Comparing the Top Three Schema Management Tools
In this article, readers will learn about three of the top schema management tools, like AWS Glue, Confluent Schema Registry, and Memphis.dev Schemaverse.
Join the DZone community and get the full member experience.
Join For FreeBefore deepening into the different supporting technologies, let’s create a baseline about schemas and message brokers or async server-server communication.
Schema = Struct.
The shape and format of a “message” are built and delivered between different applications/services/electronic entities.
Schemas can be found in SQL and No SQL databases, in different shapes of the data the database expects to receive (for example, first_name:string, first.name, etc..).
An unfamiliar or noncompliant schema will result in a drop, and the database will not save the record. Schemas can also be found when two logical entities are communicating, for example, two microservices.
Imagine: A writes a message to B, which expects a specific format (like Protobuf), and its logic or code also expects specific keys and value types, for example, a typo in the column name. Unexpected schema or different formats will result in a consumer.
Schemas are manual or have an automatic contract for stable communication that dictates how two entities should communicate. The following compared technologies will help you maintain and enforce schemas between services as data flows from one service to another.
What Is AWS Glue?
AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development.
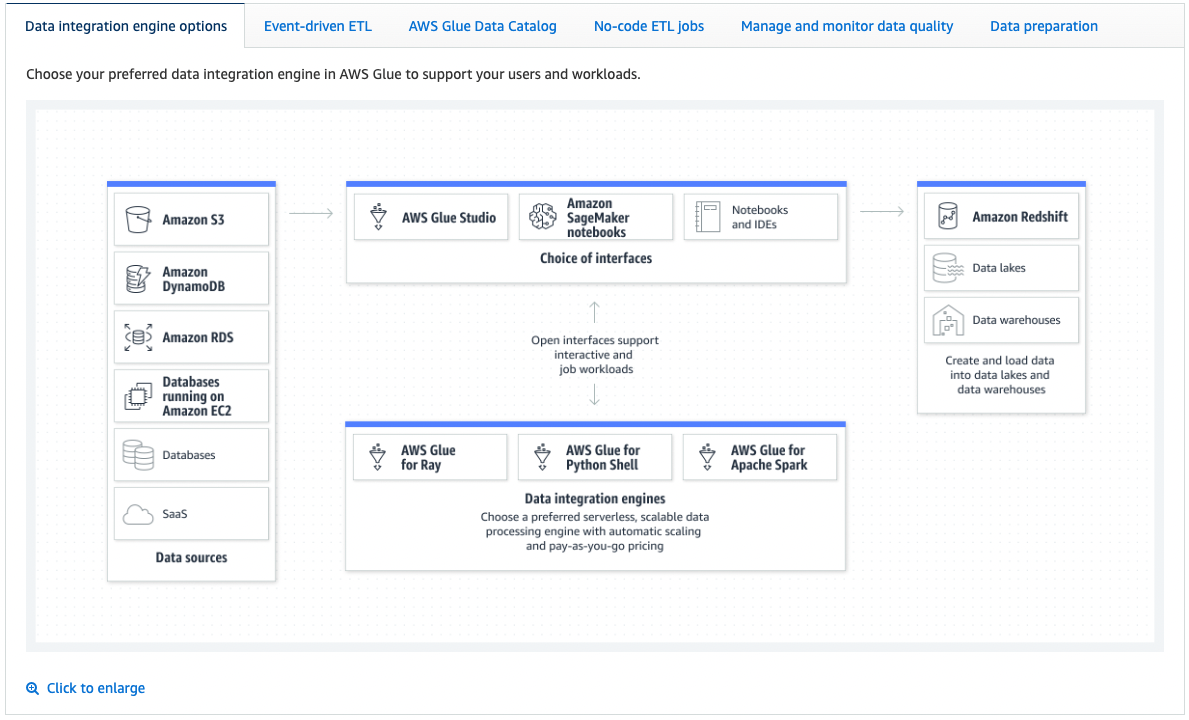
Capabilities
- Data integration engine
- Event-driven ETL
- No-code ETL jobs
- Data preparation
The main components of AWS Glue are the Data Catalog, which stores metadata, and an ETL engine that can automatically generate Scala or Python code. Common data sources would be Amazon S3, RDS, and Aurora.
What Is Confluent Schema Registry?
Confluent Schema Registry provides a serving layer for your metadata.
It provides a RESTful interface for storing and retrieving your Avro®, JSON Schema, and Protobuf schemas.
It stores a versioned history of all schemas based on a specified subject name strategy, provides multiple compatibility settings, and allows the evolution of schemas according to the configured compatibility settings and expanded support for these schema types.
It provides serializers that plug into Apache Kafka® clients that handle schema storage and retrieval for Kafka messages that are sent in any of the supported formats.

Schema Registry lives outside of and separately from your Kafka brokers. Your producers and consumers still talk to Kafka to publish and read data (messages) on topics.
Concurrently, they can also talk to Schema Registry to send and retrieve schemas that describe the data models for the messages.
What Is Memphis.dev Schemaverse?
Memphis Schemaverse provides a robust schema store and schema management layer on top of Memphis broker without a standalone compute unit or dedicated resources.
With a unique and modern UI and programmatic approach, technical and non-technical users can create and define different schemas, attach the schema to multiple stations, and choose if the schema should be enforced or not.
Memphis’ low-code approach removes the serialization part as it is embedded within the producer library.
Schemaverse supports versioning, GitOps methodologies, and schema evolution.

Schemaverse’s main purpose is to act as an automatic gatekeeper and ensure the format and structure of ingested messages to a Memphis station and reduce consumer crashes, as often happens if certain producers produce an event with an unfamiliar schema.
Current Version Common Use Cases
- Schema enforcement between microservices.
- Data contracts
- Convert events’ format
- Create an organizational standard around the different consumers and producers.
Comparison
| AWS Glue | Schema Registry | Schemaverse | |
| Data formats | JSON Schema, Avro, Protobuf | Avro, JSON Schema, Protobuf | JSON Schema, Protobuf, GraphQL |
| Validation and Enforcement | Yes | Yes | Yes |
| Serialization | Requires implementation | Requires implementation | Transparent |
| Deserialization | Requires implementation | Requires implementation | Transparent |
| Management interface | GUI, CLI, SDK | REST, SDK, GUI | SDK, GUI, CLI |
| Supported languages | Scala | Java, .NET, Python | Go, Node.js, Python, REST, TypeScript, NestJS, Java, .NET, Kotlin |
| Compatibility mode | backward or forward | backward or forward | backward or forward |
| Schema creation | Manual / Auto | Manual / Auto | Manual |
| Pricing | $1.00 per 100,000 objects stored above 1M, per month + $1.00 per million requests above 1M in a month | Confluent Community License / Confluent Enterprise license | Open-source / Free |
Validation and Enforcement
When data streaming applications are integrated with schema management, schemas used for data production are validated against schemas within a central registry, allowing you to centrally control data quality.
AWS Glue offers enforcement and validation using the Glue schema registry for Java-based applications using Apache Kafka, AWS MSK, Amazon Kinesis Data Streams, Apache Flink, Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda.
Schema registry validates and enforces message schemas at the client and server sides. Validation will take place on the client side by performing a serialization over the about-to-be-produced data by retrieving the schema from the schema registry. Confluent provides read-to-use serialization functions that can be used.
Schema updates and evolution will require booting the client and fetching the updates to change the schema at the registry level. It is first required to be switched into a certain mode (forward/backward), perform the change, and then, bring it back to default.
Schemaverse validates and enforces the schema at the client level as well without the need for manual schema fetch and supports runtime evolution, meaning clients don’t need a reboot to apply new schema changes, including different data formats.
Schemaverse also makes the serialization/deserialization transparent to the client and embeds it within the SDK based on the required data format.
Serialization/Deserialization
When sending data over the network, it needs to be encoded into bytes before. AWS Glue and Schema Registry work similarly. Each created schema has an ID.
When the application producing data has registered its schema, the Schema Registry serializer validates that the record being produced by the application is structured with the fields and data types matching a registered schema.
Deserialization will take place by a similar process by fetching the needed schema based on the given ID within the message.
In AWS Glue and Schema Registry, it is the client’s responsibility to implement and deal with the serialization. In Schemaverse, it is fully transparent, and all that is needed by the client is to produce a message that complies with the required structure.
Conclusion
By now, you should have a better understanding of the top three schema management tools, AWS Glue, Confluent Schema Registry, and Memphis.dev Schemaverse. I hope you take some impactful information away that will help you decide which schema management tool works best for you and your needs.
Published at DZone with permission of Yaniv Ben Hemo. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments