Caching in RavenDB
Caching — what it is, how it is handled in RavenDB, and how you can optimize your database performance with the right caching strategy.
Join the DZone community and get the full member experience.
Join For FreeGenerally speaking, retrieving data from main memory is about four times faster than from a solid state drive, which in turn is about 150 times faster than from a server across the network. These values can vary a lot, but what’s certain is that the source of the data significantly affects the speed of retrieval.
Caching is the process of temporarily storing a copy of retrieved data in a more quickly accessible (lower latency) location, called a cache. It’s used to speed up applications by allowing subsequent requests for the same data to be served from the cache orders of magnitude faster than from the original source.
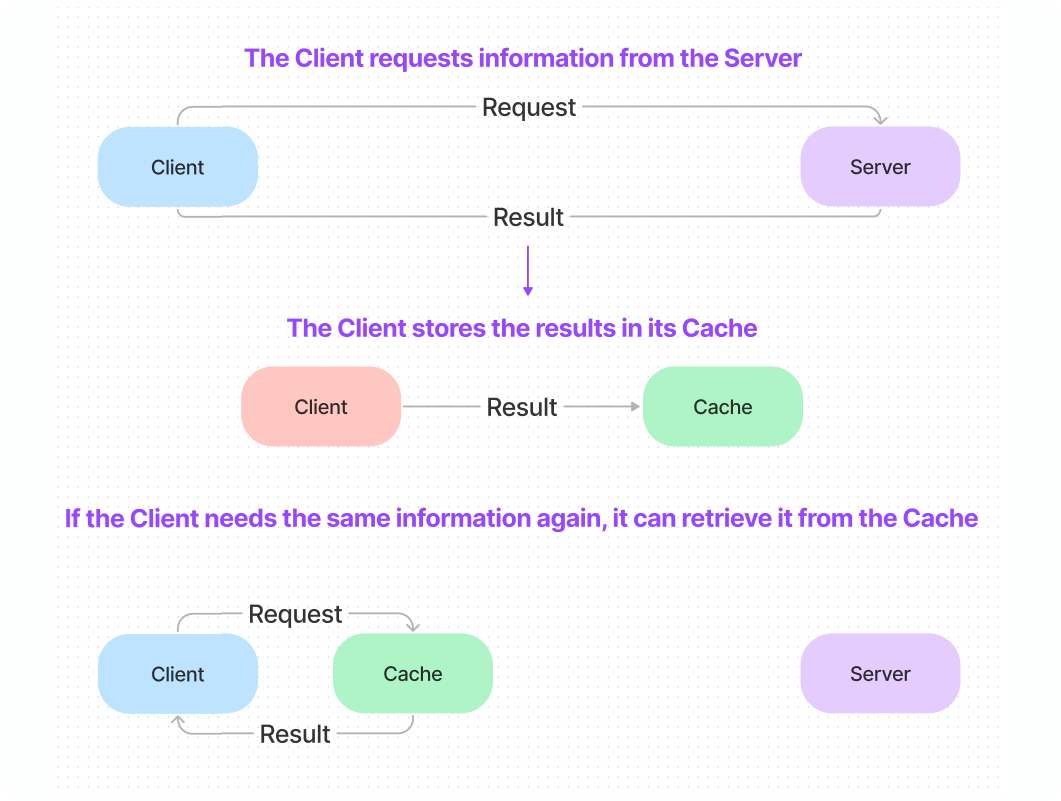
When you load a web page in your browser, you have to request the content of that page from the web server, which takes a relatively long time. The page information is then stored in the browser’s cache, so that when you load the page again (for example when you press the back button) the data can be retrieved from there virtually instantaneously.
Similarly, when an application(client) queries a database(server), the results can be stored in a cache on the client side. The database server can also cache data in its main memory so that requests don’t have to wait for disk I/O. (This is arguably not so much caching as just optimal operating procedure, especially when a database can store a whole data set in memory before any of it is even requested.)
Storing data in a cache is itself relatively simple — the difficulty comes later. The local copy of the data will become inaccurate and obsolete when the corresponding data at the original source is updated, which brings us to the topic of cache invalidation.
Database Cache Invalidation
While storing data is straightforward, deciding when to how long to retain it can be quite a challenge.
There are only two hard things in Computer Science: cache invalidation, naming things and off-by-one errors.
Phil Karlton
When locally stored data no longer matches the corresponding data at the original source, it is said to have become stale. Data that is still current is said to be fresh. Stale data can be anything from application-breaking to not that important depending on the circumstances, and the amount of time data can safely be kept before becoming stale is likewise variable.
Consider the data in a software company’s database:
- The number of purchases made in July 2020 will never change.
- The salary of the company’s copywriter will change every so often.
- The number of active support tickets will change frequently.
In any situation with dynamic data, you’re going to need to refresh the data in your cache at some point — a process called cache invalidation.
Methods of invalidation are:
- Purge – Removes the data from the cache.
- Refresh – Fetches the data from the original source to update the cache’s data.
- Ban – Marks the data in the cache so that when it is requested a call to the original source is made and the latest data is returned to the client and used to update the cache.
But how do you determine how long to keep data in the cache? How do you know when you need to go back to the original source for the most up-to-date version?
There are alternatives to the above methods that provide an answer.
- Time To Live (TTL) – A control such as a counter or a timestamp can be used to dictate the lifespan of cached data. When the time expires the data is cleared from the cache.
- Selective Caching – Rather than storing all results in the cache, this will only retain information that is unlikely to change, or for which freshness is not critical.
- Validation on Request – Whenever cached data is requested, the original source is contacted to query whether or not the data has changed since the last time it was read.
Benefits of Database Caching
Caching makes data access faster, but what does this actually translate to in the context of an application using a database? Here’s a more comprehensive look:
- Faster reads.
- Increased throughput.
- Reduced database load — you only retrieve the data once, not multiple times, so your database is free to do other things.
- Reduced cost, less network usage, less I/O.
- More reliable performance — no network concerns.
- No bottlenecks — the need to retrieve a certain piece of data a large number of times is no longer a burden on the system.
How Databases Handle Caching Data
There are two main approaches to caching data in databases:
- Storing data sets in memory rather than disk on the server side.
- Caching query results on the client side.
Most respectable database systems will offer an in-memory option:
- Oracle has an “In-Memory Database Cache” product option.
- MySQL has a “MEMORY Engine” which you need to enable and configure manually, and which comes with various caveats.
- MongoDB stores working data sets in memory to the extent that is possible and serves queries from there if you have indexes for those queries.
- RavenDB similarly stores your data sets in memory to the extent that is possible and serves queries from there.
Client-side result caching is less commonly implemented:
- Oracle cached query results.
- MySQL had a feature called Query Cache, but they had to remove it due to scalability issues.
- MongoDB doesn’t cache query results.
- RavenDB caches query results.
There is also a strategy for caching outside a database. When a database becomes slow, a common solution is to reach for Redis.
Redis as a Cache
Redis is a fast, in-memory database that is often used as a caching layer. It can be put in front of a data store to speed up common queries and make applications more responsive. Putting a database in front of another database might seem unintuitive – you’re just adding extra steps – but it can be cheaper and easier than engaging your developers to spend 100s of hours on development, optimization, and refactoring on your original database.
The relational database model was designed back in the 70s when data was highly-structured and fit on floppy disks. Trying to organize and store large volumes of unstructured or semi-structured data into a relational format is difficult, and can require a great deal of expertise, time, and work to optimize. As a result, Redis is commonly used for these databases, so much so that it’s often included in projects before it’s even necessary.
Relational databases aren’t the only guilty party, however. Any database trying to do a job it isn’t suited for may benefit from Redis. For example, MongoDB’s master-slave architecture allows only one node to accept writes and then distribute accepted data to other nodes. This can result in poor performance at scale and Redis can be used to alleviate the problem.
What to Look For in a Database
Caching is a deep and complex topic with many thick textbooks written about it. It’s really useful, but you really don’t want to have to implement it yourself.
Ideally, a database system should have automatic caching behavior built in on the client-side and server-side, while allowing enough optional customization to optimize for specific use cases. (A form of caching less concerned with data freshness might greatly improve performance in one system while completely breaking another.)
Furthermore, a database should be performant enough and scale well enough that it doesn’t need a caching layer in front of it.
With that in mind, let’s look at how RavenDB handles caching.
Caching in RavenDB
RavenDB is a fast, distributed document database designed for OLTP workloads. It automates many of the normal optimization processes like indexing, compression, and of course, caching. It should be performant enough at any scale that it never needs an external caching layer like Redis.
As mentioned before, RavenDB stores your working data set in memory whenever possible on the server side. We don’t really need to think about this — it’s all automated and speeds up your queries without any user involvement.
Client-side caching is worth diving into a bit deeper.
Communication between your client application and RavenDB is via HTTP requests and is managed through a client API object called the Document Store.
RavenDB takes advantage of existing HTTP caching functionality and Etags for Validation on Request.
HTTP Caching and Etags
The most common type of caching used over the internet is HTTP caching. Without going into too much detail about how HTTP works, basically, it is a text-based protocol for transferring data over a network.
HTTP requests and responses have header fields which are lists of strings sent along with the data. Header fields can have all sorts of purposes, some of which are caching.
ETags, (short for Entity Tags) are HTTP response headers. There are unique identifiers for a retrieved resource. If that resource changes the ETag will be different.
Whenever a GET request is made that matches a previous request in the cache, the stored ETag for that request is sent to the server. If the ETag at the server is the same, the server will simply respond that the resource hasn’t changed (304 Not Modified). In that case, the client will know the locally stored data is still fresh and will use it as is. If the ETag is different on the server, the server will send the fresh data along with the new ETag.

HTTP Caching Specifics in RavenDB
In RavenDB, almost all read operations generate an ETag, not just queries. Loading a document for example will also generate an ETag. Some things aren’t cached, such as information that will always be different like system stats and debug endpoints, and attachments, which can be too large for the cache and are handled entirely differently.
All requests to the server and responses are cached (already parsed) in the Document Store. All sessions using the same Document Store will share the same cache.
When the server gets a request with an ETag, it follows an optimized code path to check if the results of the request have changed.
RavenDB handles client-side caching automatically behind the scenes. From the user’s point of view it’s completely invisible, but knowing how it works does in some cases allow you to take further advantage of it.
For example, any query using DateTime.Now will generally be unique and cannot be optimized by caching on the client. However, if you use DateTime.Today any identical query from the same day will yield the same results. If you need better than a daily granularity, using the current hour or minute will also suffice to give your query the option to benefit from caching.
The default size of the cache depends on your system specifications, and the maximum size can be changed as required. Automatic caching can be disabled for a session or globally, forcing all requests to go to the server.
Aggressive Caching
The HTTP caching behavior described above ensures that the data you get is fresh. In cases where the freshness of the data isn’t absolutely critical, RavenDB offers another option that doesn’t require a trip to the server at read time. This option is called Aggressive Caching and is unique to RavenDB.
When Aggressive mode is activated, whenever a request is made for the first time, the client opens a connection with the server and tells the server to let it know if any changes to the data have been made. (Note: the notification is sent for any change on the server, not just changes to previously requested data.)
When the client makes a repeat request for data, if the server hasn’t reported any changes since the information was last requested, the client will use the cached data without contacting the server.
If the server has reported a change, and the local copy of that information is older than that notification, then that request will follow RavenDB’s regular caching behavior and the timestamp on the cached data will then be updated.
In short: Aggressive mode allows the database to invalidate the cache on the client side.
This allows faster queries while still ensuring that you get the most up-to-date data. So why not have it on by default? Because the data on the server may have changed, but the client may not have yet been informed. With regular RavenDB client caching, there is no chance you will get out-of-date info because you will always be verifying the cache’s data first. You need to specifically activate Aggressive mode because it creates the possibility that you might use stale data.
Aggressive mode can be turned on for a session or globally. It can be set to last indefinitely or for a limited amount of time, and it can be disabled at any time. For more information, you can see the documentation here.
Caching Behavior in Cluster
RavenDB’s recommended deployment is in a cluster of at least 3 nodes to ensure high availability. Different nodes have different URLs, so the same request will be stored separately in the cache for separate servers. There is no cross-node caching, but in practice, you’re typically going to be hitting the same server with your requests anyway because of the way RavenDB distributes requests across your cluster.
In summary:
Caching in RavenDB is designed to automatically optimize data retrieval on both the client and server. Configuration options and the choice of aggressive caching allow you to customize caching behavior to squeeze even more performance out of your system.
Published at DZone with permission of Chris Balnave. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments