Integrating ClickHouse and S3 Compatible Object Storage
S3 compatible object storage integration is now extending ClickHouse capabilities — from basic import/export to MergeTree table data functionalities.
Join the DZone community and get the full member experience.
Join For FreeClickHouse is a polyglot database that can talk to many external systems using dedicated engines or table functions. In modern cloud systems, the most important external system is object storage. First, it can hold raw data to import from or export to other systems (a.k.a. a data lake). Second, it can offer cheap and highly durable storage for table data. ClickHouse now supports both of these uses for S3 compatible object storage.
The first attempts to marry ClickHouse and object storage were merged more than a year ago. Since then object storage support has evolved considerably. In addition to the basic import/export functionality, ClickHouse can use object storage for MergeTree table data. While this functionality is still experimental, it has already attracted a lot of attention at meetups and webinars. In this article, we will explain how this integration works.
S3 Table Function
ClickHouse has a powerful method to integrate with external systems called "table functions." Table functions allow users to export/import data into other sources, and there are plenty of sources available. For example, there's MySQL Server, ODBC or JDBC connection, file, URL, and, more recently, S3-compatible storage. The S3 table function is in the official list, and the basic syntax is the following:
s3(path, [aws_access_key_id, aws_secret_access_key,] format, structure, [compression])
Input parameters:
path— bucket URL. Path to file. Supports following wildcards in read-only mode:*,?,{abc,def}and{N..M}where N, M — numbers,’abc’,‘def’— stringsformat— The format of the datastructure— Structure of the table. Format‘column1_name column1_type, column2_name column2_type, …’compression— Parameter is optional, currently‘gzip’is the only option but other methods are being added
INSERT INTO tripdata
SELECT *
FROM s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/data-20*.csv.gz',
'CSVWithNames',
'pickup_date Date, id UInt64, vendor_id String, tpep_pickup_datetime DateTime, tpep_dropoff_datetime DateTime, passenger_count UInt8, trip_distance Float32, pickup_longitude Float32, pickup_latitude Float32, rate_code_id String, store_and_fwd_flag String, dropoff_longitude Float32, dropoff_latitude Float32, payment_type LowCardinality(String), fare_amount Float32, extra String, mta_tax Float32, tip_amount Float32, tolls_amount Float32, improvement_surcharge Float32, total_amount Float32, pickup_location_id UInt16, dropoff_location_id UInt16, junk1 String, junk2 String',
'gzip');
0 rows in set. Elapsed: 238.439 sec. Processed 1.31 billion rows, 167.39 GB (5.50 million rows/s., 702.03 MB/s.)Note the wildcards! They allow you to import multiple files in a single function call. For example, our favorite NYC taxi trips dataset that is stored in one file per month can be imported with a single SQL command.
On an Altinity.Cloud ClickHouse instance, it takes me less than 4 minutes to import a 1.3B rows dataset!
A few important hints:
- As of the 20.10 ClickHouse version, wildcard paths do not work properly with "generic" S3 bucket URLs. A region-specific one is required. So we have to use: https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/ instead of https://altinity-clickhouse-data.s3.amazonaws.com/
- On the other hand, single file download can use convenient bucket URLs
- The S3 import performance heavily depends on the level of client-side parallelism. In glob mode, multiple files can be processed in parallel. The example above used 32 insert threads. If you have a smaller server and VM, try setting higher values of
max_insert_threadssetting. It can be done by asetcommand, for example:set max_threads=32, max_insert_threads=32; - From the other side, the
input_format_parallel_parsingsetting may result in overcommitting the memory, so better to turn it off
S3 table function can be used not only for imports but for exports as well! This is how an ontime dataset can be uploaded to S3.
INSERT INTO FUNCTION s3('https://altinity-clickhouse-data.s3.amazonaws.com/airline/data/ontime2/2019.csv.gz', '*****', '*****', 'CSVWithNames', 'Year UInt16, <other 107 columns here>, Div5TailNum String', 'gzip') SELECT *
FROM ontime_ref
WHERE Year = 2019
Ok.
0 rows in set. Elapsed: 43.314 sec. Processed 7.42 million rows, 5.41 GB (171.35 thousand rows/s., 124.93 MB/s.)Uploading is pretty slow because we can not benefit from parallelism in this case. ClickHouse can not automatically split the data into multiple files, so only one file can be uploaded at a time. There is a feature request to enable automatic partitioning when inserting to an external table function. That would make export more efficient and convenient.
Also, it is a bit annoying that ClickHouse requires table structure to be supplied to the S3 table function. This is going to be improved in future releases.
