Comparing SQL and SPL: Order-Based Computations
See how SQL and SPL compare when it comes to order-based computations in this in-depth review of both using stock prices.
Join the DZone community and get the full member experience.
Join For FreeⅠ. Reference of a neighboring record
This is the type of common and simple order-based calculations. When records are sorted in a specific order, a neighboring record reference references a neighboring record during a calculation. Below are some examples:
1. Calculate the daily growth rate of a specific stock’s closing prices (link relative ratio).
Sort records by date and reference the closing price on the previous date.
2. Calculate the average stock price in three days, which are the previous day, the current day and the next day (moving average).
Sort records by date and reference the closing price on the previous date and on the next date.
3. Based on records of multiple stocks, calculate the growth rate on each date for each stock. (Intra-group link relative ratio).
Group records by stock, sort records by date in each group and reference the closing price in the previous date.
Let’s first look at how SQL handles these order-based computing scenarios through several examples.
1. SQL solutions
SQL solution in its earlier days
Early SQL does not have window functions. To achieve the neighboring record reference, the language uses JOIN to joins up the neighboring records into one row.
Below is the script for task 1written in earlier SQL:
SELECT day, curr.price/pre.price rate
FROM (
SELECT day, price, rownum row1
FROM tbl ORDER BY day ASC) curr
LEFT JOIN (
SELECT day, price, rownum row2
FROM tbl ORDER BY day ASC) pre
ON curr.row1=pre.row2+1We self-joins the source table where the current date matches and the previous date plus 1 to combine the stock price in the previous date and the one in the current date into one row. Then we calculate the growth rate through an intra-row calculation. The nested query is needed for such a simple task.
For task 2, where the moving average of the stock prices in three days (which is (stock price of the previous date + that of the current date + that of the next date)/3) is calculated through a JOIN operation:
SELECT day, (curr.price+pre.price+after.price)/3 movingAvg
FROM (
SELECT day, price, rownum row1
FROM tbl ORDER BY day ASC) curr
LEFT JOIN (
SELECT day, price, rownum row2
FROM tbl ORDER BY day ASC) pre
ON curr.row1=pre.row2+1
LEFT JOIN (
SELECT day, price, rownum row3
FROM tbl ORDER BY day ASC) after
ON curr.row1=after.row3-1To retrieve the record of the date requires another JOIN of a nested query. If you need to calculate the moving average from 10 days ago to 10 days later, there will be twenty JOINs. It’s horrible.
Task 3 is the most complicated one. The source table includes multiple stocks, so we add a code field to differentiate the stocks. The daily growth rate is calculated within a group containing records of the same stock:
SELECT code, day ,currPrice/prePrice rate
FROM(
SELECT code, day, curr.price currPrice, pre.price prePrice
FROM (
SELECT code, day, price, rownum row1
FROM tbl ORDER BY code, day ASC) curr
LEFT JOIN (
SELECT code, day, price, rownum row2
FROM tbl ORDER BY code, day ASC) pre
ON curr.row1=pre.row2+1 AND curr.code=pre.code
)There are two points we need to pay special attention to. First, when sorting a single table, we should add a stock code field to perform the sort according to the composite condition code, day, where the code field must be put ahead. This is because we should put records of the same stock together and then sort them by date in the group. Second, after records are sorted, we should also define that the current code and the previous code are equal in the joining condition. If we do not do so, the growth rate will be calculated between two records of different codes. That will generate useless data.
After Window Functions Are Introduced
SQL:2003 standard introduced window functions to add the concept of order to the language. That has facilitated the order-based calculations. To achieve the above three tasks, we have simpler scripts.
The following code calculates the relative link ratio in task 1. For the convenience of viewing and understanding, we split the window function into multiple indented lines:
SELECT day, price /
LAG(price,1)
OVER (
ORDER BY day ASC
) rate
FROM tblLAG function references the previous record. The parameter enables getting the price in the directly previous record. OVER is the window function’s subquery (each window function has their own OVER subquery). The subquery is to define the to-be-analyzed ordered set. Here it is a simple case because the to-be-analyzed set is already ordered by date.
To calculate the moving average in task 2, we can use LAG+ function to get records before the current record and LEAD function to get records after the current record. The following query uses AVG function, which is better because it supports calculating the average within a range (like between the previous 10 to the next 10). The LAG/LEAD functions, however, get only one value at a time:
SELECT price,
AVG(price) OVER (
ORDER BY day ASC
RANGE BETWEEN 1 PRECEDING AND 1 FOLLOWING
) movingAvg
FROM tbl;It becomes easy to get top/bottom N. We just need to change the value defined in RANGE BETWEEN.
To perform the intra-group order-based calculation in task 3, where all records of closing prices of one stock is put into the same group, we use the window function:
SELECT code, day, price /
LAG(price,1)
OVER (
PARTITION BY code
ORDER BY day ASC
) rate
FROM tblThe PARTITION BY subquery under OVER statement describes how records will be divided, and the LAG operation is limited in each group. This is much more intuitive than JOIN. JOIN’s way is to sort records by combining records of the same attribute, which has the effect of performing grouping but is difficult to understand.
2. SPL Solution
SPL has the following script to handle task 1:

A1: Import stock data table from the source file.
A2: Sort records by date using sort function and calculate the growth rate of each day compared with the previous day. The expression price[-1] represents the price in the previous day. derive function is used to add a calculated field to the table sequence.
SPL also supports retrieving a data table from the database. A1 in the above script can be modifies as follows:

A1’s result is a table sequence. A SPL table sequence is an ordered set, where members are arranged in a specific order. Like the array in Java and other high-level languages, users can access members in a SPL ordered set through their sequence numbers, which is the ordered set’s basic feature and its natural advantage in handling order-based computing tasks. To access data in the previous transaction date in SQL requires the use the subquery or the window function, making the script complicated. With an ordered set, we just need to access the member directly previous to (represented by syntax -1) the member corresponding to the current sequence number. It is efficient and easy to understand.
Let’s move on to look at SPL solutions to task 2 and task 3. Below is for task 2:

Import the stock data table and sort it by date; calculate the moving stock price average in the three days of the current, the previous and the next. The expression price[-1:1] represents closing prices from the previous date to the next date.
Below is for task 3:

Import the stock data table and sort it by date. The group function groups the table by stock code. For each stock record, calculate the growth rate of the closing price compared with the previous date. The tilde sign ~ is used to represent the current member.
SPL accesses a neighboring record still by the relative sequence number in handling the two tasks. The way of thinking is similar to that used to handle task 1. In task 2, a continuous three days is accessed. In task 3, there are multiple stocks and SPL first groups them by code.
Ⅱ.Position-based location
1. SQL solution
To access a neighboring record in an ordered set is the relative-position-based location operation. But to calculate the difference between the closing price of each day and the list price is the absolute-position-based location:
SELECT day, price-FIRST_VALUE(price) OVER (ORDER BY day ASC) FROM tbl
Another example of same type is to calculate the difference between each day’s closing price and the highest closing price that appears in the 10th date:
SELECT day, price-NTH_VALUE(price,10)OVER (ORDER BY day ASC) FROM tbl
The complicated scenario is that the sequence number to be located is unknown and needs to be calculated:
Sort Stock Records by Closing Price and Get the Stock Price in the Middle Position (Median)
First, let’s look at how to handle such a scenario when there is a single stock. After records are sorted by closing price, we need to calculate the middle position according to the number of records:
SELECT *
FROM
SELECT day, price, ROW_NUMBER()OVER (ORDER BY day ASC) seq FROM tbl
WHERE seq=(
SELECT TRUNC((COUNT(*)+1)/2) middleSeq FROM tbl)The subquery under FROM statement uses ROW_NUMBER() to generate a sequence number for each record. The subquery under WHERE statement calculates the middle sequence number. There are two points in this SQL script. One is that filtering cannot be performed over the first subquery directly because WHERE statement cannot use the calculated filed in the same level SELECT statement, which is due to SQL’s execution order. The other is that the result of subquery under WHERE statement is sure to be a one row and one column table containing a single value. In this case, it can be treated as a single value to be compared with seq to see whether they are equal.
Below is the SQL query for calculating the median in multiple stocks:
SELECT *
FROM
(SELECT code, day, price,
ROW_NUMBER() OVER (PARTITION BY code ORDER BY day ASC)
FROM tbl) t1
WHERE seq=(
SELECT TRUNC((COUNT(*)+1)/2) middleSeq
FROM tbl t2
WHERE t1.code=t2.code
)Besides PARTITION BY added in the window function, the query condition should be limited for one stock during the median calculation.
5. Calculate the growth rate of the highest closing price compared with the previous day for each stock
This requires two types of sorting to locate the record with the highest price. Below is for data of a single stock:
SELECT day, price, seq, rate
FROM (
SELECT day, price, seq,
price/LAG(price,1) OVER (ORDER BY day ASC) rate
FROM (
SELECT day, price,
ROW_NUMBER ()OVER (ORDER BY price DESC) seq
FROM tbl
)
)
WHERE seq=1Both layers of consecutive subqueries use the window function to add useful information to the original data. ROW_NUMBER indexes closing prices in descending order. LAG function calculates the growth rate of each date. Finally, the script gets the date when the closing price is the highest according to condition seq=1.
The filtering operation to get the highest closing price should be after the calculation of growth rates. If the filtering is done before we get the date with the highest price, we cannot calculate the growth rate correctly.
As we have given examples of order-based calculation on subsets, we will skip the final solution to this example. You can try to write the script if you have an interest in it.
2. SPL solution
Below is the SPL script for getting the median of stock prices in task 4:

Import stock data table and sort it by price. Then group it by code and calculate the stock price median for each stock.
The way of thinking is like this. Stock records of the same code will be put into the same group and sorted by price. Then for each post-grouping subset, we can access the record through the middle position sequence number.
Now for task 5 that calculates the growth rate of the date with the highest closing price compared with the previous date, SPL has the following script:
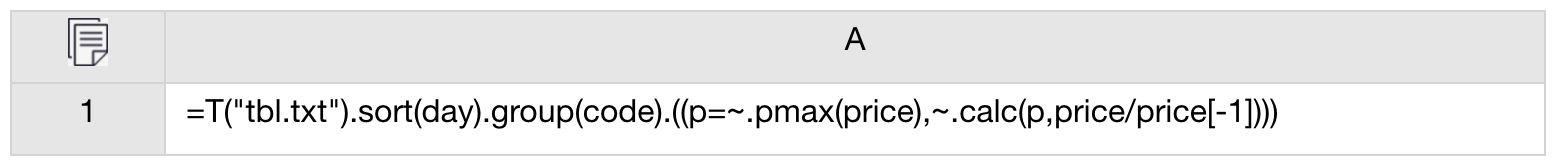
Import the stock data table, sort it by date and group it by code. The pmax function is used to locate the record containing the highest stock price, and then the calc function calculates the target at the specified position.
Generally, SPL handles the location scenarios in two steps. First, it gets the position (sequence number) of the target member or one meeting a specific condition. Then we can access it or perform an operation on it according to the sequence number. Users do not need to implement the location process themselves as SPL provides a series of locate functions to search for a certain member or an expression in a table sequence.
Ⅲ.The order-based grouping
1. SQL solution
The ordered information can also be used in a grouping operation. Below is an example:
Count the Days When a Stock Rises Continuously for the Longest Time
Not a piece of cake. The basic way of thinking is to divide stock records ordered by date into multiple groups, during which records whose prices rise continuously are put into same group. That is, if the stock price in a certain date rises compared with the previous date, put it into the same group with the previous record; otherwise, create a new group for it. Finally, count the members in each group to find the one with the largest member count, which is what we need.
The case is special because it is related to the order of records. SQL supports equi-grouping only. It needs to convert the special cases into the ordinary equi-grouping to implement. The process is as follows:
1) Sort records by date and get the stock price in the previous date for each date using the window function;
2) Compare the closing prices, mark 0 if it rises and 1 if it falls;
3) Sum marks before the current record cumulatively and get a result in the form of 0,0,1,1,1,1,2,2,3,3,3…, which are the group numbers we need;
4)Perform equi-grouping in SQL.
Below is the complete SQL query:
SELECT MAX(ContinuousDays)
FROM (
SELECT COUNT(*) ContinuousDays
FROM (
SELECT SUM(RisingFlag) OVER (ORDER BY day) NoRisingDays
FROM (
SELECT day, CASE WHEN price>
LAG(price) OVER (ORDER BY day) THEN 0 ELSE 1 END RisingFlag FROM tbl
)
) GROUP BY NoRisingDays
)With four layers of nested subqueries, it is not a simple one. An explore of the way of thinking shows the difference of SQL and JAVA/C. SQL is an set-oriented language and provides operations directly on sets, but without offering explicit and exquisitely controllable loop operations and procedure-oriented temporary variables. So, it resorts to the roundabout way of performing several standard set-oriented operations to achieve the equal effect. The non-set-oriented JAVA and C generate more intuitive solutions that process each record circularly and create a new group or put the record into an existing one. Yet they do not supply set-oriented operations. Both SQL and JAVA/C have their merits and demerits.
Yet real-world requirements exist no matter how complex they are:
Find the Stock That Rises Consecutively for at Least Three Days
This scenario involves order-based grouping plus post-grouping subsets, ordinary equi-grouping and filtering aggregate (HAVING) in turn. SQL gets all groups of consecutively rising records for each stock according to the previous query, enclose the current query with grouping operation to calculate the largest consecutive rising days for each stock, and then perform a filtering aggregate to get the groups where the stock rises consecutively for at least three days using the conditional statement HAVING:
SELECT code, MAX(ContinuousDays)
FROM (
SELECT code, NoRisingDays, COUNT(*) ContinuousDays
FROM (
SELECT code,
SUM(RisingFlag) OVER (PARTITION BY code ORDER BY day) NoRisingDays
FROM (
SELECT code, day,
CASE WHEN price>
LAG(price) OVER (PARTITION BY code ORDER BY day)
THEN 0 ELSE 1 END RisingFlag
FROM tbl
)
) GROUP BY NoRisingDays
)
GROUP BY code
HAVING MAX(ContinuousDays)>=3The code is almost unintelligible.
2. SPL Solution
For task 6 that calculates the largest number of days a stock rises consecutively, SPL script is as follows:

Import stock data table and sort it by date. The group function uses the @o option to group the table according to whether the price rises or falls. The grouping operation compares each record with the direct neighbor next to it and decides whether to create a new group according to whether the price rises. Finally, the script counts the days when the prices rise consecutively.
The solution is to find the number of days each time the stock rises consecutively and to get the longest group. SPL can handle it according to the natural way of thinking because it has a simple syntax and clear logic. SPL and SQL have a big difference because SQL is based on unordered sets while SPL table sequences are ordered sets. Ordered sets are better at handling order-based calculations. Besides, SPL offers a wealth of related functions to reduce the coding complexity.
For task 7 that finds the stocks that rise consecutively for at least three days, the SPL script is as follows:

Import stock data table, sort it by date, group it by code, calculate the largest number of consecutive rising days for each stock according to the solution to task 6, and then get those where stock rises consecutively for at least three days.
The SQL solution is hard to understand but the SPL script is easy. The script only has an additional grouping operation by stock code. SPL and SQL have essential differences in grouping operations. Besides retaining the grouping & aggregation result, SQL grouping operation can only select the grouping field and the result aggregates. SPL, however, with the intuitive way of record grouping, can put records of the same code into one group and retain the whole data in a post-grouping subset. This makes it be able to perform a further operation on subsets, like in this case where the order-based grouping is performed on each subset.
Summary
SQL is not fit to handle order-based grouping operations, particularly when window functions are not at hand (Now, certain databases still do not support window functions). In theory, SQL can implement any scenarios, but in practice, the coding process is too complex to be implemented. The introduction of window functions makes it easier to handle order-based calculations, but coding is still hard for complicated scenarios.
The cause is that SQL’s theoretical foundation, the relational algebra, is based on unordered sets. Window functions, however, are patches rather than the solution to address the SQL problem.
In fact, the array (set) in computer languages is naturally ordered (with sequence numbers). With high-level languages, such as JAVA and C, it is easy to understand and implement order-based calculations. The problems are that they have a weak ability in computing sets and generate relatively lengthy code for doing the calculations (though the calculations themselves are not difficult).
The SPL-driven esProc is a professional data computation engine. It is ordered-set-based and offers a complete set of grouping functions, which makes the marriage of both Java and SQL advantages. An order-based set-oriented operation in SPL will thus become simple and easy.
SPL offers a syntax for doing inter-row calculations and supports order-based grouping, facilitating handling the above tasks with the natural logic and generating elegant code.
Opinions expressed by DZone contributors are their own.
Comments