Better Search Results Through Intelligent Chunking and Metadata Integration
Chunking is an important, but underrated, aspect of LLM-based content retrieval, and effective management of It will yield world-class results.
Join the DZone community and get the full member experience.
Join For FreeOften, the knowledge bases over which we develop an LLM-based retrieval application contain a lot of data in various formats. To provide the LLM with the most relevant context to answer the question specific to a section within the knowledge base, we rely on chunking the text within the knowledge base and keeping it handy.
Chunking
Chunking is the process of slicing text into meaningful units to improve information retrieval. By ensuring each chunk represents a focused thought or idea, chunking assists in maintaining the contextual integrity of the content.
In this article, we will look at 3 aspects of chunking:
- How poor chunking leads to less relevant results
- How good chunking leads to better results
- How good chunking with metadata leads to well-contextualized results
To effectively showcase the importance of chunking, we will take the same piece of text, apply 3 different chunking methodologies to it, and examine how information is retrieved based on the query.
Chunk and Store to Qdrant
Let us look at the following code which shows three different ways to chunk the same text.
import qdrant_client
from qdrant_client.models import PointStruct, Distance, VectorParams
import openai
import yaml
# Load configuration
with open('config.yaml', 'r') as file:
config = yaml.safe_load(file)
# Initialize Qdrant client
client = qdrant_client.QdrantClient(config['qdrant']['url'], api_key=config['qdrant']['api_key'])
# Initialize OpenAI with the API key
openai.api_key = config['openai']['api_key']
def embed_text(text):
print(f"Generating embedding for: '{text[:50]}'...") # Show a snippet of the text being embedded
response = openai.embeddings.create(
input=[text], # Input needs to be a list
model=config['openai']['model_name']
)
embedding = response.data[0].embedding # Access using the attribute, not as a dictionary
print(f"Generated embedding of length {len(embedding)}.") # Confirm embedding generation
return embedding
# Function to create a collection if it doesn't exist
def create_collection_if_not_exists(collection_name, vector_size):
collections = client.get_collections().collections
if collection_name not in [collection.name for collection in collections]:
client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=vector_size, distance=Distance.COSINE)
)
print(f"Created collection: {collection_name} with vector size: {vector_size}") # Collection creation
else:
print(f"Collection {collection_name} already exists.") # Collection existence check
# Text to be chunked which is flagged for AI and Plagiarism but is just used for illustration and example.
text = """
Artificial intelligence is transforming industries across the globe. One of the key areas where AI is making a significant impact is healthcare. AI is being used to develop new drugs, personalize treatment plans, and even predict patient outcomes. Despite these advancements, there are challenges that must be addressed. The ethical implications of AI in healthcare, data privacy concerns, and the need for proper regulation are all critical issues. As AI continues to evolve, it is crucial that these challenges are not overlooked. By addressing these issues head-on, we can ensure that AI is used in a way that benefits everyone.
"""
# Poor Chunking Strategy
def poor_chunking(text, chunk_size=40):
chunks = [text[i:i + chunk_size] for i in range(0, len(text), chunk_size)]
print(f"Poor Chunking produced {len(chunks)} chunks: {chunks}") # Show chunks produced
return chunks
# Good Chunking Strategy
def good_chunking(text):
import re
sentences = re.split(r'(?<=[.!?]) +', text)
print(f"Good Chunking produced {len(sentences)} chunks: {sentences}") # Show chunks produced
return sentences
# Good Chunking with Metadata
def good_chunking_with_metadata(text):
chunks = good_chunking(text)
metadata_chunks = []
for chunk in chunks:
if "healthcare" in chunk:
metadata_chunks.append({"text": chunk, "source": "Healthcare Section", "topic": "AI in Healthcare"})
elif "ethical implications" in chunk or "data privacy" in chunk:
metadata_chunks.append({"text": chunk, "source": "Challenges Section", "topic": "AI Challenges"})
else:
metadata_chunks.append({"text": chunk, "source": "General", "topic": "AI Overview"})
print(f"Good Chunking with Metadata produced {len(metadata_chunks)} chunks: {metadata_chunks}") # Show chunks produced
return metadata_chunks
# Store chunks in Qdrant
def store_chunks(chunks, collection_name):
if len(chunks) == 0:
print(f"No chunks were generated for the collection '{collection_name}'.")
return
# Generate embedding for the first chunk to determine vector size
sample_text = chunks[0] if isinstance(chunks[0], str) else chunks[0]["text"]
sample_embedding = embed_text(sample_text)
vector_size = len(sample_embedding)
create_collection_if_not_exists(collection_name, vector_size)
for idx, chunk in enumerate(chunks):
text = chunk if isinstance(chunk, str) else chunk["text"]
embedding = embed_text(text)
payload = chunk if isinstance(chunk, dict) else {"text": text} # Always ensure there's text in the payload
client.upsert(collection_name=collection_name, points=[
PointStruct(id=idx, vector=embedding, payload=payload)
])
print(f"Chunks successfully stored in the collection '{collection_name}'.")
# Execute chunking and storing separately for each strategy
print("Starting poor_chunking...")
store_chunks(poor_chunking(text), "poor_chunking")
print("Starting good_chunking...")
store_chunks(good_chunking(text), "good_chunking")
print("Starting good_chunking_with_metadata...")
store_chunks(good_chunking_with_metadata(text), "good_chunking_with_metadata")
The above code does the following:
embed_textmethod takes in the text, generates embedding by using the OpenAI embedding model, and returns the embedding generated.- Initializes a text string that is used for chunking and later content retrieval
- Poor chunking strategy: Splits text into chunks of 40 characters each
- Good chunking strategy: Splits text based on sentences to obtain a more meaningful context
- Good chunking strategy with metadata: Adds appropriate metadata to sentence-level chunks
- Once embeddings are generated for the chunks, they are stored in corresponding collections in Qdrant Cloud.
Keep in mind the poor chunks are created only to showcase how poor chunking impacts retrieval.
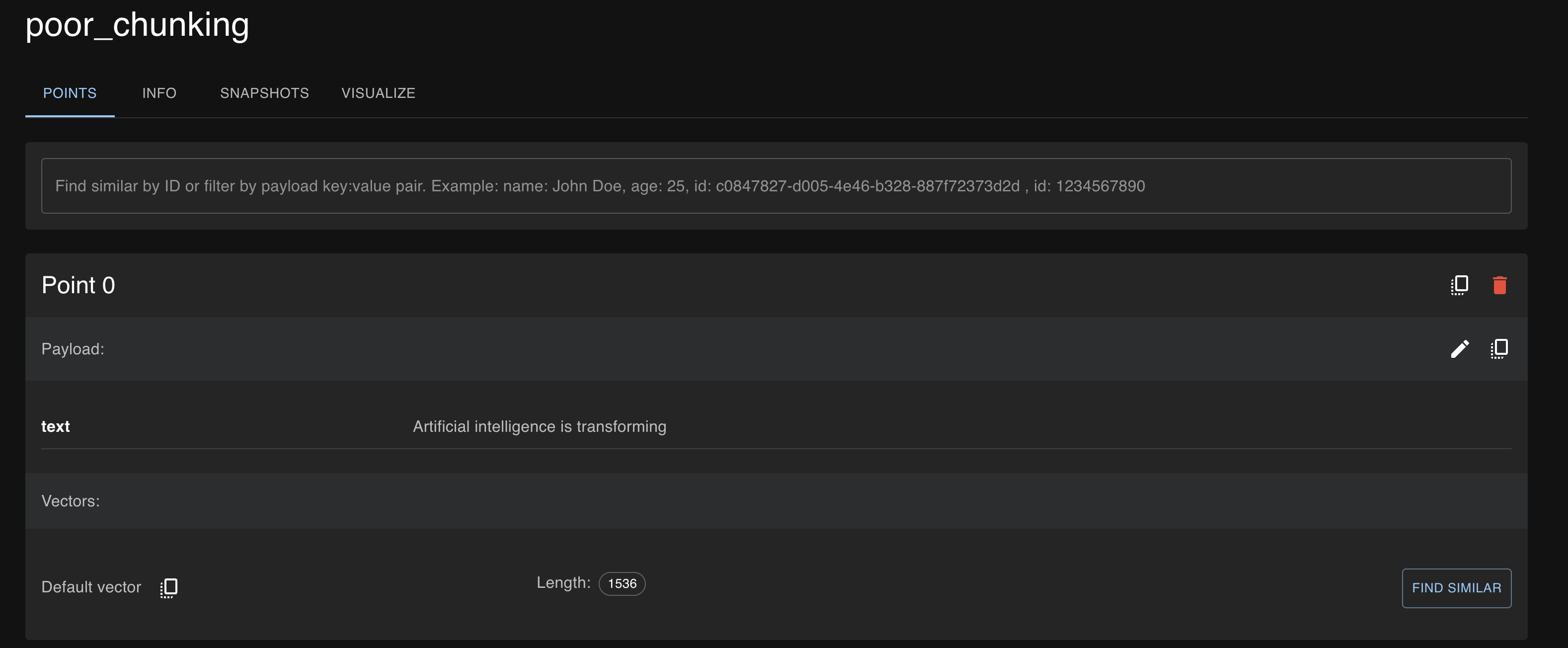
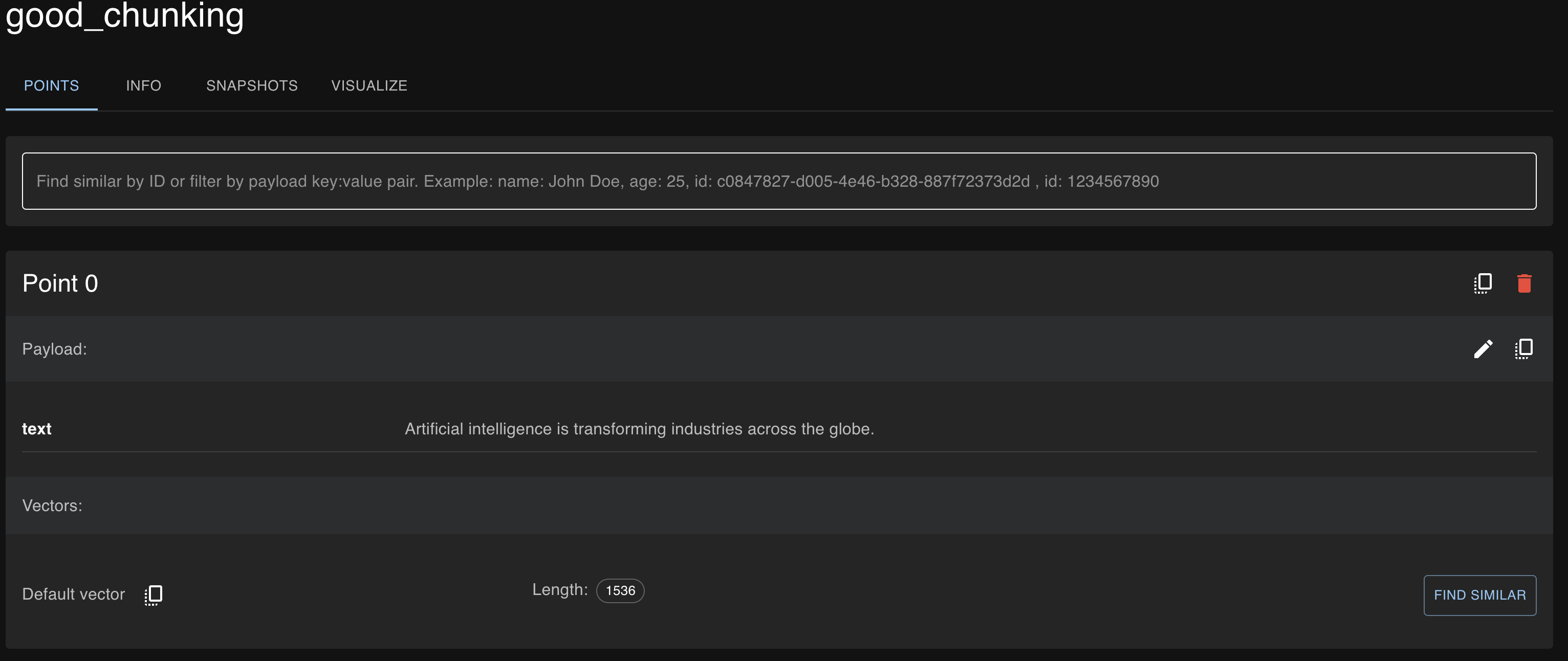
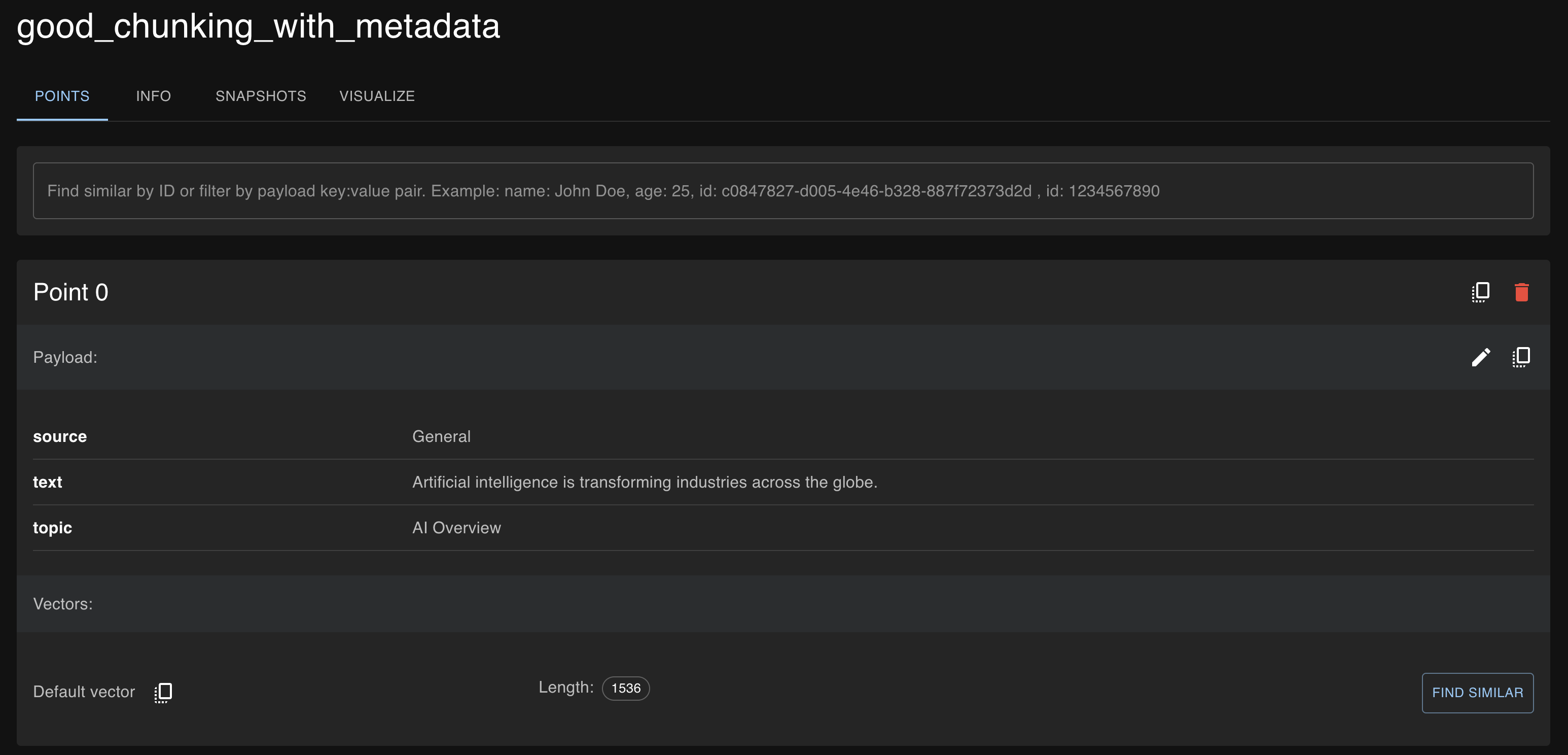
Below are the screenshots from Qdrant Cloud for the chunks, where you can see metadata was added to the sentence-level chunks to indicate the source and topic.
Retrieval Results Based on Chunking Strategy
Now let us write some code to retrieve the content from Qdrant Vector DB based on a query.
import qdrant_client
import openai
import yaml
# Load configuration
with open('config.yaml', 'r') as file:
config = yaml.safe_load(file)
# Initialize Qdrant client
client = qdrant_client.QdrantClient(config['qdrant']['url'], api_key=config['qdrant']['api_key'])
# Initialize OpenAI with the API key
openai.api_key = config['openai']['api_key']
def embed_text(text):
response = openai.embeddings.create(
input=[text], # Ensure input is a list of strings
model=config['openai']['model_name']
)
# Correctly access the embedding data
embedding = response.data[0].embedding # Access using the attribute, not as a dictionary
return embedding
# Define the query
query = "ethical implications of AI in healthcare"
query_embedding = embed_text(query)
# Function to perform retrieval and print results
def retrieve_and_print(collection_name):
result = client.search(
collection_name=collection_name,
query_vector=query_embedding,
limit=3
)
print(f"\nResults from '{collection_name}' collection for the query: '{query}':")
if not result:
print("No results found.")
return
for idx, res in enumerate(result):
if 'text' in res.payload and res.payload['text']:
print(f"Result {idx + 1}:")
print(f" Text: {res.payload['text']}")
print(f" Source: {res.payload.get('source', 'N/A')}")
print(f" Topic: {res.payload.get('topic', 'N/A')}")
else:
print(f"Result {idx + 1}:")
print(" No relevant text found for this chunk. It may be too fragmented or out of context to match the query effectively.")
# Execute retrieval and provide appropriate explanations
retrieve_and_print("poor_chunking")
retrieve_and_print("good_chunking")
retrieve_and_print("good_chunking_with_metadata")
The above code does the following:
- Defines a query and generates the embedding for the query
- The search query is set to
"ethical implications of AI in healthcare". - The
retrieve_and_printfunction searches the particular Qdrant collection and retrieves the top 3 vectors closest to the query embedding.
Now let us look at the output:
python retrieval_test.py
Results from 'poor_chunking' collection for the query: 'ethical implications of AI in healthcare':
Result 1:
Text: . The ethical implications of AI in heal
Source: N/A
Topic: N/A
Result 2:
Text: ant impact is healthcare. AI is being us
Source: N/A
Topic: N/A
Result 3:
Text:
Artificial intelligence is transforming
Source: N/A
Topic: N/A
Results from 'good_chunking' collection for the query: 'ethical implications of AI in healthcare':
Result 1:
Text: The ethical implications of AI in healthcare, data privacy concerns, and the need for proper regulation are all critical issues.
Source: N/A
Topic: N/A
Result 2:
Text: One of the key areas where AI is making a significant impact is healthcare.
Source: N/A
Topic: N/A
Result 3:
Text: By addressing these issues head-on, we can ensure that AI is used in a way that benefits everyone.
Source: N/A
Topic: N/A
Results from 'good_chunking_with_metadata' collection for the query: 'ethical implications of AI in healthcare':
Result 1:
Text: The ethical implications of AI in healthcare, data privacy concerns, and the need for proper regulation are all critical issues.
Source: Healthcare Section
Topic: AI in Healthcare
Result 2:
Text: One of the key areas where AI is making a significant impact is healthcare.
Source: Healthcare Section
Topic: AI in Healthcare
Result 3:
Text: By addressing these issues head-on, we can ensure that AI is used in a way that benefits everyone.
Source: General
Topic: AI Overview
The output for the same search query varies depending on the chunking strategy implemented.
- Poor chunking strategy: The results here are less relevant, as you can notice, and that is because the text was split into small, arbitrary chunks.
- Good chunking strategy: The results here are more relevant because the text was split into sentences, preserving the semantic meaning.
- Good chunking strategy with metadata: The results here are most accurate because the text was thoughtfully chunked and enhanced using metadata.
Inference From the Experiment
- Chunking needs to be carefully strategized, and the chunk size should not be too small or too big.
- An example of poor chunking is when the chunks are too small, cutting off sentences in unnatural places, or too big, with multiple topics included in the same chunk, making it very confusing for retrieval.
- The whole idea of chunking revolves around the concept of providing better context to the LLM.
- Metadata massively enhances properly structured chunking by providing extra layers of context. For example, we have added source and topic as metadata elements to our chunks.
- The retrieval system benefits from this additional information. For example, if the metadata indicates that a chunk belongs to the "Healthcare Section," the system can prioritize these chunks when a query related to healthcare is made.
- By improving upon chunking, the results can be structured and categorized. If the query matches multiple contexts within the same text, we can identify which context or section the information belongs to by looking at the metadata for the chunks.
Keep these strategies in mind and chunk your way to success in LLM-based search applications.
Opinions expressed by DZone contributors are their own.
Comments