ClickHouse Storage Architecture
S3 table function is a convenient tool for exporting or importing data but it can not be used in real insert/select workloads. Closer integration with the ClickHouse storage system is required. Let’s look at ClickHouse storage architecture in more detail.
We have already discussed storage several times earlier in the blog, for example in Amplifying ClickHouse Capacity with Multi-Volume Storage (Part 1). Let’s do a short recap. ClickHouse provides several abstraction layers from top to the bottom:
- Storage policies define what volumes can be used and how data migrates from volume to volume
- Volumes allow you to organize multiple
diskdevices together diskrepresents the physical device or mount point.
 When this storage design was implemented in early 2019, ClickHouse supported only one type of disk that maps to OS mount points. A few months later the ClickHouse development team added an extra abstraction layer inside the disk itself that allows you to plug in different disk types. As one can probably guess, the rationale for this was object storage integration. The new disk type
When this storage design was implemented in early 2019, ClickHouse supported only one type of disk that maps to OS mount points. A few months later the ClickHouse development team added an extra abstraction layer inside the disk itself that allows you to plug in different disk types. As one can probably guess, the rationale for this was object storage integration. The new disk type s3 was added shortly after. It encapsulated the specifics of communicating with S3-compatible object storage. Now we can configure S3 disks in ClickHouse and store all or some data in the object storage.
Object Storage Configuration
Disks, volumes, and storage policies can be defined in the main ClickHouse configuration file config.xml or, better, in the custom file inside /etc/clickhouse-server/config.d folder. Let’s define the disk S3 first:
config.d/storage.xml:
<yandex>
<storage_configuration>
<disks>
<s3>
<type>s3</type>
<endpoint>http://s3.us-east-1.amazonaws.com/altinity/taxi9/data/</endpoint>
<access_key_id>*****</access_key_id>
<secret_access_key>*****</secret_access_key>
</s3>
</disks>
...
</yandex>This is a very basic configuration. ClickHouse supports quite a lot of different options here; we will discuss some of them later.
Once the S3 disk is configured, it can be used in volume and storage policy configuration. We can set up several policies for different use cases:
- S3 volume in a policy next to other volumes. It can be used for TTL or manual moves of table partitions.
- S3 volume in a policy with no other volumes. This is an S3-only approach.
<yandex>
<storage_configuration>
...
<policies>
<tiered>
<volumes>
<default>
<disk>default</disk>
</default>
<s3>
<disk>s3</disk>
</s3>
</volumes>
</tiered>
<s3only>
<volumes>
<s3>
<disk>s3</disk>
</s3>
</volumes>
</s3only>
</policies>
</storage_configuration>
</yandex>Now let’s try to create some tables and move data around.
Inserting Data
We will be using an ontime dataset for this example. You can get it from ClickHouse Tutorial or download it from an Altinity S3 bucket. The table has 193M rows and 109 columns — that’s why it is interesting to see how it performs with S3, where file operations are expensive. The reference table name is ontime_ref and it uses default EBS volume. We can now use it as a template for experiments with S3.
CREATE TABLE ontime_tiered AS ontime_ref
ENGINE = MergeTree
PARTITION BY Year
ORDER BY (Carrier, FlightDate)
TTL toStartOfYear(FlightDate) + interval 3 year to volume 's3'
SETTINGS storage_policy = 'tiered';
CREATE TABLE ontime_s3 AS ontime_ref
ENGINE = MergeTree
PARTITION BY Year
ORDER BY (Carrier, FlightDate)
SETTINGS storage_policy = 's3only';
ontime_tiered table is configured to store a full 3 years of data on block storage and move earlier data to S3. ontime_s3 is the S3-only table.
Now, let’s insert some data. Our reference table has data up to 31 March 2020.
INSERT INTO ontime_tiered SELECT * from ontime_ref WHERE Year=2020;
0 rows in set. Elapsed: 0.634 sec. Processed 1.83 million rows, 1.33 GB (2.89 million rows/s., 2.11 GB/s.)That was almost instant. The data still goes to the normal disk. What about the S3 table?
INSERT INTO ontime_s3 SELECT * from ontime_ref WHERE Year=2020;
0 rows in set. Elapsed: 15.228 sec. Processed 1.83 million rows, 1.33 GB (120.16 thousand rows/s., 87.59 MB/s.)The same amount of rows takes 25 times more to insert!
INSERT INTO ontime_tiered SELECT * from ontime_ref WHERE Year=2015;
0 rows in set. Elapsed: 16.701 sec. Processed 7.21 million rows, 5.26 GB (431.92 thousand rows/s., 314.89 MB/s.)
