DPS and Microservice Architecture
Applying the database-per-service pattern in a microservice environment creates new challenges. The Saga pattern and CQRS can help clear up some of these issues.
Join the DZone community and get the full member experience.
Join For FreeThe CAP Theorem describes three safety properties: data consistency, availability, and node or partition tolerance in distributed systems. In fact, applying the database-per-service pattern in a microservice environment will entail new challenges in managing transactions.
So, what about a two-phase commit? It will affect the cap pairs since it is blocking in nature. First of all, the 2-pc coordinator will present a spoof and will attack the availability node, which is not supported by message brokers or newly released NoSQL databases, etc.
And Saga! Saga will divide the overall transaction into little atomic pieces. Saga focuses on compensating transactions and returning a termination state; it will handle the rollback procedure by running a series of local transactions in reverse order. But how can Saga know which local transition will affect when compensating data? It should have a unit that will manage the process.
There are two basic ways to implement Saga: event-based or command-based.
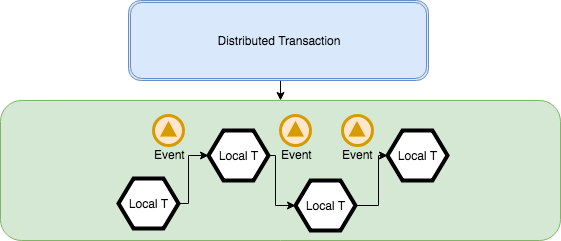
In an event-based implementation, each service will look up and listen to the other's service events. If Service I propagates an event, Service II will catch the event and perform tasks based on the nature of the event.
![Image title]()
Command-based implementation is satisfied by implementing a process manager, which will coordinate the action sequence.
Another challenge is that sometimes service queries need to aggregate data from multiple DB sources, so we go for CQRS and materialized views, which imply more effort and complexity for their implementation.
It is really important to know that the DEPP presents a solution for data privacy, but this pattern will generate more challenges when we manage distributed transactions to be aligned with the cap consistency property and share data between multiple services.
Nowadays, CQRS is the future of the event-based architecture. CQRS is based on breaking the data operations into two types: queries for reading operations and commands for updating the data models. Write and read requests are handled by different objects.
Just to clarify the way the system operates, let's take the example of a relational database log system, a kind of event store from which we can recover state by replaying events.
Let's take another simple example of an intra-transfer funds service in a core banking system from account A to account B in an event-driven architecture.
The accounting model has just three events and balances properties in our example:
Event |
Account |
ID Event |
Amount |
Initialized |
A |
100 |
100 |
| Debited | A |
101 |
40 |
| Credited | A |
102 |
120 |
If we focus on the table above, we will find that it represents the events table. The aggregation of events will present the state of the model at a specific time: Account A's Balance is 180. In fact, we are not a persisting state anymore, but events, and from the events store, we could grab state. But let's think about a real banking system — if we store events for each account, then we will have a huge event table, so we need to save snapshots of the aggregated state.
Even CQRS has its own drawbacks, but before moving forward to more details about CQRS, we will see in the next post an important concept, DDD. Stay tuned!
Opinions expressed by DZone contributors are their own.
Comments