Chunking Strategies for Optimizing Large Language Models (LLMs)
Different chunking approaches, such as fixed-size, recursive, semantic, and agentic chunking, are discussed, each with its own advantages.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) (opens new window)have transformed the natural language processing (NLP) (new window)domain by generating human-like text, answering complex questions, and analyzing large amounts of information with impressive accuracy. Their ability to process diverse queries and produce detailed responses makes them invaluable across many fields, from customer service to medical research. However, as LLMs scale to handle more data, they encounter challenges in managing long documents and retrieving only the most relevant information efficiently.
Although LLMs are good at processing and generating human-like text, they have a limited "context window." This means they can only keep a certain amount of information in memory at one time, which makes it hard to manage very long documents. It's also challenging for LLMs to quickly find the most relevant information from large datasets. On top of this, LLMs are trained on fixed data, so they can become outdated as new information appears. To stay accurate and useful, they need regular updates.
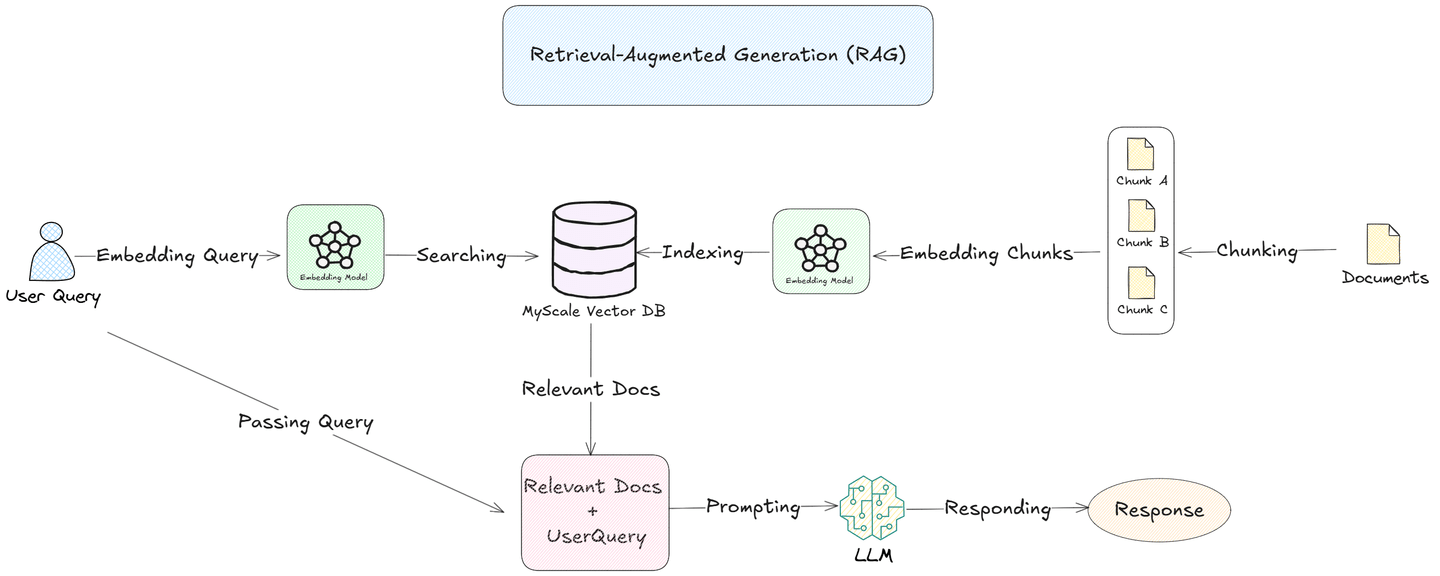
Retrieval-augmented generation (RAG) (opens new window)addresses these challenges. There are many components in the RAG workflow, such as query, embedding, indexing, and so on. Today, let's explore the chunking strategy.
By chunking documents into smaller, meaningful segments and embedding them in a vector database, RAG systems can search and retrieve only the most relevant chunks for each query. This approach allows LLMs to focus on specific information, improving response accuracy and efficiency.
In this blog, we'll explore chunking and its different strategies in more depth and their role in optimizing LLMs for real-world applications.
What Is Chunking?
Chunking is about breaking big data sources into smaller, manageable pieces or “chunks.” These chunks are stored in vector databases, allowing quick and efficient searches based on similarity. When a user submits a query, the vector database finds the most relevant chunks and sends them to the language model. This way, the model can focus only on the most relevant information, making its response faster and more accurate.
Chunking helps language models handle large datasets more smoothly and deliver precise answers by narrowing down the data it needs to look at.
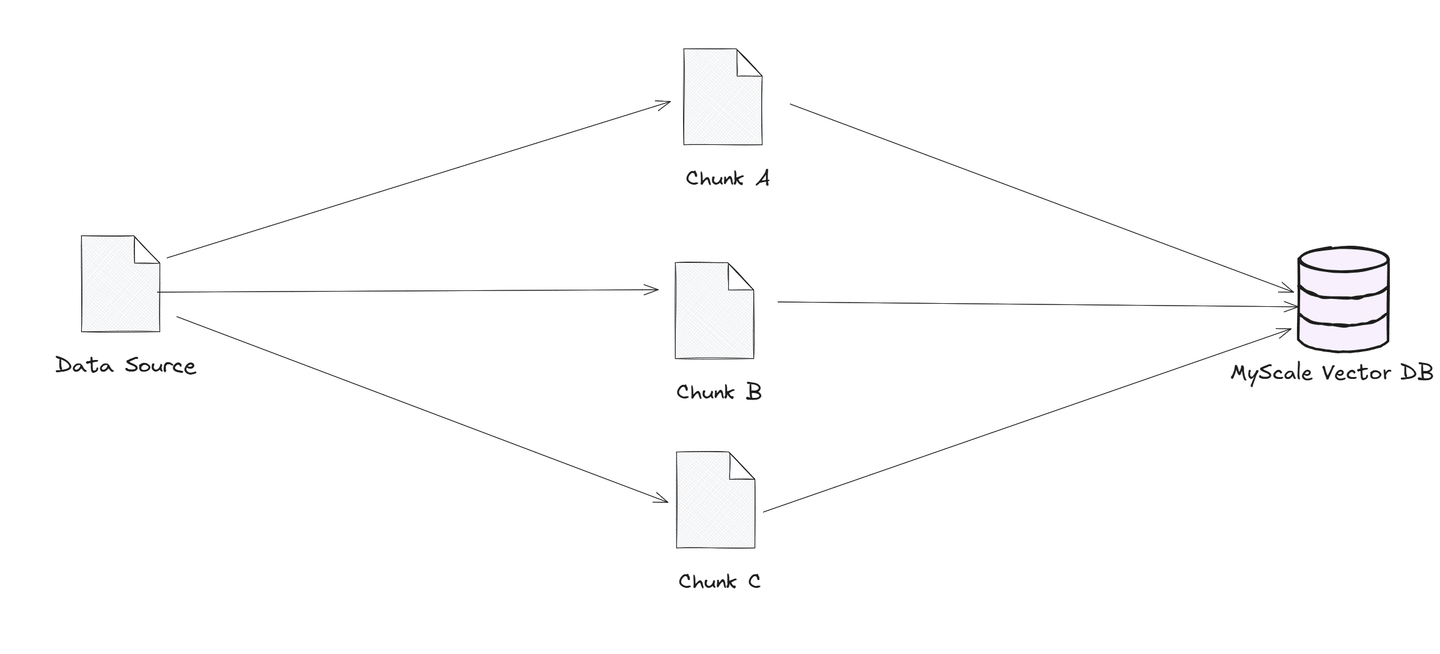
For applications that need quick, precise answers — like customer support or legal document searches—chunking is an essential strategy that boosts both performance and reliability.
Here are some of the major chunking strategies that are used in RAG:
- Fixed-size chunking
- Recursive chunking
- Semantic chunking
- Agentic chunking
Now, let's dive deep into each chunking strategy in detail.
1. Fixed-Size Chunking
Fixed-size chunking involves dividing data into evenly-sized sections, making it easier to process large documents.
Sometimes, developers add a slight overlap between chunks, where a small part of one segment is repeated at the beginning of the next. This overlapping approach helps the model retain context across the boundaries of each chunk, ensuring that critical information isn't lost at the edges. This strategy is especially useful for tasks that require a continuous flow of information, as it enables the model to interpret text more accurately and understand the relationship between segments, leading to more coherent and contextually aware responses.

The above illustration is a perfect example of fixed-size chunking, where each chunk is represented by a unique color. The green section indicates the overlapping part between chunks, ensuring the model has access to the relevant context from one chunk when processing the next.
This overlap improves the model's ability to process and understand the full text, leading to better performance in tasks like summarization or translation, where maintaining the flow of information across chunk boundaries is critical.
Coding Example
Now, let's recreate this example using a coding example. We will use LangChain (opens a new window) to implement fixed-size chunking.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Function to split text with fixed-size chunks and overlap
def split_text_with_overlap(text, chunk_size, overlap_size):
# Create a text splitter with overlap
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=overlap_size
)
# Split the text
chunks = text_splitter.split_text(text)
return chunks
# Example text
text = """Artificial Intelligence (AI) simulates human intelligence in machines for tasks like visual perception, speech recognition, and language translation. It has evolved from rule-based systems to data-driven models, enhancing performance through machine learning and deep learning."""
# Define chunk size and overlap size
chunk_size = 80 # 80 characters per chunk
overlap_size = 10 # 10 characters overlap between chunks
# Get the chunks with overlap
chunks = split_text_with_overlap(text, chunk_size, overlap_size)
# Print the chunks and overlaps
for i in range(len(chunks)):
print(f"Chunk {i+1}:")
print(chunks[i]) # Print the chunk itself
# If there's a next chunk, print the overlap between current and next chunk
if i < len(chunks) - 1:
overlap = chunks[i][-overlap_size:] # Get the overlap part
print(f"Overlap with Chunk {i+2}:")
print(overlap)
print("\n" + "="*50 + "\n")
Upon executing the above code, it will generate the following output:
Chunk 1:
Artificial Intelligence (AI) simulates human intelligence in machines for tasks
Overlap with Chunk 2:
for tasks
==================================================
Chunk 2:
for tasks like visual perception, speech recognition, and language translation.
Overlap with Chunk 3:
anslation.
==================================================
Chunk 3:
It has evolved from rule-based systems to data-driven models, enhancing
Overlap with Chunk 4:
enhancing
==================================================
Chunk 4:
enhancing performance through machine learning and deep learning.2. Recursive Chunking
Recursive chunking is a method that systematically divides extensive text into smaller, manageable sections by repeatedly breaking it down into sub-chunks. This approach is particularly effective for complex or hierarchical documents, ensuring that each segment remains coherent and contextually intact. The process continues until the text reaches a size suitable for efficient processing.
For example, consider a lengthy document that needs to be processed by a language model with a limited context window. Recursive chunking would first split the document into major sections. If these sections are still too large, the method would further divide them into subsections and continue this process until each chunk fits within the model's processing capabilities. This hierarchical breakdown preserves the logical flow and context of the original document, enabling the model to handle long texts more effectively.
In practice, recursive chunking can be implemented using various strategies, such as splitting based on headings, paragraphs, or sentences, depending on the document's structure and the specific requirements of the task.

In the illustration, the text is divided into four chunks, each shown in a different color, using recursive chunking. The text is broken down into smaller, manageable parts, with each chunk containing up to 80 words. There is no overlap between chunks. The color coding helps show how the content is split into logical sections, making it easier for the model to process and understand long texts without losing important context.
Coding Example
Now, let's code an example of how we will implement recursive chunking.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Function to split text into chunks using recursive chunking
def split_text_recursive(text, chunk_size=80):
# Initialize the RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, # Maximum size of each chunk (80 words)
chunk_overlap=0 # No overlap between chunks
)
# Split the text into chunks
chunks = text_splitter.split_text(text)
return chunks
# Example text
text = """Artificial Intelligence (AI) simulates human intelligence in machines for tasks like visual perception, speech recognition, and language translation. It has evolved from rule-based systems to data-driven models, enhancing performance through machine learning and deep learning."""
# Split the text using recursive chunking
chunks = split_text_recursive(text, chunk_size=80)
# Print the resulting chunks
for i, chunk in enumerate(chunks):
print(f"Chunk {i+1}:")
print(chunk)
print("="*50)
The above code will generate the following output:
Chunk 1:
Artificial Intelligence (AI) simulates human intelligence in machines for tasks
==================================================
Chunk 2:
like visual perception, speech recognition, and language translation. It has
==================================================
Chunk 3:
evolved from rule-based systems to data-driven models, enhancing performance
==================================================
Chunk 4:
through machine learning and deep learning.After understanding both chunking strategies based on length, it's time to understand a chunking strategy that focuses more on the meaning/context of the text.
3. Semantic Chunking
Semantic chunking refers to dividing text into chunks based on the meaning or context of the content. This method typically uses machine learning (opens new window)or natural language processing (NLP) (opens new window)techniques, such as sentence embeddings, to identify sections of the text that share similar meaning or semantic structure.

In the illustration, each chunk is represented by a different color — blue for AI and yellow for Prompt Engineering. These chunks are separated because they cover distinct ideas. This method ensures that the model can clearly understand each topic without mixing them.
Coding Example
Now, let's code an example of implementing semantic chunking.
import os
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
# Set the OpenAI API key as an environment variable (Replace with your actual API key)
os.environ["OPENAI_API_KEY"] = "replace with your actual OpenAI API key"
# Function to split text into semantic chunks
def split_text_semantically(text, breakpoint_type="percentile"):
# Initialize the SemanticChunker with OpenAI embeddings
text_splitter = SemanticChunker(OpenAIEmbeddings(), breakpoint_threshold_type=breakpoint_type)
# Create documents (chunks)
docs = text_splitter.create_documents([text])
# Return the list of chunks
return [doc.page_content for doc in docs]
def main():
# Example content (State of the Union address or your own text)
document_content = """
Artificial Intelligence (AI) simulates human intelligence in machines for tasks like visual perception, speech recognition, and language translation. It has evolved from rule-based systems to data-driven models, enhancing performance through machine learning and deep learning.
Prompt Engineering involves designing input prompts to guide AI models in producing accurate and relevant responses, improving tasks such as text generation and summarization.
"""
# Split text using the chosen threshold type (percentile)
threshold_type = "percentile"
print(f"\nChunks using {threshold_type} threshold:")
chunks = split_text_semantically(document_content, breakpoint_type=threshold_type)
# Print each chunk's content
for idx, chunk in enumerate(chunks):
print(f"Chunk {idx + 1}:\n{chunk}\n")
if __name__ == "__main__":
main()The above code will generate the following output:
Chunks using percentile threshold:
Chunk 1:
Artificial Intelligence (AI) simulates human intelligence in machines for tasks like visual perception, speech recognition, and language translation. It has evolved from rule-based systems to data-driven models, enhancing performance through machine learning and deep learning.
Chunk 2:
Prompt Engineering involves designing input prompts to guide AI models in producing accurate and relevant responses, improving tasks such as text generation and summarization. 4. Agentic Chunking
Agentic chunking is a powerful strategy among these strategies. In this strategy, we utilize LLMs such as GPT to function as agents in the chunking procedure. Instead of manually determining how to segment content, the LLM proactively organizes or divides the information according to its comprehension input. The LLM determines the best method to break the content into manageable pieces, influenced by the task's context.
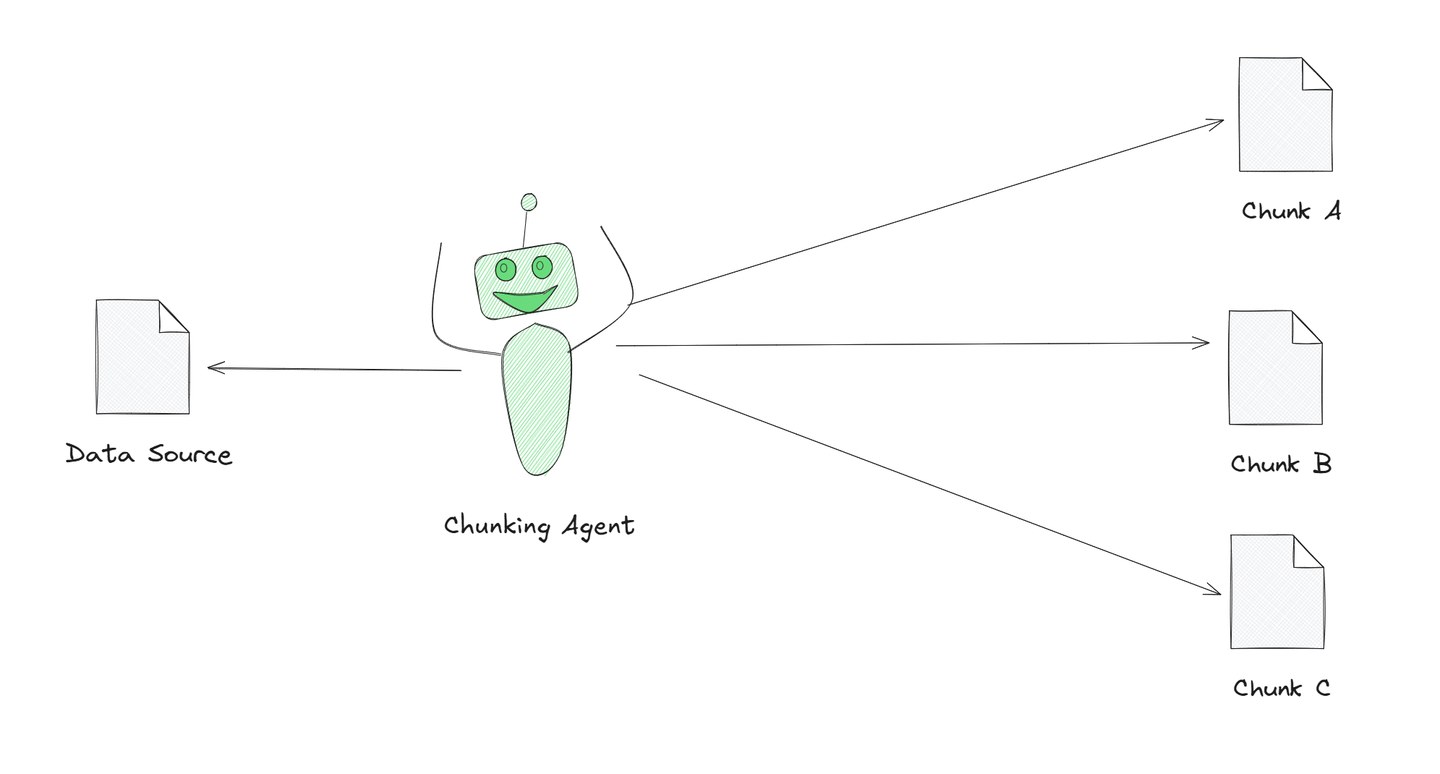
The illustration shows a chunking agent breaking down a large text into smaller, meaningful pieces. This agent is powered by AI, which helps him better understand the text and divide it into chunks that make sense. This is called agentic chunking, and it's a smarter way to process text compared to simply cutting it into equal parts.
Now, let's see how we can implement it in a coding example.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.agents import initialize_agent, Tool, AgentType
# Initialize OpenAI chat model (replace with your API key)
llm = ChatOpenAI(model="gpt-3.5-turbo", api_key="replace with your actual OpenAI API key")
# Step 1: Define Chunking and Summarization Prompt Template
chunk_prompt_template = """
You are given a large piece of text. Your job is to break it into smaller parts (chunks) if necessary and summarize each chunk.
Once all parts are summarized, combine them into a final summary.
If the text is already small enough to process at once, provide a full summary in one step.
Please summarize the following text:\n{input}
"""
chunk_prompt = PromptTemplate(input_variables=["input"], template=chunk_prompt_template)
# Step 2: Define Chunk Processing Tool
def chunk_processing_tool(query):
"""Processes text chunks and generates summaries using the defined prompt."""
chunk_chain = LLMChain(llm=llm, prompt=chunk_prompt)
print(f"Processing chunk:\n{query}\n") # Show the chunk being processed
return chunk_chain.run(input=query)
# Step 3: Define External Tool (Optional, can be used to fetch extra information if needed)
def external_tool(query):
"""Simulates an external tool that could fetch additional information."""
return f"External response based on the query: {query}"
# Step 4: Initialize the agent with tools
tools = [
Tool(
name="Chunk Processing",
func=chunk_processing_tool,
description="Processes text chunks and generates summaries."
),
Tool(
name="External Query",
func=external_tool,
description="Fetches additional data to enhance chunk processing."
)
]
# Initialize the agent with defined tools and zero-shot capabilities
agent = initialize_agent(
tools=tools,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
llm=llm,
verbose=True
)
# Step 5: Agentic Chunk Processing Function
def agent_process_chunks(text):
"""Uses the agent to process text chunks and generate a final output."""
# Step 1: Chunking the text into smaller, manageable sections
def chunk_text(text, chunk_size=500):
"""Splits large text into smaller chunks."""
return [text[i:i + chunk_size] for i in range(0, len(text), chunk_size)]
chunks = chunk_text(text)
# Step 2: Process each chunk with the agent
chunk_results = []
for idx, chunk in enumerate(chunks):
print(f"Processing chunk {idx + 1}/{len(chunks)}...")
response = agent.invoke({"input": chunk}) # Process chunk using the agent
chunk_results.append(response['output']) # Collect the chunk result
# Step 3: Combine the chunk results into a final output
final_output = "\n".join(chunk_results)
return final_output
# Step 6: Running the agent on an example large text input
if __name__ == "__main__":
# Example large text content
text_to_process = """
Artificial intelligence (AI) is transforming industries by enabling machines to perform tasks that
previously required human intelligence. From healthcare to finance, AI is driving innovation and improving
efficiency. For instance, in healthcare, AI algorithms assist doctors in diagnosing diseases, interpreting
medical images, and predicting patient outcomes. Meanwhile, in finance, AI helps detect fraud, manage
investments, and automate customer service.
However, the widespread adoption of AI also raises ethical concerns. Issues like privacy invasion,
algorithmic bias, and the potential loss of jobs due to automation are significant challenges. Experts
argue that it's essential to develop AI responsibly to ensure that it benefits society as a whole.
Proper regulations, transparency, and accountability can help address these issues, ensuring that AI
technologies are used for the greater good.
Beyond individual industries, AI is also impacting the global economy. Nations are investing heavily
in AI research and development to maintain a competitive edge. This technological race could redefine
global power dynamics, with countries that excel in AI leading the way in economic and military strength.
Despite the potential for AI to contribute positively to society, its development and application require
careful consideration of ethical, legal, and societal implications.
"""
# Process the text and print the final result
final_result = agent_process_chunks(text_to_process)
print("\nFinal Output:\n", final_result)The above code will generate the following output:
Processing chunk 1/3...
> Entering new AgentExecutor chain...
I should use Chunk Processing to extract the key information from the text provided.
Action: Chunk Processing
Action Input: Artificial intelligence (AI) is transforming industries by enabling machines to perform tasks that previously required human intelligence. From healthcare to finance, AI is driving innovation and improving efficiency. For instance, in healthcare, AI algorithms assist doctors in diagnosing diseases, interpreting medical images, and predicting patient outcomes. Meanwhile, in finance, AI helps detect fraud, manage investments, and automate customer service.Processing chunk:
Artificial intelligence (AI) is transforming industries by enabling machines to perform tasks that previously required human intelligence. From healthcare to finance, AI is driving innovation and improving efficiency. For instance, in healthcare, AI algorithms assist doctors in diagnosing diseases, interpreting medical images, and predicting patient outcomes. Meanwhile, in finance, AI helps detect fraud, manage investments, and automate customer service.
Observation: Artificial intelligence (AI) is revolutionizing various industries by allowing machines to complete tasks that once needed human intelligence. In healthcare, AI algorithms aid doctors in diagnosing illnesses, analyzing medical images, and forecasting patient results. In finance, AI is used to identify fraud, oversee investments, and streamline customer service. AI is playing a vital role in enhancing efficiency and driving innovation across different sectors.
Thought:I need more specific information about the impact of AI in different industries.
Action: External Query
Action Input: Impact of artificial intelligence in healthcare
Observation: External response based on the query: Impact of artificial intelligence in healthcare
Thought:I should now look for information on the impact of AI in finance.
Action: External Query
Action Input: Impact of artificial intelligence in finance
Observation: External response based on the query: Impact of artificial intelligence in finance
Thought:I now have a better understanding of how AI is impacting healthcare and finance.
Final Answer: Artificial intelligence is revolutionizing industries like healthcare and finance by enhancing efficiency, driving innovation, and enabling machines to perform tasks that previously required human intelligence. In healthcare, AI aids in diagnosing diseases, interpreting medical images, and predicting patient outcomes, while in finance, it helps detect fraud, manage investments, and automate customer service.
> Finished chain.
Processing chunk 2/3...
> Entering new AgentExecutor chain...
This question is discussing ethical concerns related to the widespread adoption of AI and the need to develop AI responsibly.
Action: Chunk Processing
Action Input: The text providedProcessing chunk:
The text provided
Observation: I'm sorry, but you haven't provided any text to be summarized. Could you please provide the text so I can assist you with summarizing it?
Thought:I need to provide the text for chunk processing to summarize.
Action: External Query
Action Input: Retrieve the text related to the ethical concerns of AI adoption and responsible development
Observation: External response based on the query: Retrieve the text related to the ethical concerns of AI adoption and responsible development
Thought:Now that I have the text related to ethical concerns of AI adoption and responsible development, I can move forward with chunk processing.
Action: Chunk Processing
Action Input: The retrieved textProcessing chunk:
The retrieved text
Observation: I'm sorry, but it seems like you have not provided any text for me to summarize. Could you please provide the text you would like me to summarize? Thank you!
Thought:I need to ensure that the text related to ethical concerns of AI adoption and responsible development is provided for chunk processing to generate a summary.
Action: External Query
Action Input: Retrieve the text related to the ethical concerns of AI adoption and responsible development
Observation: External response based on the query: Retrieve the text related to the ethical concerns of AI adoption and responsible development
Thought:Now that I have the text related to ethical concerns of AI adoption and responsible development, I can proceed with chunk processing to generate a summary.
Action: Chunk Processing
Action Input: The retrieved textProcessing chunk:
The retrieved text
Observation: I'm sorry, but you haven't provided any text to be summarized. Can you please provide the text so I can help you with the summarization?
Thought:I need to make sure that the text related to ethical concerns of AI adoption and responsible development is entered for chunk processing to summarize.
Action: Chunk Processing
Action Input: Text related to ethical concerns of AI adoption and responsible developmentProcessing chunk:
Text related to ethical concerns of AI adoption and responsible development
Observation: The text discusses the ethical concerns surrounding the adoption of artificial intelligence (AI) and the importance of responsible development. It highlights issues such as bias in AI algorithms, privacy violations, and the potential for autonomous AI systems to make harmful decisions. The text emphasizes the need for transparency, accountability, and ethical guidelines to ensure that AI technologies are developed and deployed in a responsible manner.
Thought:The text provides information on ethical concerns related to AI adoption and responsible development, emphasizing the need for regulation, transparency, and accountability.
Final Answer: The text discusses the ethical concerns surrounding the adoption of artificial intelligence (AI) and the importance of responsible development.
> Finished chain.
Processing chunk 3/3...
> Entering new AgentExecutor chain...
This question seems to be about the impact of AI on the global economy and the potential implications.
Action: Chunk Processing
Action Input: The text providedProcessing chunk:
The text provided
Observation: I'm sorry, but you did not provide any text for me to summarize. Please provide the text that you would like me to summarize.
Thought:I need to provide the text for Chunk Processing to summarize.
Action: External Query
Action Input: Fetch the text about the impact of AI on the global economy and its implications.
Observation: External response based on the query: Fetch the text about the impact of AI on the global economy and its implications.
Thought:Now that I have the text about the impact of AI on the global economy and its implications, I can proceed with Chunk Processing.
Action: Chunk Processing
Action Input: The text about the impact of AI on the global economy and its implications.Processing chunk:
The text about the impact of AI on the global economy and its implications.
Observation: The text discusses the significant impact that artificial intelligence (AI) is having on the global economy. It highlights how AI is revolutionizing industries by increasing productivity, reducing costs, and creating new job opportunities. However, there are concerns about job displacement and the need for retraining workers to adapt to the changing landscape. Overall, AI is reshaping the economy and prompting a shift in the way businesses operate.
Thought:Based on the summary generated by Chunk Processing, the impact of AI on the global economy seems to be significant, with both positive and negative implications.
Final Answer: The impact of AI on the global economy is significant, revolutionizing industries, increasing productivity, reducing costs, creating new job opportunities, but also raising concerns about job displacement and the need for worker retraining.
> Finished chain.
Final Output:
Artificial intelligence is revolutionizing industries like healthcare and finance by enhancing efficiency, driving innovation, and enabling machines to perform tasks that previously required human intelligence. In healthcare, AI aids in diagnosing diseases, interpreting medical images, and predicting patient outcomes, while in finance, it helps detect fraud, manage investments, and automate customer service.
The text discusses the ethical concerns surrounding the adoption of artificial intelligence (AI) and the importance of responsible development.
The impact of AI on the global economy is significant, revolutionizing industries, increasing productivity, reducing costs, creating new job opportunities, but also raising concerns about job displacement and the need for worker retraining.Comparison of Chunking Strategies
To make it easier to understand the different chunking methods, the table below compares fixed-size chunking, recursive chunking, semantic chunking, and agentic chunking. It highlights how each method works, when to use them, and their limitations.
| Chunking Type | Description | Method | Best For | Limitation |
|---|---|---|---|---|
| Fixed-size Chunking | Divides text into equal-sized chunks without regard to content. | Chunks created based on a fixed word or character limit. | Simple, structured text where context continuity is less crucial. | May lose context or split sentences/ideas. |
| Recursive Chunking | Continuously divides text into smaller chunks until it reaches a manageable size. | Hierarchical splitting, breaking down sections further if too large. | Long, complex, or hierarchical documents (e.g., technical manuals). | May still lose context if sections are too broad. |
| Semantic Chunking | Divides text into chunks based on meaning or related themes. | Uses NLP techniques like sentence embeddings to group related content. | Context-sensitive tasks where coherence and topic continuity are essential. | Requires NLP techniques; more complex to implement. |
| Agentic Chunking | Utilizes AI models (like GPT) to autonomously divide content into meaningful sections. | AI-driven segmentation based on the model's comprehension and task-specific context. | Complex tasks where content structure varies, and AI can optimize segmentation. | May be unpredictable and require tuning. |
Conclusion
Chunking strategies and RAG are essential for enhancing LLMs. Chunking aids in simplifying intricate data into smaller, manageable parts, facilitating more effective processing, whereas RAG improves LLMs by incorporating real-time data retrieval within the generation workflow. Collectively, these methods allow LLMs to deliver more precise, context-sensitive replies by merging organized data with lively, current information.
Opinions expressed by DZone contributors are their own.
Comments