INSERT INTO ontime_s3 SELECT * from ontime_ref WHERE Year=2015;
0 rows in set. Elapsed: 15.098 sec. Processed 7.21 million rows, 5.26 GB (477.78 thousand rows/s., 348.33 MB/s.)Once data lands on S3, insert performance degrades quite a lot. This is certainly not desirable for a tiered table, so there is a special volume level setting that disables ttl moves on insert completely and runs it in the background only. Here is how it can be configured:
<policies>
<tiered>
<volumes>
<default>
<disk>default</disk>
</default>
<s3>
<disk>s3</disk>
<perform_ttl_move_on_insert>0</perform_ttl_move_on_insert>
</s3>
</volumes>
</tiered>
With such a setting, insert always goes to the first disk in the storage policy. ttl moves to the corresponding volume and is executed in the background. Let’s clean the ontime_tiered table and perform a full table insert (side note: truncate takes a long time).
INSERT INTO ontime_tiered SELECT * from ontime_ref;
0 rows in set. Elapsed: 32.403 sec. Processed 194.39 million rows, 141.25 GB (6.00 million rows/s., 4.36 GB/s.)This was fast since all the data was inserted into the fast disk. We can check how data is located in the storage using this query:
select disk_name, part_type, sum(rows), sum(bytes_on_disk), uniq(partition), count() from system.parts where active and database='ontime' and table='ontime_tiered' group by table, disk_name, part_type order by table, disk_name, part_type;
┌─disk_name─┬─part_type─┬─sum(rows)─┬─sum(bytes_on_disk)─┬─uniq(partition)─┬─count()─┐
│ default │ Wide │ 16465330 │ 1348328157 │ 3 │ 8 │
│ s3 │ Compact │ 8192 │ 678411 │ 1 │ 1 │
│ s3 │ Wide │ 177912114 │ 12736193777 │ 31 │ 147 │
└───────────┴───────────┴───────────┴────────────────────┴─────────────────┴─────────┘So the data was already moved to S3 by a background process. Only 10% of the data is stored on a local file system, and everything else has been moved to the object storage. This looks to be the right way to deal with S3 disks, so we will be using ontime_tiered later on.
Note the part_type column. ClickHouse MergeTree table can store data parts in different formats. Wide format is the default; it is optimized for query performance. It requires, however, at least two files per column. The ontime table has 109 columns, which results in 227 files for every part. This is the main reason for slow S3 performance on inserts and deletes.
On the other hand, compact parts store all data in a single file, so inserts to compact parts are much faster (we tested that), but query performance degrades. Therefore, ClickHouse uses compact parts only for small parts. The default threshold is 10MB (see min_bytes_for_wide_part and min_rows_for_wide_part MergeTree settings).
Checking Query Performance
In order to test query performance, we will run several benchmark queries for ontime_tiered and ontime_ref tables that query historical data, so the tiered table will be using S3 storage. We will also run a mixed range query to confirm that S3 and non-S3 data can be used together, and compare results with the reference table. This is not going to be thoroughly tested, but it should give us a general idea of performance differences. Only four representative queries have been selected from the benchmark. Please refer to the full list in the ClickHouse Tutorial.
/* Q4 */
SELECT
Carrier,
count(*)
FROM ontime_tiered
WHERE (DepDelay > 10) AND (Year = 2007)
GROUP BY Carrier
ORDER BY count(*) DESCThe query above runs in 0.015s for ontime_ref and 0.318s for ontime_tiered. The second run completes in 0.142s.
/* Q6 */
SELECT
Carrier,
avg(DepDelay > 10) * 100 AS c3
FROM ontime_tiered
WHERE (Year >= 2000) AND (Year <= 2008)
GROUP BY Carrier
ORDER BY c3 DESCThis query runs in 0.063 sec for ontime_ref and 0.766/0.518 for ontime_tiered.
/* Q8 */
SELECT
DestCityName,
uniqExact(OriginCityName) AS u
FROM ontime_tiered
WHERE Year >= 2000 and Year <= 2010
GROUP BY DestCityName
ORDER BY u DESC
LIMIT 10This query runs in 0.319s for ontime_ref, and 1.016/0.988 for ontime_tiered.
/* Q10 */
SELECT
min(Year),
max(Year),
Carrier,
count(*) AS cnt,
sum(ArrDelayMinutes > 30) AS flights_delayed,
round(sum(ArrDelayMinutes > 30) / count(*), 2) AS rate
FROM ontime_tiered
WHERE (DayOfWeek NOT IN (6, 7)) AND (OriginState NOT IN ('AK', 'HI', 'PR', 'VI')) AND (DestState NOT IN ('AK', 'HI', 'PR', 'VI'))
GROUP BY Carrier
HAVING (cnt > 100000) AND (max(Year) > 1990)
ORDER BY rate DESC
LIMIT 10This query runs in 0.436s for ontime_ref and 2.493/2.241s for ontime_tiered. This time, both block and object storage was used in a single query for the tiered table.
 So, query performance with the S3 disk definitely degrades, but it is still fast enough for interactive queries. Note the performance improvement on the second run. While Linux page cache can not be used for S3 data, ClickHouse caches index and mark files for S3 storage locally, which gives a notable boost when analyzing conditions and fetching the data from S3.
So, query performance with the S3 disk definitely degrades, but it is still fast enough for interactive queries. Note the performance improvement on the second run. While Linux page cache can not be used for S3 data, ClickHouse caches index and mark files for S3 storage locally, which gives a notable boost when analyzing conditions and fetching the data from S3.
Trying a Bigger Dataset
Let’s try to compare the query performance of the bigger NYC taxi trips dataset as well. The dataset contains 1.3 billion rows. As noted above, it can be loaded from S3 using the S3 table function. First, we create the tiered table the same way:
CREATE TABLE tripdata_tiered AS tripdata
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY (vendor_id, pickup_location_id, pickup_datetime)
TTL toStartOfYear(pickup_date) + interval 3 year to volume 's3'
SETTINGS storage_policy = 'tiered';And insert the data:
INSERT INTO tripdata_tiered SELECT * FROM tripdata
0 rows in set. Elapsed: 52.679 sec. Processed 1.31 billion rows, 167.40 GB (24.88 million rows/s., 3.18 GB/s.)That was almost instant, thanks to EBS storage performance. Now let’s look into the data placement:
select disk_name, part_type, sum(rows), sum(bytes_on_disk), uniq(partition), count() from system.parts where active and table='tripdata_tiered' group by table, disk_name, part_type order by table, disk_name, part_type;
┌─disk_name─┬─part_type─┬──sum(rows)─┬─sum(bytes_on_disk)─┬─uniq(partition)─┬─count()─┐
│ s3 │ Compact │ 235509 │ 6933518 │ 8 │ 8 │
│ s3 │ Wide │ 1310668454 │ 37571786040 │ 96 │ 861 │
└───────────┴───────────┴────────────┴────────────────────┴─────────────────┴─────────┘Apparently, the dataset end date is 31 December 2016, so all our data goes to S3. You can see quite a lot of parts — it will take some time for ClickHouse to merge it. If we check the same query 10 minutes later, the number of parts reduces to three to four per partition. In order to see not only the S3 performance but also the effect of the number of parts, we run benchmark queries twice: first with 441 parts in the S3 table, and second with an optimized table that contains only 96 parts after OPTIMIZE FINAL. Note, OPTIMIZE FINAL is very slow on the S3 table; it took around an hour to complete our setup.
The chart below compares the best result of three runs for five test queries:
 As you can see, the query performance difference between EBS and S3 MergeTree is not that substantial anymore compared to the smaller
As you can see, the query performance difference between EBS and S3 MergeTree is not that substantial anymore compared to the smaller ontime dataset and it reduces when query complexity increases. Also, table optimization helps to reduce the gap even more.
Under the Hood
ClickHouse was not originally designed for object storage. Therefore it uses some block-storage-specific features like hard links a lot. How does it work for the S3 storage then? Let’s look into the ClickHouse data directory to figure it out.
For non-S3 tables, ClickHouse stores data parts in /var/lib/clickhouse/data/<database>/<table>. For S3 tables, you won’t file the data at this location; instead, something similar is located in /var/lib/clickhouse/disks/s3/data/<database>/<table>. (This location can be configured on the disk level). Let’s look into the contents, though:
#/ cat /var/lib/clickouse/disks/s3/data/ontime/ontime_tiered/1987_123_123_0/ActualElapsedTime.bin
2
1 530583
530583 lhtilryzjomwwpcbisxxqfjgrclmhcnq
0This is not the data, but the reference to an S3 file instead. We can find corresponding S3 object looking into the AWS console:
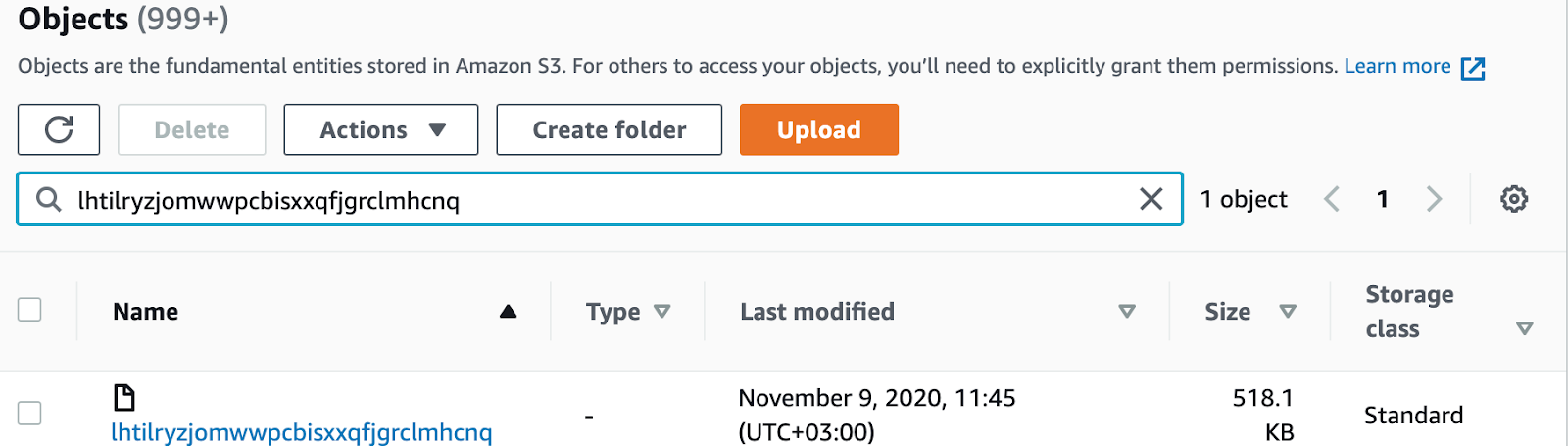
ClickHouse generates unique files for every column with hashed names and stores references in the local file system. Merges, mutations, and rename operations that require hard links in block storage are implemented on the reference level, while S3 data is not touched at all. This definitely solves a lot of problems but creates another one: all files for all columns of all tables are stored with a single prefix.
Issues and Limitations
S3 storage for MergeTree tables is still experimental, and it has a few loose ends. One evident limitation is replication. Object storage is supposed to be replicated by the cloud provider already, so there is no need to use ClickHouse replication and keep multiple copies of the data. ClickHouse needs to be smart enough not to replicate S3 tables. It gets even more sophisticated when a table uses tiered storage.
Another drawback is the insert and merge performance. Some optimizations like parallel multipart uploads have been already implemented. Tiered tables can be used in order to have fast local inserts, but we can not change the laws of physics — merges may be quite slow. In real use cases, though, ClickHouse will do most of the merges on fast disks before data goes to object storage. There is also a setting to disable merges on object storage completely in order to protect historical data from unneeded changes.
The structure of the data on object storage also needs to be improved. In particular, if every table had a separate prefix, it would be possible to move tables between locations. Adding metadata would allow you to restore the table from an object storage copy if everything else was lost.
Another issue is related to security. In the examples provided above, we had to supply AWS access keys in SQL or ClickHouse storage configuration. This is definitely not convenient, let alone secure. There are two options that make users’ lives easier. First, it is possible to supply credentials or the authorization header globally on a server configuration level, for example:
<yandex>
<s3>
<my_endpoint>
<endpoint>https://my-endpoint-url</endpoint>
<access_key_id>ACCESS_KEY_ID</access_key_id>
<secret_access_key>SECRET_ACCESS_KEY</secret_access_key>
<header>Authorization: Bearer TOKEN</header>
</my_endpoint>
</s3>
</yandex>Second, IAM role support is already in development. Once implemented, it delegates access control to AWS account administrators.
All those limitations are taken into account in the current development efforts, and we plan to improve MergeTree S3 implementation in the next few months.
Conclusion
ClickHouse constantly adapts to user needs. Many ClickHouse features are driven by community feedback. Object storage support is not an exception. Frequently demanded by community users, it has been largely contributed by developers from Yandex.Cloud and Altinity.Cloud teams. While imperfect at the moment, it extends ClickHouse capabilities a lot already. The development is still on-going; every new feature and improvement in this area pushes ClickHouse one step further to effective cloud operation.
Published at DZone with permission of Alexander Zaitsev. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments