Key Considerations When Implementing Virtual Kubernetes Clusters
In this article, readers will receive key considerations to examine when implementing virutal Kubernetes clusters, along with essential questions and answers.
Join the DZone community and get the full member experience.
Join For FreeIn a Kubernetes context, multi-tenancy refers to sharing one large cluster among multiple teams, applications, or users primarily in lower environments such as development and testing—mainly to reduce cost and operational overhead around managing many clusters. Multi-tenancy is becoming an essential requirement for platform teams deploying Kubernetes infrastructure.
Achieving Multi-Tenancy Using Kubernetes Namespaces
By far, the most popular approach to achieve multi-tenancy is by using Kubernetes namespaces. Kubernetes namespaces provide an easy way to divide a set of resources, such as pods, services, and deployments, which are only accessible within that namespace.
Platform teams usually manage and operate the clusters and have full cluster-level permissions. They accomplish multi-tenancy by creating one or more namespaces specific to each team/application/user and restricting access to those namespaces for end users who are developers, DevOps engineers, and application owners. End users can only perform operations that are specific to the namespaces they have ownership of. This works well for the vast majority of multi-tenancy use cases; however, there is one corner use case when the vcluster framework can be useful.
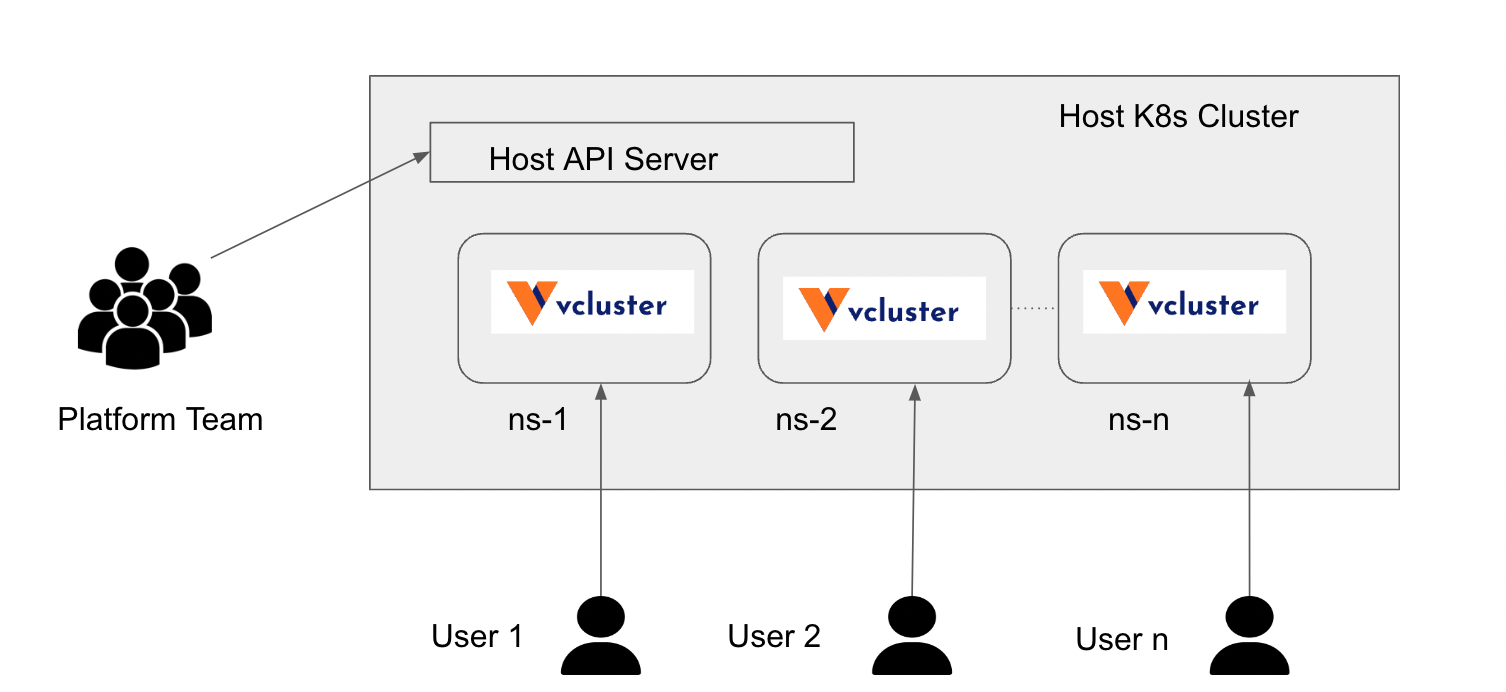
Multi-Tenancy Using the Vcluster Open-Source Framework
Restricting end users’ access only to namespaces does not work in some corner cases where the end users need access to cluster-scope objects such as CRDs, ingress controllers, cluster API servers, etc., for their day-to-day development work. Typically, cluster-level access is needed for end users who are involved in developing custom resources and custom controllers to extend Kubernetes API, admission controllers to implement mutating and validating webhooks, and other services that might require custom Kubernetes configuration. Virtual Cluster (Vcluster) is an open-source framework that aims to solve this problem. Vcluster is essentially a virtual cluster that can be created in a physical cluster.
Vcluster installs a K3s cluster by default (k0s, k8s, and EKS optionally) in a namespace of the host cluster for every vcluster instance and installs the core Kubernetes components such as API server, controller manager, storage backend, and optionally, a scheduler. End users interact with the virtual cluster API server and get full access to the virtual cluster, still maintaining resource isolation and security as they are restricted to the host namespaces and don’t have access to the host cluster API server. Platform teams create a namespace in the host cluster, configure resource quotas and policies for the host namespace, create a vcluster instance, and hand over the virtual cluster to the end users.
Key Questions to Answer Before Deploying Vclusters
While deploying vcluster for a small group of end users is fairly simple, platform teams must ask themselves the following questions and implement additional solutions around vcluster to meet their organization’s automation, security, governance, and compliance requirements before making large-scale vcluster deployments:
How do you create host-level namespaces and resource quotas for each namespace and map it with internal users/teams?
- Platform teams still need a solution for namespace-level multi-tenancy, as host namespaces must be created first for deploying vcluster instances.
How do you automate the lifecycle management of vcluster for large-scale usage?
- Platform teams need to solve for things like creation/modification/deletion of vcluster instances, exposing the vcluster API server to end users (using ingress or load balancers), securely distributing vcluster Kubeconfig files to end users, and upgrading vcluster instances (K3s) for software updates and security vulnerabilities.
How do you ensure only approved and mandated cluster-wide services are running in each vcluster? Do you deploy them in every vcluster? How do you guarantee there is no drift?
- These services typically include security plugins, logging, monitoring, service mesh, ingress controllers, storage plugins, etc.
How do you create network policies at the namespace level for the host namespaces?
- This level of network isolation is still needed as the physical cluster may be shared among multiple BUs and application teams—requiring network isolation among host namespaces.
How do you enforce security policies such as OPA in each vcluster? Do you deploy these policies in every vcluster?
- Most of the platform teams standardize a set of security policies based on the recommendations from their security teams and deploy them in every cluster to maintain security posture even in lower environments.
How do you retrieve Kubectl audit logs for each vcluster?
- For some organizations, Kubectl audit is a key requirement, even in lower environments.
How do you handle cost allocation?
- Since the resources are shared by different development teams, they may belong to different cost centers and platform teams need to implement the appropriate chargeback policies for cost allocation.
How do you make other developer tools like ArgoCD work with vcluster?
- GitOps tools like ArgoCD require cluster access for application deployment, so each vcluster instance must be configured in the ArgoCD for end users to leverage ArgoCD GitOps deployment. This may apply to other common tools such as observability, logging, and monitoring tools.
What kind of additional resource and operational overhead do you incur with every vcluster instance?
- Each vcluster essentially is a K3s/K8s cluster with all the add-ons, such as your security plugins, logging plugins, monitoring plugins, ingress controllers, etc. These per vcluster Kubernetes resources and the add-ons can potentially incur substantial overhead as you deploy more vcluster instances. Similarly, since each vcluster essentially is a Kubernetes cluster, platform teams may incur additional overhead managing these clusters for Kubernetes version updates, patch management, and add-on management.
Does the vcluster match your real production environment?
- For some organizations, it’s important that the development environment closely matches the production environment. Vcluster supports other distributions such as K8s and EKS, but platform teams must check whether it’s equivalent to running a standalone cluster for the use cases that require near-production environments. For instance, EKS supports many advanced features, including third-party CNIs, various storage classes, auto-scaling, IRSA, and add-ons, which may not be available in the virtual EKS clusters.
Conclusion
For most platform teams, multi-tenancy based on namespaces with additional automation around namespace life cycle management, security, and cost control solves their multi-tenancy use cases. Vcluster addresses a specific gap in Kubernetes namespace multi-tenancy whereby end users that don’t have cluster-level privileges can now access cluster-scoped objects within their virtual cluster. Platform teams must internally validate whether there is such a requirement for their end users, do a thorough cost-benefit analysis taking their security, compliance, and governance requirements into consideration, and implement additional automation around it to ensure it’s enterprise-ready before deployment.
Opinions expressed by DZone contributors are their own.
Comments