The introduction of cell-based architecture marks a pivotal shift tailored to meet the surging demands of hyper-scaling (architecture's ability for rapid scaling in response to fluctuating demand). This methodology, essential for rapid scaling in response to fluctuating demands, has become the foundation for digital success. It's a strategy that empowers tech behemoths like Amazon and Facebook, along with service platforms such as DoorDash, to skillfully navigate the tidal waves of digital traffic during peak moments and ensure service to millions of users worldwide without a hitch.
Consider the surge Amazon faces on Prime Day or the global traffic spike Facebook navigates during significant events. Similarly, DoorDash's quest to flawlessly handle a flood of orders showcases a recurring theme: the critical need for an architecture that scales vertically and horizontally — expanding capacity without sacrificing system integrity or the user experience.
In the current landscape, where startups frequently encounter unprecedented growth rates, the dream of scaling quickly can become a nightmare of scalability issues. Hypergrowth — a rapid expansion that surpasses expectations — presents a formidable challenge, risking a company's collapse if it fails to scale efficiently. This challenge birthed the concept of hyperscaling, emphasizing an architecture's nimbleness in adapting and growing to meet dynamic demands. Essential to this strategy is extensive parallelization and rigorous fault isolation, ensuring companies can scale without succumbing to the pitfalls of rapid growth.
Cell-based architecture emerges as a beacon for applications and services where downtime is not an option. In scenarios where every second of inactivity spells significant reputational or financial loss, this architectural paradigm proves invaluable. It is especially crucial for:
- Applications requiring uninterrupted operation to ensure customer satisfaction and maintain business continuity.
- Financial services vital for maintaining economic stability.
- Ultra-scale systems where failure is an unthinkable option.
- Multi-tenant services requiring segregated resources for specific clients.
This architectural innovation was developed in direct response to the increasing need for modern, rapidly expanding digital services. It provides a scalable, resilient framework supporting continuous service delivery and operational superiority.
Understanding Cell-Based Architecture
What Exactly Is Cell-Based Architecture?
Cell-based architecture is a modern approach to creating digital services that are both scalable and resilient, taking cues from the principles of distributed systems and microservices design patterns. This architecture breaks down an extensive system into smaller, independent units called cells. Each cell is self-sufficient, containing a specific segment of the system's functionality, data storage, compute, application logic, and dependencies. This modular setup allows each cell to be scaled, deployed, and managed independently, enhancing the system's ability to grow and recover from failures without widespread impact.
Drawing an analogy to urban planning, consider cell-based architecture akin to a well-designed metropolis where each neighborhood operates autonomously, equipped with its services and amenities, yet contributes to the city's overall prosperity. In times of disruption, such as a power outage or a water main break, only the affected neighborhood experiences downtime while the rest of the city thrives. Just as a single neighborhood can experience disruption without paralyzing the entire city, a cell encountering an issue in this architectural framework does not trigger a system-wide failure. This ensures the digital service remains robust and reliable, maintaining high uptime and resilience.
Cell-based architecture builds scalable and robust digital services by breaking down an extensive system into smaller, independent units called cells. Each cell is self-contained with its own data storage and computing power similar to how neighborhoods work in a city. They operate independently, so if one cell has a problem, it doesn't affect the rest of the system. This design helps improve the system's stability and ability to grow without causing widespread issues.
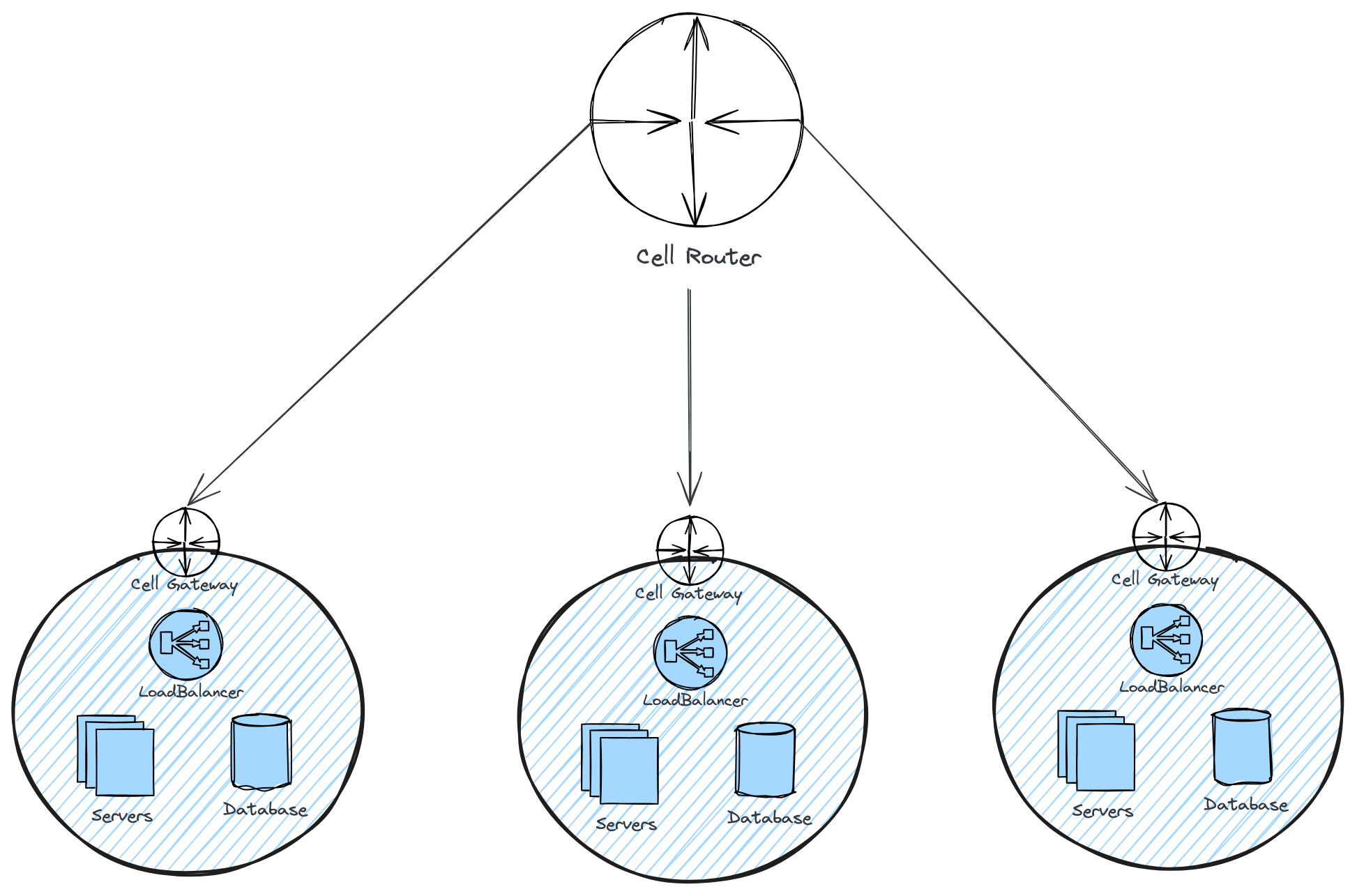
Fig. 1: Cell-Based Architecture
Key Components
- Cell: Akin to neighborhoods, cells are the foundational building blocks of this architecture. Each cell is an autonomous microservice cluster with resources capable of handling a subset of service responsibilities. A cell is a stand-alone version of the application with its own computing power, load balancer, and databases. This setup allows each cell to operate independently, making it possible to deploy, monitor, and maintain them separately. This independence means that if one cell runs into problems, it doesn't affect the others, which helps the system to scale effectively and stay robust.
- Cell Router: Cell Routers play a critical role similar to a city's traffic management system. They dynamically route requests to the most appropriate cell based on factors such as load, geographic location, or specific service requirements. By efficiently balancing the load across various cells, cell routers ensure that each request is processed by the cell best suited to handle it, optimizing system performance and the user experience, much like how traffic lights and signs direct the flow of vehicles to ensure smooth transit within a city.
- Inter-Cell Communication Layer: Despite the autonomy of individual cells, cooperation between them is essential for handling tasks across the system. The Inter-Cell Communication Layer facilitates secure and efficient message exchange between cells. This layer acts as the public transportation system of our city analogy, connecting different neighborhoods (cells) to ensure seamless collaboration and unified service delivery across the entire architecture. It ensures that even as cells operate independently, they can still work together effectively, mirroring how different parts of a city are connected yet function cohesively.
- Control Plane: The control plane is a critical component of cell-based architecture, acting as the central hub for administrative operations. It oversees tasks such as setting up new cells (provisioning), shutting down existing cells (de-provisioning), and moving customers between cells (migrating). This ensures that the infrastructure remains responsive to the system's and its users' needs, allowing for dynamic resource allocation and seamless service continuity.
Why and When to Use Cell-Based Architecture?
Why Use It?
Cell-based architecture offers a robust framework for efficiently scaling digital services, guaranteeing their resilience and adaptability during expansion. Below is a breakdown of its advantages:
- Higher Scalability: By defining and managing the capacity of each cell, you can add more cells to scale out (handle growth by adding more system components, such as databases and servers, and spreading the workload evenly). This avoids hitting the resource limits that come with scaling up (accommodating growth by increasing the size of a system's component, such as a database, server, or subsystem). As demand grows, you add more cells, each a contained unit with known capacities, making the system inherently scalable.
- Safer Deployments: Deployments and rollbacks are smoother with cells. You can deploy changes to one cell at a time, minimizing the impact of any issues. Canary cells can be used to test new deployments under actual conditions with minimal risk, providing a safety net for broader deployment.
- Easy Testability: Testing large, spread-out systems can be challenging, especially as they get bigger. However, with cell-based architecture, each cell is kept to a manageable size, making it much simpler to test how they behave at their largest capacity. Testing a whole big service can be too expensive and complex. However, testing just one cell is doable because you can simulate the most significant amount of work the cell can handle, similar to the most crucial job a single customer might give your application. This makes it practical and cost-effective to ensure each cell runs smoothly.
- Lower Blast Radius: Cell-based architecture limits the spread of failures by isolating issues within individual cells, much like neighborhoods in a city. This division ensures that a problem in one cell doesn't affect the entire system, maintaining overall functionality. Each cell operates independently, minimizing any single incident's impact area, or "blast radius," akin to the regional isolation seen in large-scale services. This setup enhances system resilience by keeping disruptions contained and preventing widespread outages.
![]() Fig. 2: Cell-based architecture services exhibit enhanced resilience to failures and feature a reduced blast radius compared to traditional services
Fig. 2: Cell-based architecture services exhibit enhanced resilience to failures and feature a reduced blast radius compared to traditional services - Improved Reliability and Recovery
- Higher Mean Time Between Failure (MTBF): Cell-based architecture increases the system's reliability by reducing how often problems occur. This design keeps each cell small and manageable, allowing for regular checks and maintenance, smoothing operations and making them more predictable. With customers distributed across different cells, any issues affect only a limited set of requests and users. Changes are tested on just a few cells at a time, making it easy to revert without widespread impact. For example, if you have customers divided across ten cells, a problem in one cell affects only 10% of your customers. This controlled approach to managing changes and addressing issues quickly means the system experiences fewer disruptions, leading to a more stable and reliable service.
- Lower Mean Time to Recovery (MTTR): Recovery is quicker and more straightforward with cells since you deal with a more minor, contained issue rather than a system-wide problem.
- Higher Availability: Cell-based architecture can lead to fewer and shorter failures, improving the overall uptime of your service. Even though there might be more potential points of failure (each cell could theoretically fail), the impact of each failure is significantly reduced, and they're easier to fix.
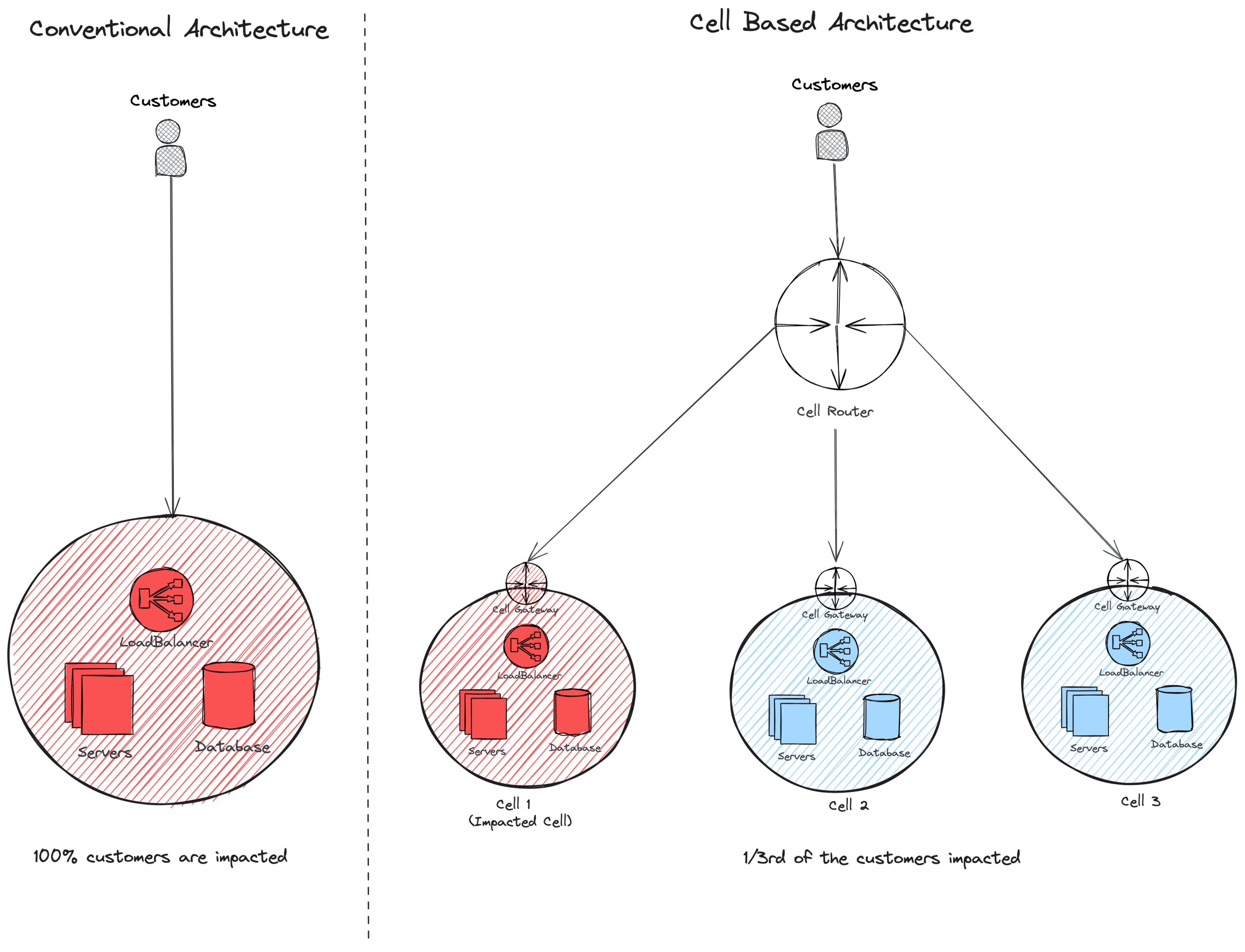 Fig. 2: Cell-based architecture services exhibit enhanced resilience to failures and feature a reduced blast radius compared to traditional services
Fig. 2: Cell-based architecture services exhibit enhanced resilience to failures and feature a reduced blast radius compared to traditional servicesWhen to Use It?
Here's a brief guide to help you understand when it's advantageous to use this architectural strategy:
- High-Stakes Applications: If downtime could severely impact your customers, tarnish your reputation, or result in substantial financial loss, a cell-based approach can safeguard against widespread disruptions.
- Critical Economic Infrastructure: Cell-based architecture ensures continuous operation for financial services industries (FSI), where workloads are pivotal to economic stability.
- Ultra-Scale Systems: Systems too large or critical to fail—those that must maintain operation under almost any circumstance—are prime candidates for cell-based design.
- Stringent Recovery Objectives: Cell-based architecture offers quick recovery capabilities for workloads requiring a Recovery Point Objective (RPO) of less than 5 seconds and a Recovery Time Objective (RTO) of less than 30 seconds.
- Multi-Tenant Services with Dedicated Needs: For services where tenants demand fully dedicated resources, assigning them their cell ensures isolation and dedicated performance.
Although cell-based architecture brings considerable benefits to handling critical workloads, it also comes with its own hurdles, such as heightened complexity, elevated costs, the necessity for specialized tools and practices, and the need for investment in a routing layer. For a more in-depth analysis of these challenges, please see the "Weighing the Scales: Benefits and Challenges."
Implementing Cell-Based Architecture
This section highlights critical design factors that come into play while designing and implementing a cell-based architecture.
Designing a Cell
Cell design is a foundational aspect of cell-based architecture, where a system is divided into smaller, self-contained units known as cells. Each cell operates independently with its resources, making the entire system more scalable and resilient.
To embark on cell design, identify distinct functionalities within your system that can be isolated into individual cells. This might involve grouping services by their operational needs or user base. Once you've defined these boundaries, equip each cell with the necessary resources, such as databases and application logic, to ensure it can function autonomously. This setup facilitates targeted scaling and recovery and minimizes the impact of failures, as issues in one cell won't spill over to others.
Implementing effective communication channels between cells and establishing comprehensive monitoring are crucial steps to maintain system cohesion and oversee cell performance. By systematically organizing your architecture into cells, you create a robust framework that enhances the manageability and adaptability of your system.
Here are a few ideas on cell design that can be leveraged to bolster system resilience:
- Distribute Cells Across Availability Zones: By positioning cells across different availability zones (AZs), you can protect your system against the failure of a single data center or geographic location. This geographical distribution ensures that even if one AZ encounters issues, other cells in different AZs can continue to operate, maintaining overall system availability and reducing the risk of complete service downtime.
- Implement Redundant Cell Configurations: Creating redundant copies of cells within and across AZs can further enhance resilience. This redundancy means that if one cell fails, its responsibilities can be immediately taken over by a duplicate cell, minimizing service disruption. This approach requires careful synchronization between cells to ensure data consistency but significantly improves fault tolerance.
- Design Cells for Autonomous Operation: Ensuring that each cell can operate independently, with its own set of resources, databases, and application logic, is crucial. This independence allows cells to be isolated from failures elsewhere in the system. Even if one cell experiences a problem, it won't spread to others, localizing the impact and making it easier to identify and rectify issues.
- Use Load Balancers and Cell Routers Strategically: Integrating load balancers and cell routers that are aware of cell locations and health statuses can help efficiently redirect traffic away from troubled cells or AZs. This dynamic routing capability allows for real-time adjustments to traffic flow, directing users to the healthiest available cells and balancing the load to prevent overburdening any single cell or AZ.
- Facilitate Easy Cell Replication and Deployment: Design cells with replication and redeployment in mind. In case of a cell or AZ failure, having mechanisms for quickly spinning up new cells in alternative locations can be invaluable. Automation tools and templates for cell deployment can expedite this process, reducing recovery times and enhancing overall system resilience.
- Regularly Test Failover Processes: Regular testing of cell failover processes, including simulated failures and recovery drills, can ensure that your system responds as expected during actual outages. These tests can reveal potential weaknesses in your cell design and failover strategies, allowing for continuous improvement of system resilience.
By incorporating these ideas into your cell design, you can create a more resilient system capable of withstanding various failure scenarios while minimizing the impact on service availability and performance.
Cell Partitioning
Cell partitioning is a crucial technique in cell-based architecture. It focuses on dividing a system's workload among distinct cells to optimize performance, scalability, and resilience. It involves categorizing and directing user requests or data to specific cells based on predefined criteria. This process ensures no cell becomes overwhelmed, enhancing system reliability and efficiency.
How Cell Partitioning Can Be Done:
- Identify Partition Criteria: Determine the basis for distributing workloads among cells. Typical criteria include geographic location, user ID, request type, or date range. This step is pivotal in defining how the system categorizes and routes requests to the appropriate cells.
- Implement Routing Logic: Develop a routing mechanism within the cell router or API gateway that uses the identified criteria to direct incoming requests to the correct cell. This might involve dynamic decision-making algorithms that consider current cell load and availability.
- Continuous Monitoring and Adjustment: Regularly monitor the performance and load distribution across cells. Use this data to adjust partitioning criteria and routing logic to maintain optimal system performance and scalability.
Partitioning Algorithms:
Several algorithms can be utilized for effective cell partitioning, each with its strengths and tailored to different types of workloads and system requirements:
- Consistent Hashing: Requests are distributed based on the hash values of the partition key (e.g., user ID), ensuring even workload distribution and minimal reorganization when cells are added or removed.
- Range-Based Partitioning: Divides data into ranges (e.g., alphabetical or numerical) and assigns each range to a specific cell. This is ideal for ordered data, allowing efficient query operations.
- Round Robin: This method distributes requests evenly across all available cells in a cyclic manner. It is straightforward and helpful in achieving a basic level of load balancing.
- Sharding: Similar to range-based partitioning but more complex, sharding involves splitting large databases into smaller, faster, more easily managed parts, or "shards," each handled by a separate cell.
- Dynamic Partitioning: Adjusts partitioning in real-time based on workload characteristics or system performance metrics. This approach requires advanced algorithms capable of analyzing system states and making immediate adjustments.
By thoughtfully implementing cell partitioning and choosing the appropriate algorithm, you can significantly enhance your cell-based architecture's performance, scalability, and resilience. Regular review and adjustment of your partitioning strategy ensures it continues to meet your system's evolving needs.
Implementing a Cell Router
In cell-based architecture, the cell router is crucial for steering traffic to the correct cells, ensuring efficient workload management and scalability. An effective cell router hinges on two key elements: traffic routing logic and failover strategies, which maintain system reliability and optimize performance.
Implementing Traffic Routing Logic: Start by defining the criteria for how requests are directed to various cells, including the users' geographic location, the type of request, and the specific services needed. The aim is to reduce latency and evenly distribute the load. Employ dynamic routing that adapts to cell availability and workload changes in real time, possibly through integration with a service discovery tool that monitors each cell's status and location.
Establishing Failover Strategies: Solid failover processes are essential for the cell router to ensure the system's dependability. Should any cell become unreachable, the router must automatically reroute traffic to the next available cell, requiring minimal manual intervention. This is achieved by implementing health checks across cells to swiftly identify and respond to failures, thus keeping the user experience smooth and the service highly available, even during cell outages.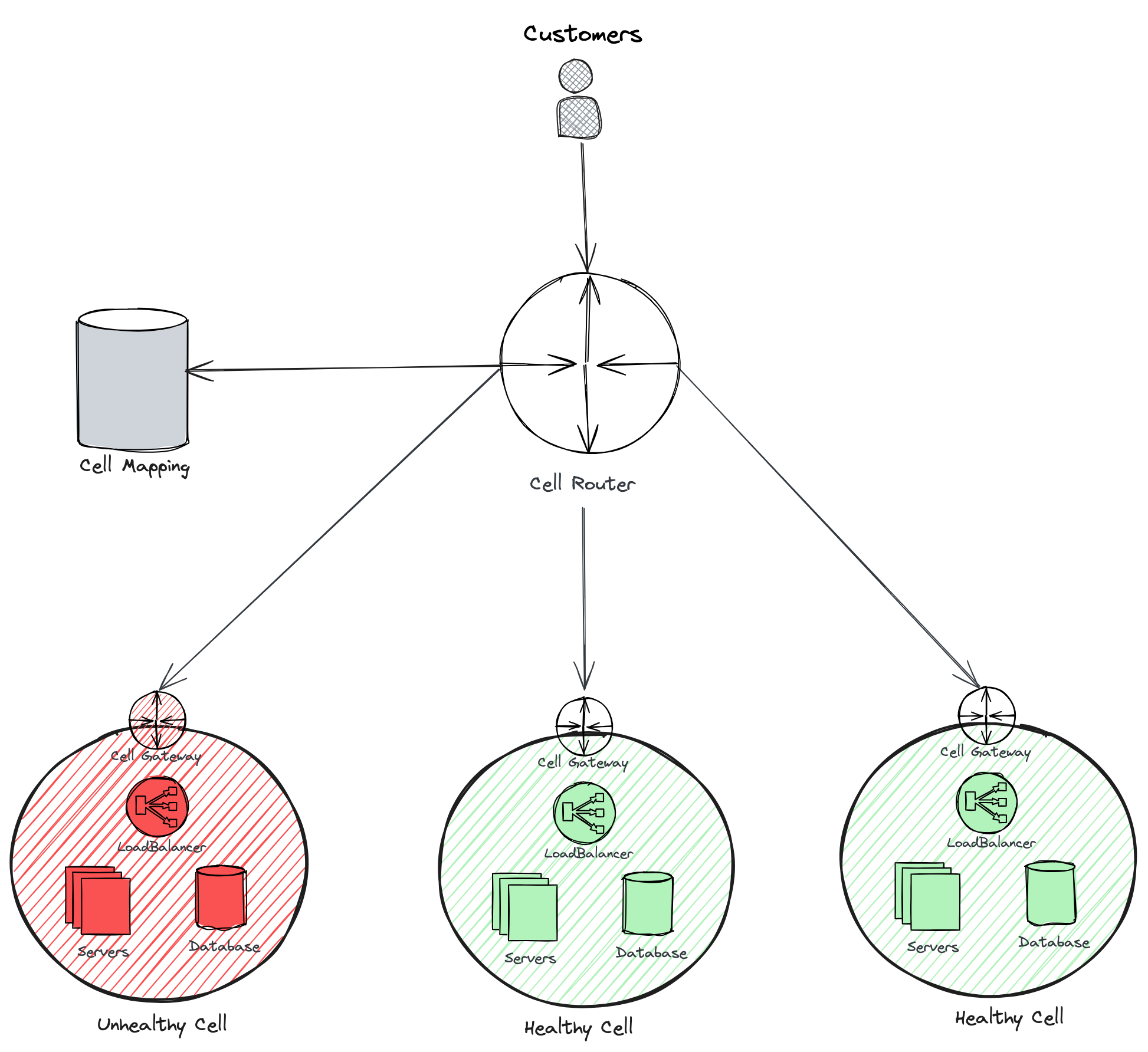
Fig 3. The cell router ensures a smooth user experience by redirecting traffic to healthy cells during outages, maintaining uninterrupted service availability
For the practical implementation of a cell router, you can take one of the following approaches:
- Load Balancers: Use cloud-based load balancers that dynamically direct traffic based on specific request attributes, such as URL paths or headers, according to set rules.
- API Gateways: An API gateway can serve as the primary entry for all incoming requests and route them to the appropriate cell based on configured logic.
- Service Mesh: A service mesh offers a network layer that facilitates efficient service-to-service communications and routing requests based on policies, service discovery, and health status.
- Custom Router Service: Developing a custom service allows routing decisions based on detailed request content, current cell load, or bespoke business logic, offering tailored control over traffic management.
Choosing the right implementation strategy for a cell router depends on specific needs, such as the granularity of routing decisions, integration capabilities with existing systems, and management simplicity. Each method provides varying degrees of control, complexity, and adaptability to cater to distinct architectural requirements.
Cell Sizing
Cell sizing in a cell-based architecture refers to determining each cell's optimal size and capacity to ensure it can handle its designated workload effectively without overburdening. Proper cell sizing is crucial for several reasons:
- Balanced Load Distribution: Correctly sized cells help achieve a balanced distribution of workloads across the system, preventing any single cell from becoming a bottleneck.
- Scalability: Well-sized cells can scale more efficiently. As demand increases, the system can add more cells or adjust resources within existing cells to accommodate growth.
- Resilience and Recovery: Smaller, well-defined cells can isolate failures more effectively, limiting the impact of any single point of failure. This makes the system more resilient and simplifies recovery processes.
- Cost Efficiency: Optimizing cell size helps utilize resources more efficiently, avoiding unnecessary expenditure on underutilized capacities.
How Cell Sizing Is Done?
Cell sizing involves a careful analysis of several factors:
- Workload Analysis: Understand the nature and volume of each cell's workload. This includes peak demand times, data throughput, and processing requirements.
- Resource Requirements: Based on the workload analysis, estimate the resources (CPU, memory, storage) each cell needs to operate effectively under various conditions.
- Performance Metrics: Consider key performance indicators (KPIs) that define successful cell operation. This could include response times, error rates, and throughput.
- Scalability Goals: Define how the system should scale in response to increased demand. This will influence whether cells should be designed to scale up (increase resources in a cell) or scale out (add more cells).
- Testing and Adjustment: Validate cell size assumptions by testing under simulated workload conditions. Monitoring real-world performance and adjusting as needed is a continuous part of cell sizing.
Effective cell sizing often involves a combination of theoretical analysis and empirical testing. Starting with a best-guess estimate based on workload characteristics and adjusting based on observed performance ensures that cells remain efficient, responsive, and cost-effective as the system evolves.
Cell Deployment
Cell deployment in a cell-based architecture is the process of distributing and managing your application's workload across multiple self-contained units called cells. This strategy ensures scalability, resilience, and efficient resource use. Here's a concise guide on how it's typically done and the technology choices available for effective implementation.
How Is Cell Deployment Done?
- Automated Deployment Pipelines: Start by setting up automated deployment pipelines. These pipelines handle your application's packaging, testing, and deployment to various cells. Automation ensures consistency, reduces errors, and enables rapid deployment across cells.
- Blue/Green Deployments: Use blue/green deployment strategies to minimize downtime and reduce risk. By deploying the new version of your application to a separate environment (green) while keeping the current version (blue) running, you can switch traffic to the latest version once it's fully ready and tested.
- Canary Releases: Gradually roll out updates to a small subset of cells or users before making them available system-wide. This allows you to monitor the impact of changes and roll them back if necessary without affecting all users.
Technology Choices for Cell Deployment:
- Container Orchestration Tools: Tools such as Kubernetes, AWS ECS, and Docker Swarm are crucial for orchestrating cell deployments, enabling the encapsulation of applications into containers for streamlined deployment, scaling, and management across various cells.
- CI/CD Tools: Continuous Integration and Continuous Deployment (CI/CD) tools such as Jenkins, GitLab CI, CircleCI, and AWS Pipeline facilitate the automation of testing and deployment processes, ensuring that new code changes can be efficiently rolled out.
- Infrastructure as Code (IaC): Tools like Terraform and AWS CloudFormation allow you to define your infrastructure in code, making it easier to replicate and deploy cells across different environments or cloud providers.
- Service Meshes: Service meshes like Istio or Linkerd provide advanced traffic management capabilities, including canary deployments and service discovery, which are crucial for managing communication and cell updates.
By leveraging these deployment strategies and technologies, you can achieve a high degree of automation and control in your cell deployments, ensuring your application remains scalable, reliable, and easy to manage.
Cell Observability
Cell observability is crucial in a cell-based architecture to ensure you have comprehensive visibility into each cell's health, performance, and operational metrics. It allows you to monitor, troubleshoot, and optimize the system effectively, enhancing overall reliability and user experience.
Implementing Cell Observability:
To achieve thorough cell observability, focus on three key areas: logging, monitoring, and tracing. Logging captures detailed events and operations within each cell. Monitoring tracks key performance indicators and health metrics in real time. Tracing follows requests as they move through the cells, identifying bottlenecks or failures in the workflow.
Technology Choices for Cell Observability:
- Logging Tools: Solutions like Elasticsearch, Logstash, Kibana (ELK Stack), or Splunk provide powerful logging capabilities, allowing you to aggregate and analyze logs from all cells centrally.
- Monitoring Solutions: Prometheus, coupled with Grafana for visualization, offers robust monitoring capabilities with support for custom metrics. Cloud-native services like Amazon CloudWatch or Google Operations (formerly Stackdriver) provide integrated monitoring solutions tailored for applications deployed on their respective cloud platforms.
- Distributed Tracing Systems: Tools like Jaeger, Zipkin, and AWS XRay enable distributed tracing, helping you to understand the flow of requests across cells and identify latency issues or failures in microservices interactions.
- Service Meshes: Service meshes such as Istio or Linkerd inherently offer observability features, including monitoring, logging, and tracing requests between cells without requiring changes to your application code.
By leveraging these tools and focusing on comprehensive observability, you can ensure that your cell-based architecture remains performant, resilient, and capable of supporting your application's dynamic needs.
Weighing the Scales: Benefits and Challenges
Adopting Cell-Based Architecture transforms the structural and operational dynamics of digital services. Breaking down a service into independently scalable and resilient units (cells) offers a robust framework for managing complexity and ensuring system availability. However, this architectural paradigm also introduces new challenges and complexities. Here's a deeper dive into the technical advantages and considerations.
Benefits
- Horizontal Scalability: Unlike traditional scale-up approaches, Cell-Based Architecture enables horizontal scaling by adding more cells. This method alleviates common bottlenecks associated with centralized databases or shared resources, allowing for linear scalability as user demand increases.
- Fault Isolation and Resilience: The architecture's compartmentalized design ensures that failures are contained within individual cells, significantly reducing the system's overall blast radius. This isolation enhances the system's resilience, as issues in one cell can be mitigated or repaired without impacting the entire service.
- Deployment Agility: Leveraging cells allows for incremental deployments and feature rollouts, akin to implementing rolling updates across microservices. This granularity in deployment strategy minimizes downtime and enables a more flexible response to market or user demands.
- Simplified Operational Complexity: While the initial setup is complex, the ongoing operation and management of cells can be more straightforward than monolithic architectures. Each cell's autonomy simplifies monitoring, troubleshooting, and scaling efforts, as operational tasks can be executed in parallel across cells.
Challenges (Considerations)
- Architectural Complexity: Transitioning to or implementing Cell-Based Architecture demands a meticulous design phase, focusing on defining cell boundaries, data partitioning strategies, and inter-cell communication protocols. This complexity requires a deep understanding of distributed systems principles and may necessitate a development and operational practices shift.
- Resource and Infrastructure Overhead (Higher Cost): Each cell operates with its set of resources and infrastructure, potentially leading to increased overhead compared to shared-resource models. Optimizing resource utilization and cost-efficiency becomes paramount, especially as the number of cells grows.
- Inter-Cell Communication Management: Ensuring coherent and efficient communication between cells without introducing tight coupling or significant latency is a critical challenge. Developers must design a communication layer that supports the necessary interactions while maintaining cells' independence and avoiding performance bottlenecks.
- Data Consistency and Synchronization: Maintaining data consistency across cells, especially in scenarios requiring global state or real-time data synchronization, adds another layer of complexity. Implementing strategies like event sourcing, CQRS (Command Query Responsibility Segregation), or distributed sagas may be necessary to address these challenges.
- Specialized Tools and Practices: Operating a cell-based architecture requires specialized operational tools and practices to effectively manage multiple instances of workloads.
- Routing Layer Investment: A robust cell routing layer is essential for directing traffic appropriately across cells, necessitating additional investment in technology and expertise.
Navigating the Trade-offs
Opting for Cell-Based Architecture involves navigating these trade-offs and evaluating whether scalability, resilience, and operational agility benefits outweigh the complexities of implementation and management. It is most suitable for services requiring high availability, those undergoing rapid expansion, or systems where modular scaling and failure isolation are critical.
Best Practices and Pitfalls
Best Practices
Adopting a cell-based architecture can significantly enhance the scalability and resilience of your applications. Here are streamlined best practices for implementing this approach effectively:
Begin With a Solid Foundation
- Treat Your Current Setup as Cell Zero: Viewing your existing system as the initial cell, gradually introducing traffic routing and distribution across new cells.
- Launch with Multiple Cells: Implement more than one cell from the beginning to quickly learn and adapt to the operational dynamics of a cell-based environment.
Plan for Flexibility and Growth
- Implement a Cell Migration Mechanism Early: Prepare for the need to move customers between cells, ensuring you can scale and adjust without disruption.
Focus on Reliability
- Conduct a Failure Mode Analysis: Identify and assess potential failures within each cell and their impact, developing strategies to ensure robustness and minimize cross-cell effects.
Ensure Independence and Security
- Maintain Cell Autonomy: Design cells to be self-sufficient, with dedicated resources and clear ownership, possibly by a single team.
- Secure Communication: Use versioned, well-defined APIs for cell interactions and enforce security policies at the API gateway level.
- Minimize Dependencies: Keep inter-cell dependencies low to preserve the architecture's benefits, such as fault isolation.
Optimize Deployment and Operations
- Avoid Shared Resources: Each cell should have its data storage to eliminate global state dependencies.
- Deploy in Waves: Introduce updates and deployments in phases across cells for better change management and quick rollback capabilities.
By following these practices, you can leverage cell-based architecture to create scalable, resilient, but also manageable, and secure systems ready to meet the challenges of modern digital demands.
Common Pitfalls
While cell-based architecture offers significant advantages for scalability and resilience, it also introduces specific challenges and pitfalls that organizations need to be aware of when adopting this approach:
Complexity in Management and Operations
- Increased Operational Overhead: Managing multiple cells can introduce complexity in deployment, monitoring, and operations, requiring robust automation and orchestration tools to maintain efficiency.
- Consistency Management: Ensuring data consistency across cells, especially in stateful applications, can be challenging and might require sophisticated synchronization mechanisms.
Initial Setup and Migration Challenges
- Complex Migration Process: Transitioning to a cell-based architecture from a traditional setup can be complex, requiring careful planning to avoid service disruption and data loss.
- Steep Learning Curve: Teams may face a learning curve in understanding cell-based concepts and best practices, necessitating training and potentially slowing initial progress.
Design and Architectural Considerations
- Cell Isolation: Properly isolating cells to prevent failure propagation requires meticulous design, failing which the system might not fully realize the benefits of fault isolation.
- Optimal Cell Size: Determining the optimal size for cells can be tricky, as overly small cells may lead to inefficiencies, while huge cells might compromise scalability and resilience.
Resource Utilization and Cost Implications
- Potential for Increased Costs: If not carefully managed, the duplication of resources across cells can lead to increased operational costs.
- Underutilization of Resources: Balancing resource allocation to prevent underutilization while avoiding over-provisioning requires continuous monitoring and adjustment.
Networking and Communication Overhead
- Network Complexity: The cell-based architecture may introduce additional network complexity, including the need for sophisticated routing and load-balancing strategies.
- Inter-Cell Communication: Ensuring efficient and secure communication between cells, especially in geographically distributed setups, can introduce latency and requires safe, reliable networking solutions.
Security and Compliance
- Security Configuration: Each cell's need for individual security configurations can complicate enforcing consistent security policies across the architecture.
- Compliance Verification: Verifying that each cell complies with regulatory requirements can be more challenging in a distributed architecture, requiring robust auditing mechanisms.
Scalability vs. Cohesion Trade-Off
- Dependency Management: While minimizing dependencies between cells enhances fault tolerance, it can also lead to challenges in maintaining application cohesion and consistency.
- Data Duplication: Avoiding shared resources may result in data duplication and synchronization challenges, impacting system performance and consistency.
Organizations should invest in robust planning, adopt comprehensive automation and monitoring tools, and ensure ongoing team training to mitigate these pitfalls. Understanding these challenges upfront can help design a more resilient, scalable, and efficient cell-based architecture.
Cell-Based Wins in the Real World
Cell-based architecture has become essential for managing scalability and ensuring system resilience, from high-growth startups to tech giants like Amazon and Facebook. This architectural model has been adopted across various industries, reflecting its effectiveness in handling large-scale, critical workloads. Here's a brief look at how DoorDash and Slack have implemented cell-based architecture to address their unique challenges.
DoorDash's Transition to Cell-Based Architecture
Faced with the demands of hypergrowth, DoorDash migrated from a monolithic system to a cell-based architecture, marking a pivotal shift in its operational strategy. This transition, known as Project SuperCell, was driven by the need to efficiently manage fluctuating demand and maintain consistent service reliability across diverse markets. By leveraging AWS's cloud infrastructure, DoorDash was able to isolate failures within individual cells, preventing widespread system disruptions. It significantly enhanced their ability to scale resources and maintain service reliability, even during peak times, demonstrating the transformative potential of adopting a cell-based approach.
Slack's Migration to Cell-Based Architecture
Slack underwent a major shift to a cell-based architecture to lessen the impact of gray failures and boost service redundancy. Prompted by a review of a network outage, this move revealed the risks of depending solely on a single availability zone. The new cellular structure aims to confine failures more effectively and minimize the extent of potential site outages. With the adoption of isolated services in each availability zone, Slack has enabled its internal services to function independently within each zone, curtailing the fallout from outages and speeding up the recovery process. This significant redesign has markedly improved Slack's system resilience, underscoring cell-based architecture's role in ensuring high service availability and quality.
Roblox's Strategic Shift to Cellular Infrastructure
Roblox's shift to a cell-based architecture showcases its response to rapid growth and the need to support over 70 million daily active users with reliable, low-latency experiences. Roblox created isolated clusters within their data centers by adopting a cellular infrastructure, enhancing system resilience through service replication across cells. This setup allowed for the deactivation of non-functional cells without disrupting service, effectively containing failures. The move to cellular infrastructure has significantly boosted Roblox's system reliability, enabling the platform to offer always-on, immersive experiences worldwide. This strategy highlights the effectiveness of cell-based architecture in managing large-scale, dynamic workloads and maintaining high service quality as platforms expand.
These examples from DoorDash, Slack, and Roblox illustrate the strategic value of cell-based architecture in addressing the challenges of scale and reliability. By isolating workloads into independent cells, these companies have achieved greater scalability, fault tolerance, and operational efficiency, showcasing the effectiveness of this approach in supporting dynamic, high-demand services.
Key Takeaways
Cell-based architecture represents a transformative approach for organizations aiming to achieve hyper-scalability and resilience in the digital era. Companies like Amazon, Facebook, DoorDash, and Slack have demonstrated their efficacy in managing hypergrowth and ensuring uninterrupted service by segmenting systems into independent, self-sufficient cells.
This architectural strategy facilitates dynamic scaling and robust fault isolation and demands careful consideration of increased complexity, resource allocation, and the need for specialized operational tools. As businesses continue to navigate the demands of digital growth, the adoption of cell-based architecture emerges as a strategic solution for sustaining operational integrity and delivering consistent user experiences amidst the ever-evolving digital landscape.
Acknowledgments
This article draws upon the collective knowledge and experiences of industry leaders and practitioners, including insights from technical blogs, case studies from companies like Amazon, Slack, and Doordash, and contributions from the wider tech community.
References
- https://docs.aws.amazon.com/wellarchitected/latest/reducing-scope-of-impact-with-cell-based-architecture/reducing-scope-of-impact-with-cell-based-architecture.html
- https://github.com/wso2/reference-architecture/blob/master/reference-architecture-cell-based.md
- https://newsletter.systemdesign.one/p/cell-based-architecture
- https://highscalability.com/cell-architectures/
- https://www.youtube.com/watch?v=ReRrhU-yRjg
- https://slack.engineering/slacks-migration-to-a-cellular-architecture/
- https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
Opinions expressed by DZone contributors are their own.
Comments